

昨天我們分別在 Read committed 以及 Repeatable read 觀察了 Non Repeatable Read 以及 Phantom Read 的變化。今天來看看第三種,也就是最後一個 Serialization Anomaly。
這種異常發生於兩個並行的 transaction 各自讀取初始的資料,並根據這些資料進行寫入,最終卻導致整體資料狀態違反了應用程式的業務邏輯。SERIALIZABLE 是唯一能完全防止此類異常的隔離層級,它能確保並行的結果,會等同於這些交易以某種順序依序執行。
import psycopg2
from psycopg2 import sql, extensions
import time
import threading
# 建立兩個獨立的連線
conn1 = psycopg2.connect(dbname="testdb", user="user", password="password")
conn2 = psycopg2.connect(dbname="testdb", user="user", password="password")
# 設定兩個連線的隔離層級為 READ COMMITTED
conn1.set_isolation_level(extensions.ISOLATION_LEVEL_REPEATABLE_READ)
conn2.set_isolation_level(extensions.ISOLATION_LEVEL_REPEATABLE_READ)
print("Isolation level for conn1:", conn1.isolation_level)
print("Isolation level for conn2:", conn2.isolation_level)
| Category | Amount |
|---|---|
| 1 | 10 |
| 1 | 20 |
| 2 | 100 |
| 2 | 200 |
cur1 = conn1.cursor()
cur2 = conn2.cursor()
cur1.execute("DROP TABLE IF EXISTS accounts")
cur1.execute(
"""
CREATE TABLE orders (
category INTEGER,
amount INTEGER
)
"""
)
cur1.execute("INSERT INTO orders VALUES (1, 10), (1, 20), (2, 100), (2, 200)")
conn1.commit()
開始模擬情境: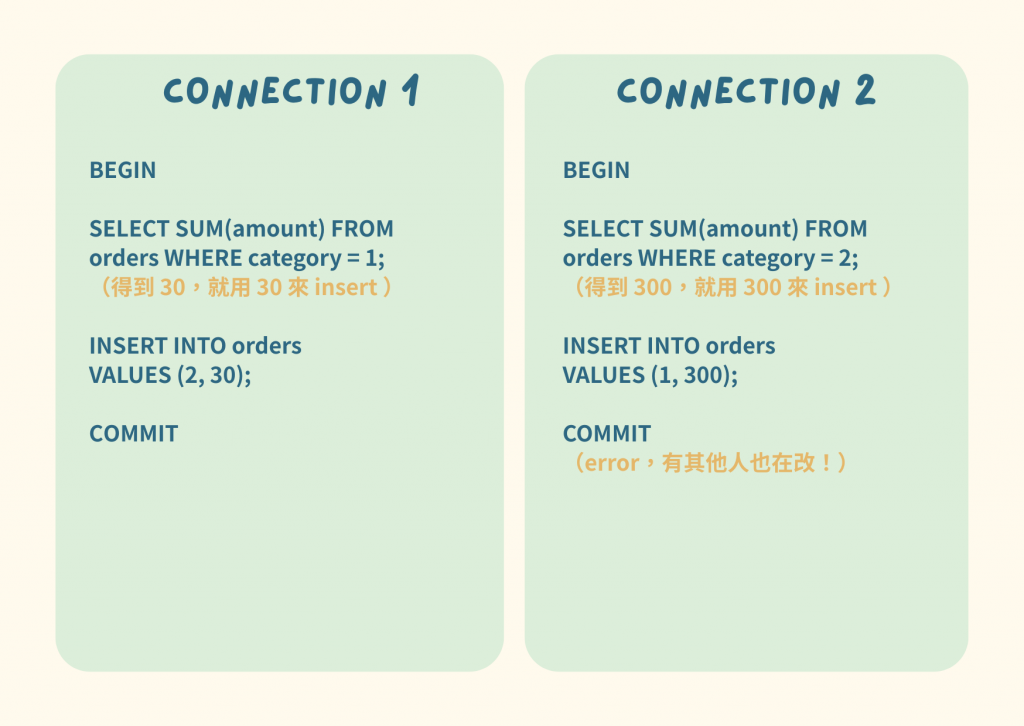
def transaction1():
print("Transaction 1 started.")
cur1.execute("BEGIN")
# 讀取 category 1 的總金額
cur1.execute("SELECT sum(amount) FROM orders WHERE category = 1")
initial_balance_category1 = cur1.fetchone()[0]
print(f"Transaction 1 Read total amount for category 1: {initial_balance_category1}")
# 寫入一筆新的訂單,金額為 category 1 的總金額
cur1.execute("INSERT INTO orders (category, amount) VALUES (%s, %s)", (2, initial_balance_category1))
print(f"Transaction 1 Inserting new order for category 2 with amount: {initial_balance_category1}")
time.sleep(2)
conn1.commit()
print("Transaction 1 committed.")
