繼昨天說的,下載完比賽資料後,第一步最重要的並不是立刻開始建模,而是先充分理解比賽的任務目標、評分方式以及資料型態。今天這篇文章,我會帶大家一步步認識 Binary Classification with a Bank Dataset 這場比賽,快跟上我的腳步一起實作吧!
每次進入一個 Kaggle 比賽,我都會先看 Overview 的部分。這裡通常會簡單說明比賽的目的、資料來源與我們的任務。
如果有人很擔心英文不好看不懂,除了用google翻譯、請 AI 幫忙,其實還有一個很好用的小工具:沉浸式翻譯,能幫你即時把英文頁面翻成中文。上網搜尋:沉浸式翻譯,加入擴充功能就可以使用囉。還是不太清楚的話也可以到YouTube搜尋:沉浸式翻譯,也會有教學影片喔!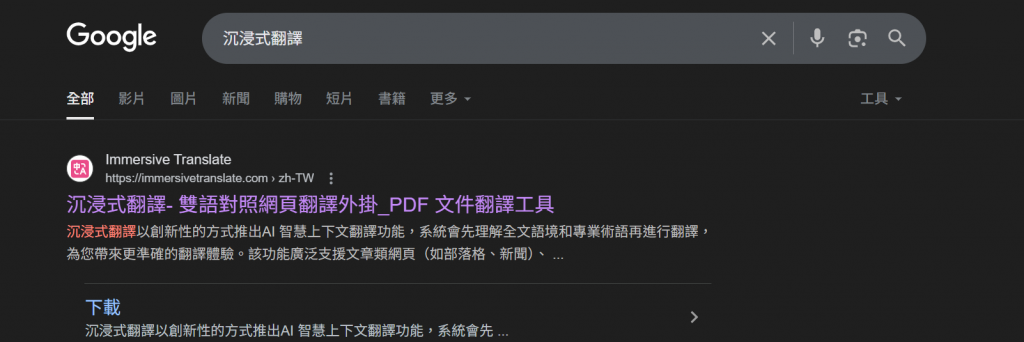
以下是這次比賽的Overview 👇
Welcome to the 2025 Kaggle Playground Series!
We plan to continue in the spirit of previous playgrounds, providing interesting and approachable datasets for our community to practice their machine learning skills, and anticipate a competition each month.
Your Goal: Your goal is to predict whether a client will subscribe to a bank term deposit.
簡單來說:
這是一個 二元分類任務 (Binary Classification),我們的目標是預測客戶是否會申請銀行的定期存款。
接著一定要看 Evaluation。這告訴我們比賽的評分指標是什麼,因為 leaderboard 排名就是依照這個指標來算的。這次比賽的評分方式是 ROC AUC (Area Under the ROC Curve)。是用 ROC 曲線下面積 (AUC) 這個數值作為評分指標,那關於ROC AUC是什麼,要怎麼樣才有可能讓這個分數變高,我後續會再說明。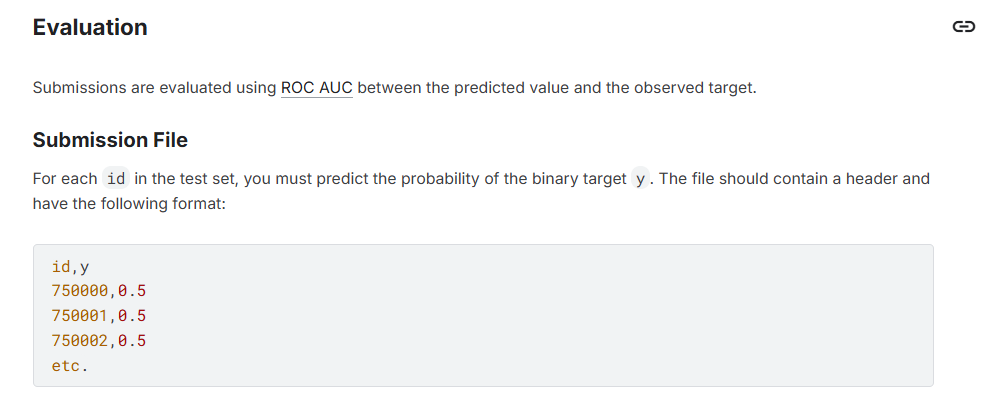
