在資料庫管理中,索引是一個不可忽視的重要工具。它能大幅提升查詢效能,讓資料庫能以更快的速度搜尋特定資料,然而,索引的使用也伴隨著系統額外的負擔,因此必須謹慎使用。接下來將會介紹如何使用索引,以及有哪些不同的索引。
假如使用下面 SQL 產生一百萬筆的假資料。
CREATE TABLE logs (
id SERIAL PRIMARY KEY,
timestamp TIMESTAMP NOT NULL,
level VARCHAR(10) NOT NULL,
message TEXT NOT NULL
);
DO $$
DECLARE
log_levels TEXT[] := ARRAY['INFO', 'DEBUG', 'WARN', 'ERROR'];
log_messages TEXT[] := ARRAY[
'User logged in successfully',
'System startup completed',
'Database connection established',
'Configuration file loaded',
'User session timeout',
'File not found: config.yml',
'Permission denied for user: guest',
'API request received',
'Cache cleared successfully',
'Unexpected null value encountered',
'Server shutting down',
'Memory usage exceeded threshold',
'Scheduled task executed',
'Invalid input format',
'Failed to send email notification'
];
i INTEGER;
BEGIN
FOR i IN 1..1000000 LOOP
INSERT INTO logs (timestamp, level, message)
VALUES (
NOW() - (random() * INTERVAL '365 days'), -- 隨機生成過去一年的時間
log_levels[FLOOR(random() * 4 + 1)::INTEGER], -- 隨機選擇日誌級別
log_messages[FLOOR(random() * array_length(log_messages, 1) + 1)::INTEGER] -- 隨機選擇日誌訊息
);
END LOOP;
END $$;
如果使用下面 query 把 level 是 ERROR 的 log 撈出來,會花費0.317秒。
SELECT * FROM logs WHERE level = 'ERROR'

接著針對 level 這個欄位加上索引。
CREATE INDEX logs_level_index ON logs (level);
然後再次 query 出 level 是 ERROR 的 log,可以發現加上索引之後,只花費0.191秒。
減少搜尋的時間,就是加入索引的最大優點。當然,索引也並非沒有缺點,太多索引會影響新增和更新的效能,所以也不能濫用,不使用索引時,要記得移除。
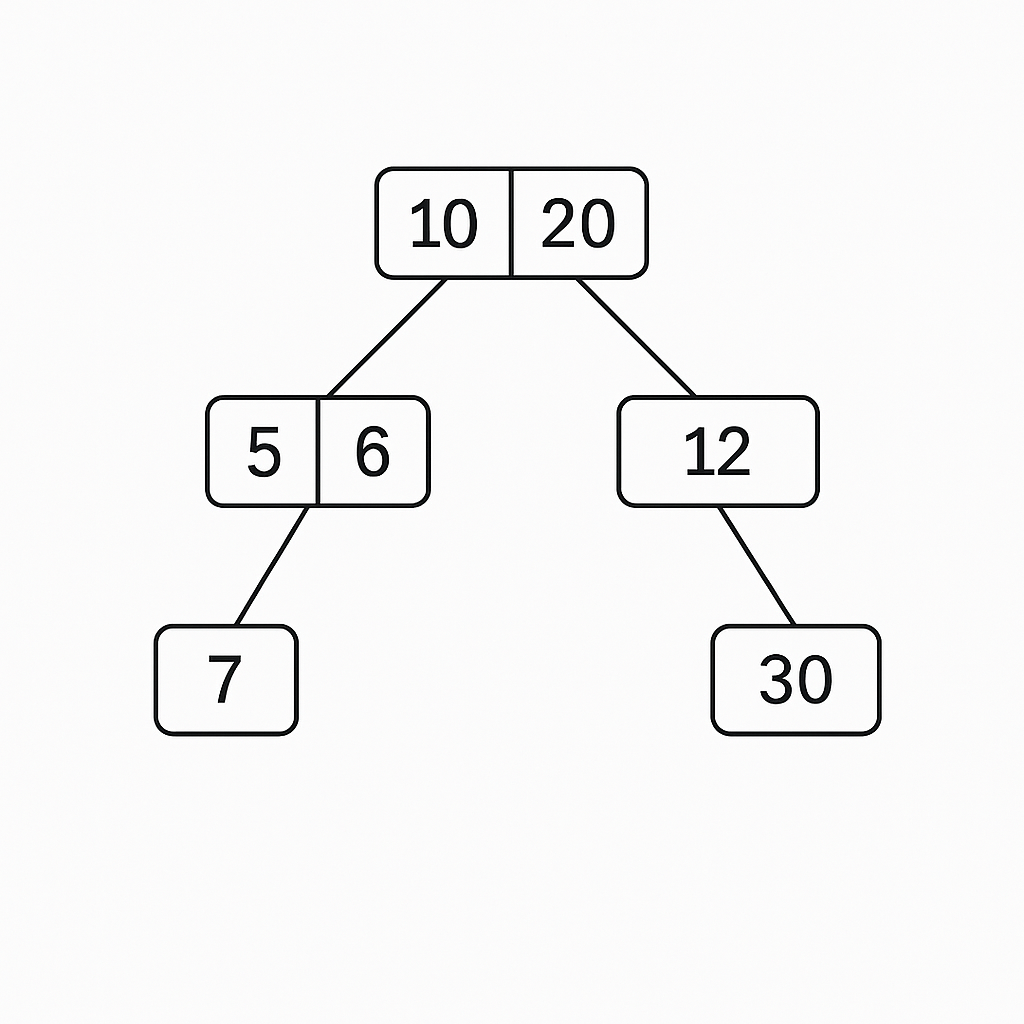
當我們建立索引的時候,資料庫會根據索引的欄位對所有資料進行掃描,並且依據指定的索引類型,為這些資料生成對應的數據結構,使查詢的時候,可以加快搜尋資料的速度,例如使用 B-Tree 這個索引類型,資料庫會依照 B-Tree 演算法去產生資料結構,像是下面的範例。
當我們使用 WHERE 條件要找該欄位為 6 的那筆資料時,就可以快速地透過 B-Tree 的結構找到對應的資料。當然,如果不使用 WHERE 或其他條件搜尋,而是每次都把所有資料撈出來,建立索引就對查詢沒有幫助了。
而當有新的資料被新增進來,資料庫需要對現有的資料結構進行調整,以增加查詢的速度,這也是為什麼前面強調不使用索引時,也要記得移除的原因。