def transaction2():
print("Transaction 2 started.")
cur2.execute("BEGIN")
# 讀取 category 2 的總金額
cur2.execute("SELECT sum(amount) FROM orders WHERE category = 2")
initial_balance_category2 = cur2.fetchone()[0]
print(f"Transaction 2 Read total amount for category 2: {initial_balance_category2}")
# 寫入一筆新的訂單,其金額為 category 2 的總金額的負數
cur2.execute("INSERT INTO orders (category, amount) VALUES (%s, %s)", (1, initial_balance_category2))
print(f"Transaction 2 Inserting new order for category 1 with amount: {initial_balance_category2}")
time.sleep(2)
conn2.commit()
print("Transaction 2 committed.")
# 同時執行
t1 = threading.Thread(target=transaction1)
t2 = threading.Thread(target=transaction2)
t1.start()
t2.start()
t1.join()
t2.join()
# 檢查最終結果
cur1.execute("SELECT category, amount FROM orders")
final_orders = cur1.fetchall()
print("\nFinal state of accounts:")
for category, amount in final_orders:
print(f"Category {category}: {amount}")
# --- Clean up ---
cur1.execute("DROP TABLE orders")
conn1.commit()
cur1.close()
cur2.close()
conn1.close()
conn2.close()
得到的結果是各自查到了原本的 30 和 300,因此 Category 1 新增 30,Category 2 新增 300。
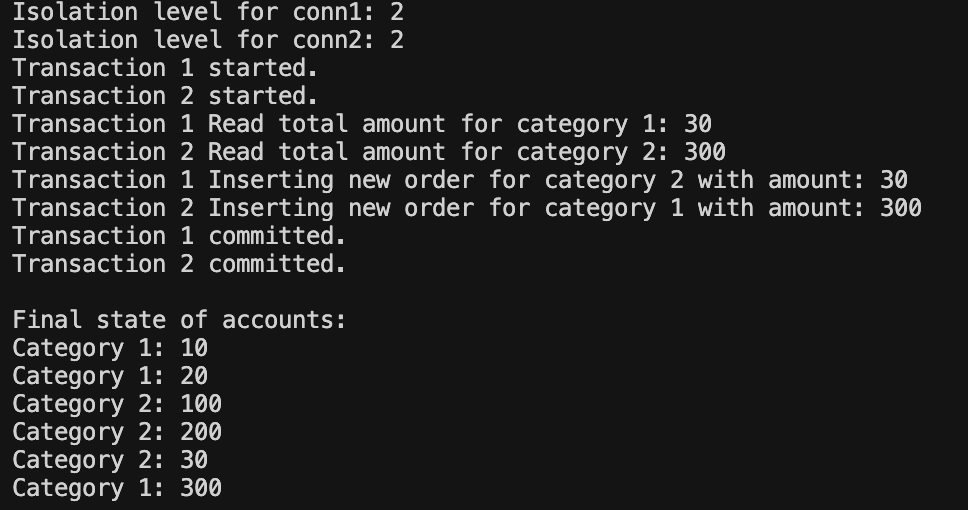
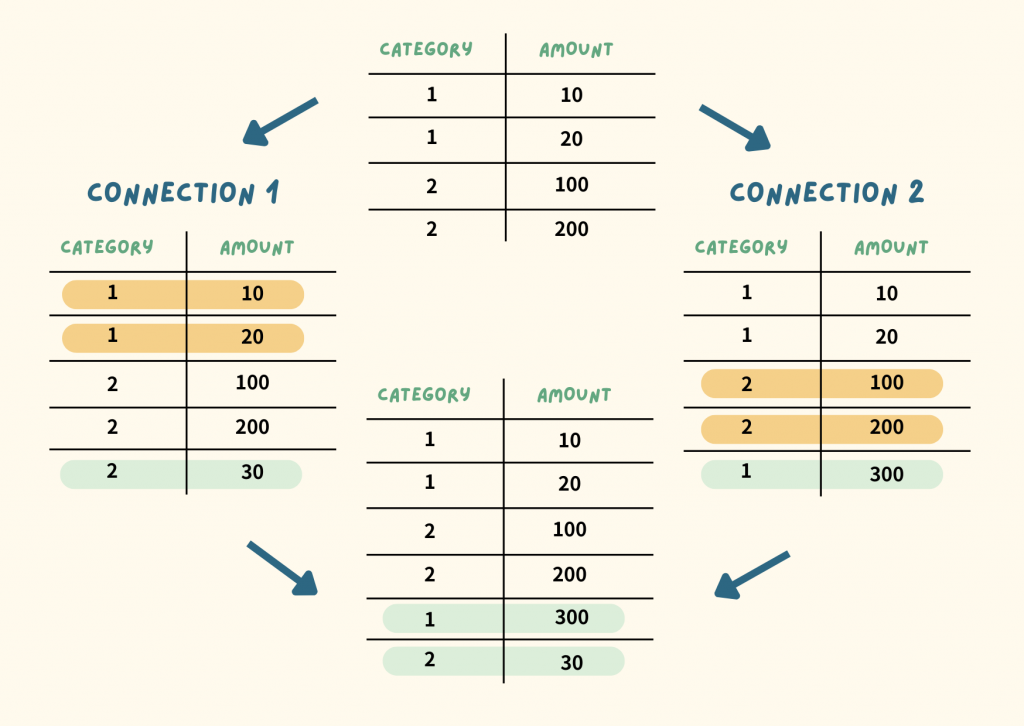
這兩個 transaction 在讀取時,都只讀取到自己提交前的資料快照,因此他們都認為自己的操作沒有問題。但如同 Day 19 提到的,假設是「Connection 1 先執行 Connection 2 後執行」,或是「Connection 2 先執行 Connection 1 後執行」,都沒辦法再還原這個情境。