理解完任務與評分後,我們就可以打開 Colab(或是自己常用的寫程式工具),上傳下載好的 Kaggle 檔案(.zip),開始檢查資料。第一步通常會檢查:資料有多少筆、多少欄位、前五筆資料、確認哪些欄位是數值型、類別型。
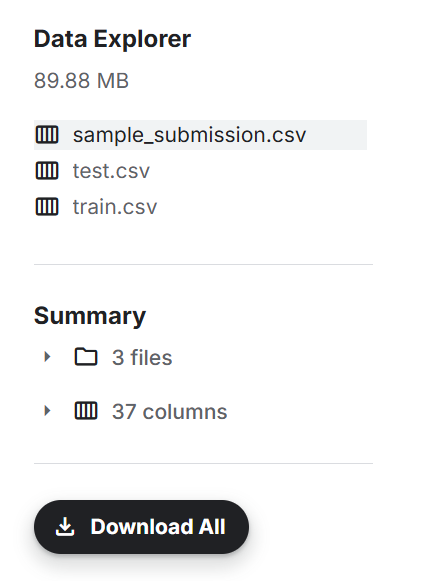
可以看出資料夾裡面有三個檔案:train.csv、test.csv、sample_submission.csv,因此我們可以先把train.csv、test.csv叫出來看看他們長什麼樣子。
#解壓縮
import zipfile
zip_path = "你的壓縮檔案路徑"
final_path = "/content/playground" # 解壓縮後存放的資料夾
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
zip_ref.extractall(final_path)
print("解壓縮完成!")
#讀取 CSV
import pandas as pd
train = pd.read_csv(os.path.join(final_path, "train.csv"))
test = pd.read_csv(os.path.join(final_path, "test.csv"))
print("train.csv 筆數:", len(train))
print("test.csv 筆數:", len(test))
執行成功後會看到
train.csv 筆數: 750000
test.csv 筆數: 250000
# 查看資料筆數與欄位數
print("Train shape:", train.shape) # (列數, 欄位數)
print("Test shape:", test.shape)
# 顯示前五筆訓練與測試資料
display(train.head())
display(test.head())
執行成功後會看到跟下圖一樣的畫面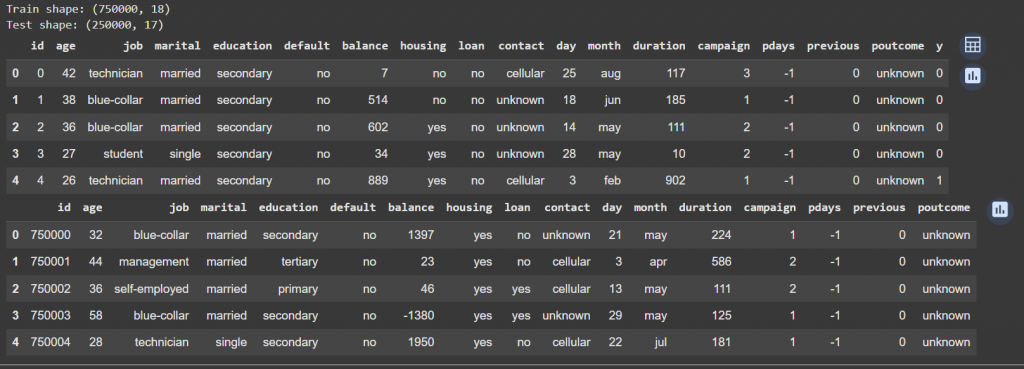
在進入建立模型前,我們通常需要進行一些基本的資料前處理:
## 檢查缺失值
print(train.isnull().sum())
## 確認類別型欄位
categorical_cols = train.select_dtypes(include=["object"]).columns
print("Categorical columns:", categorical_cols)
