昨天我們聊了 Pooling 策略,像是 mean pooling、max pooling,這些方法可以把一個句子壓縮成固定長度的向量。但是這些方法還有一個致命的缺點:它們完全不考慮 詞序 (order)。
舉例來說:
在處理自然語言時,我們常常需要考慮 上下文的順序。
傳統的 RNN (Recurrent Neural Network) 就是為了這件事設計的:
但實際上,RNN 有兩個大問題:
梯度消失 (vanishing gradient)
梯度爆炸 (exploding gradient)
在 RNN / LSTM 這種「時間序列模型」裡,我們在做 反向傳播 (backpropagation through time, BPTT) 的時候,梯度要一路往前傳。
簡化公式長這樣:
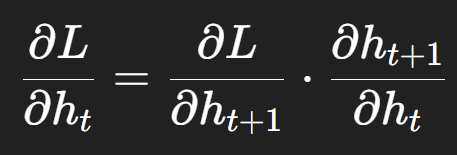
換句話說,每一步的梯度都要乘上一個數字(其實是一個權重矩陣的導數)。
這就像你要把一件事情「小聲地傳過 20 個人」,每個人都小聲一點 (0.9 倍),到最後一個人,聲音已經聽不到了。
這就是 梯度消失。
學不到長期依賴
收斂很慢
跟前面一樣,在 RNN / LSTM 這類「要把訊號往時間軸一直傳遞」的模型裡,我們在做反向傳播 (backpropagation through time, BPTT) 的時候,梯度會一路往前傳。所以每一次反向傳播,梯度都要乘上一個權重矩陣的導數。如果這個矩陣的「特徵值」大於 1,那梯度每乘一次就會被放大!
我們再來舉一個生活例子,想像你在考英文聽力。你手上拿著麥克風,並把它對著喇叭,一開始你反映聽不到 → 考官就把音量調大。結果聲音傳到麥克風 → 又被放大 → 再傳到喇叭 → 又被放大,聲音就這樣不斷被倍數放大,最後整個音響系統「爆音」。
也因為這兩個問題,這時候,LSTM (Long Short-Term Memory) 就站出來了。
LSTM 的厲害之處在於它多了「門控機制 (gates)」,可以決定「什麼資訊要記住、什麼要忘掉」。
主要有三個 gate:
Forget Gate (遺忘門)
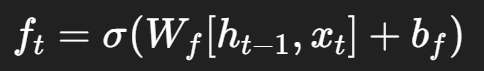
Input Gate (輸入門)
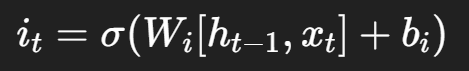
Output Gate (輸出門)
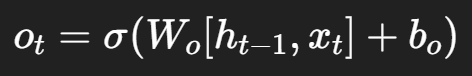
同時,它會維護一個 Cell State (細胞狀態),像一條「記憶高速公路」,資訊可以長距離傳遞,不容易消失。
在我們的比賽裡,我們希望模型不只是看「詞袋」(Bag-of-Words),而是要能理解「詞序」帶來的差異。
如果用 Word2Vec/GloVe/FastText 搭配 pooling,模型看不到順序。
但如果我們把句子轉成詞向量序列,再丟進 LSTM,模型就可以:
這樣,模型就能理解「我愛你」和「你愛我」的差別!


 iThome鐵人賽
iThome鐵人賽