A. Connection 1 先執行,Connection 2 後執行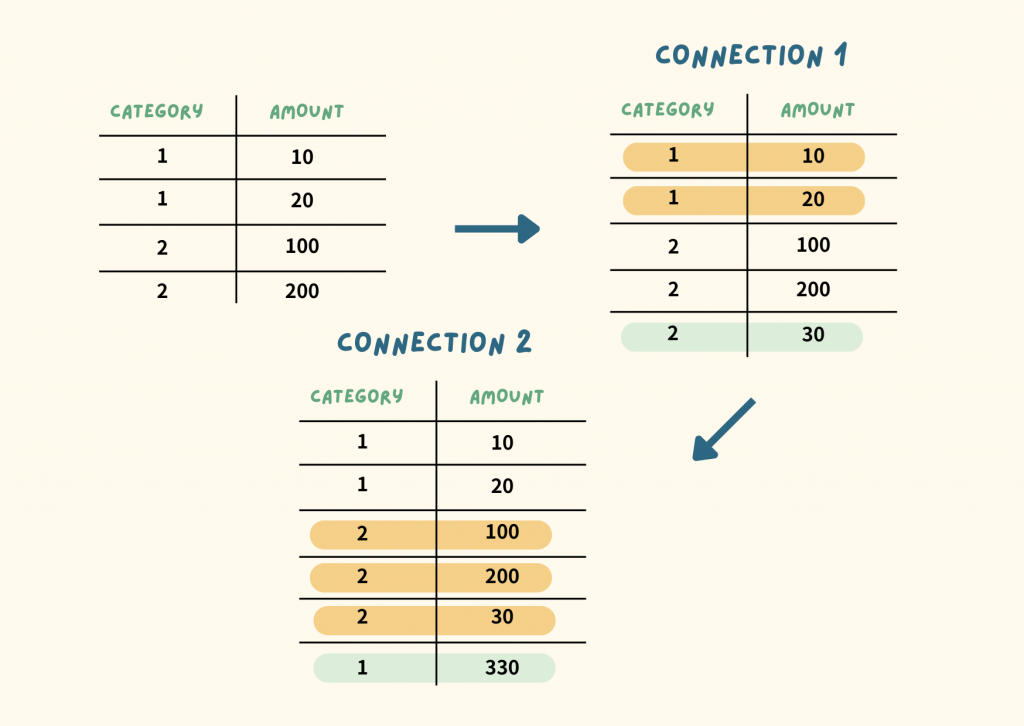
B. Connection 2 先執行,Connection 1 後執行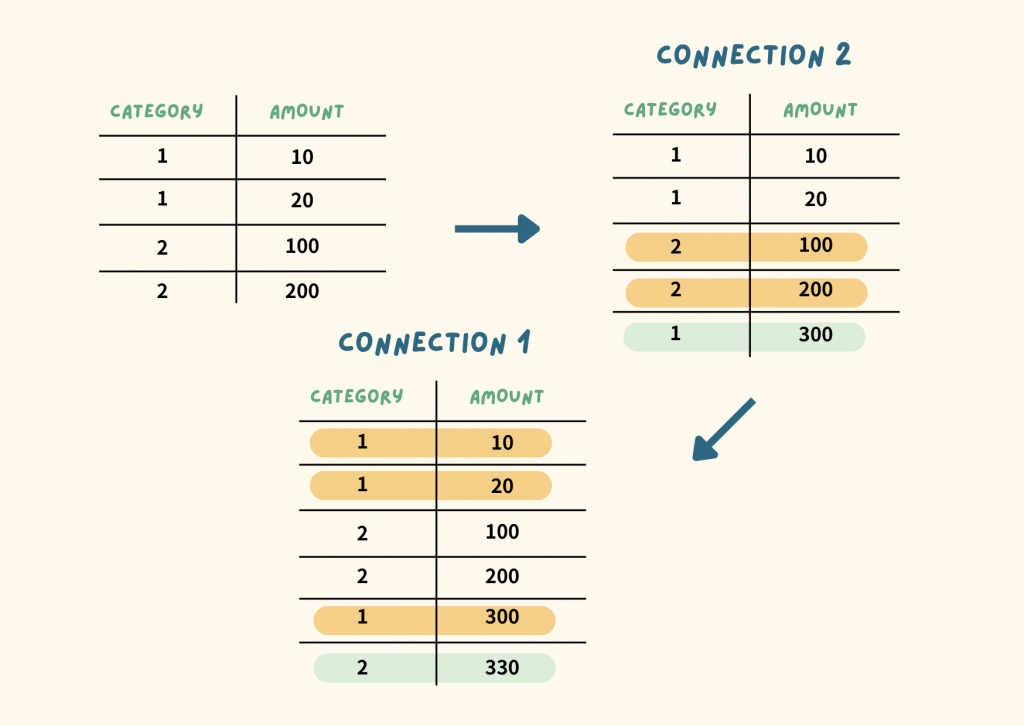
要解決這個問題,我們需要將 Isolation Level 提升到 SERIALIZABLE。
conn1.set_isolation_level(extensions.ISOLATION_LEVEL_SERIALIZABLE)
conn2.set_isolation_level(extensions.ISOLATION_LEVEL_SERIALIZABLE)
使用 SERIALIZABLE 重新跑一次,其中一個 transaction 會成功,而另一個 transaction 則會失敗並出線 SerializationFailure 的錯誤。
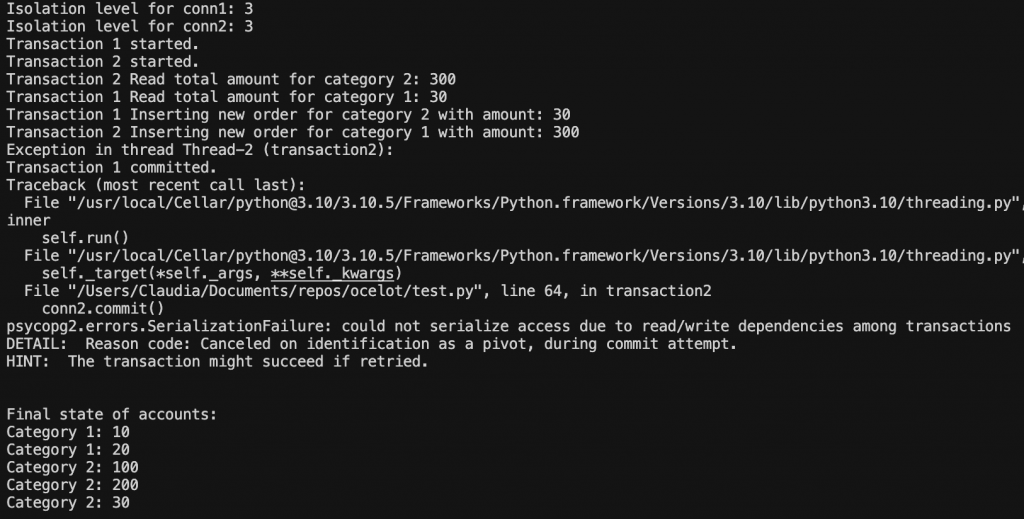
因此 PostgreSQL 在 SERIALIZABLE 防止資料不一致的方法,就是強制一個 transaction 失敗,以確保資料的最終狀態與任何一種依序執行的結果一致。
https://www.postgresql.org/docs/9.5/transaction-iso.html

 iThome鐵人賽
iThome鐵人賽