## 對類別欄位做 one-hot encoding
train = pd.get_dummies(train, columns=categorical_cols)
test = pd.get_dummies(test, columns=categorical_cols)
## 確保 train/test 欄位一致,使特徵對齊
train, test = train.align(test, join="left", axis=1, fill_value=0)
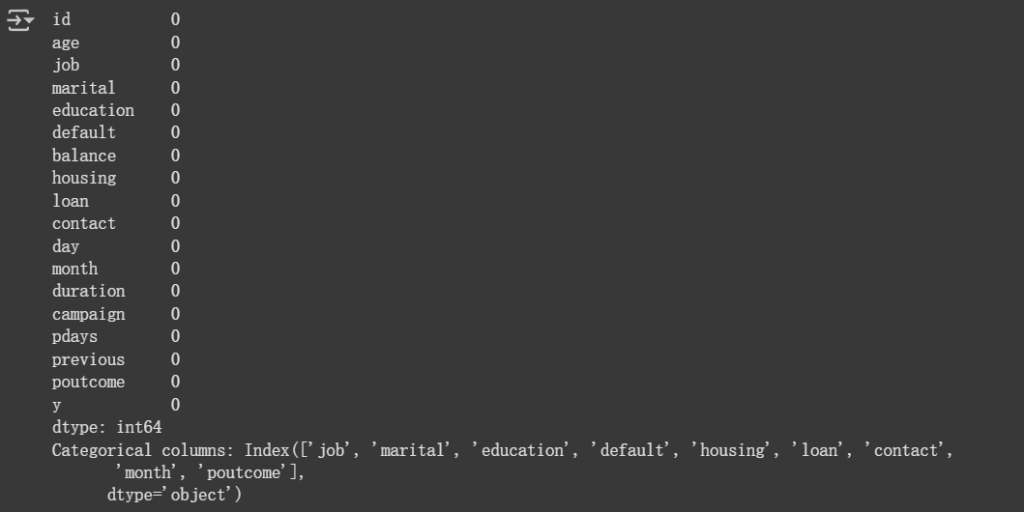
Q1:或許你會疑惑為什麼不檢查 test 缺失值?
A1:其實可以檢查,只是通常會將重點放在 train,因為模型訓練用的是 train,如果 train 有缺失值不處理,模型就沒辦法學習或會報錯。不過,檢查 test 缺失值也是好習慣,可以避免推論時遇到缺值報錯。
Q2:為什麼要做 One-Hot Encoding?
A2:因為機器學習模型(特別是線性模型、神經網路)通常不能直接處理文字類別,要把類別轉成數值:假設有一個欄位 color 有三個類別:red, blue, green如果直接轉成數字 (red=0, blue=1, green=2),模型會誤以為它們有順序關係,One-Hot Encoding 會把它拆成三個欄位:red (是 red=1, 否=0)、blue (是 blue=1, 否=0)、green (是 green=1, 否=0)
| red | blue | green |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
其實除了 One-Hot Encoding,還有 Label Encoding、Frequency Encoding 和 Target Encoding,每一種方法都有各自的優缺點。至於該選哪一種,通常取決於「資料的類別型態」以及「訓練模型的種類」。由於我們這次的資料類別數量不多,所以選擇了相對入門、最直觀的 One-Hot Encoding。未來如果遇到更多類別 或更複雜的資料型態,我會再教大家如何挑選適合的編碼方式,並且比較它們在不同模型下的效果。
到這裡,我們已經完成 Kaggle 入門比賽最重要的第一步:
理解比賽任務 → 這是一個二元分類問題
確認評分方式 → 這場比賽採用 ROC AUC
檢查資料型態 → 確認欄位性質、缺失值、類別型資料
接下來,我們就能進一步嘗試建立模型,再慢慢優化


 iThome鐵人賽
iThome鐵人賽