
上一篇我們介紹了 DynamoDB 的查詢工具(PK、SK、GSI、LSI),今天我們要嘗試把實際的業務邏輯翻譯成單表設計,看看為什麼 GSI 能在這裡發揮強大作用。
我們的協作平台大致長這樣:
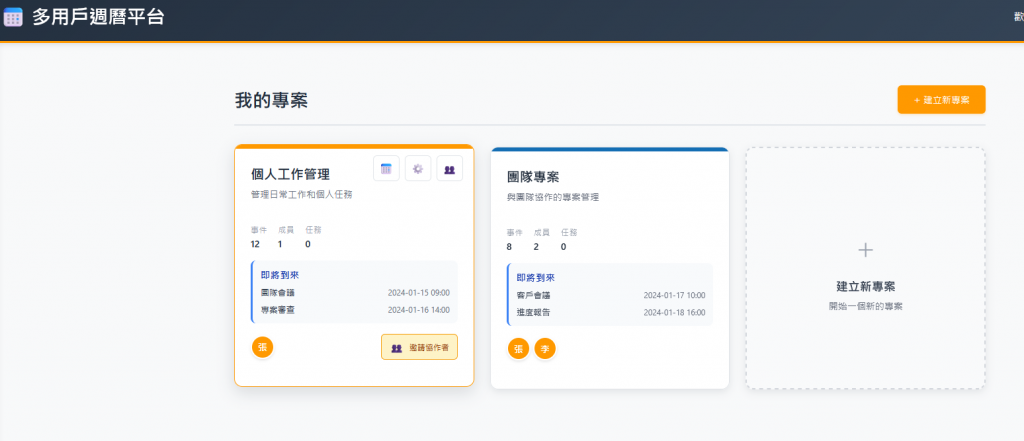
- 使用者可以創建 專案 (Project)
- 每個專案中有多位 使用者 (User) 共同參與
- 在專案中大家共享一份 日曆 (Calendar),上面可以放很多 活動 (Event)
- 一個使用者可以參加多個專案
- 一個活動一定屬於某一個專案
其實仔細觀察後會發現:
「專案」和「日曆」幾乎是 一對一綁定 的,沒有必要分成兩個實體。
因此我們可以 省略日曆這一層,直接把所有活動掛在專案底下。
如果用 SQL,我們通常會這樣拆:
查詢範例:
JOIN Projects 與 ProjectMembers,找出某使用者參加的專案JOIN Events 與 Projects,找出某專案底下的活動可以做到,但查詢會牽涉到多次 JOIN。
在 DynamoDB 裡,最重要的就是 PK (Partition Key) 和 SK (Sort Key)。
單表設計的精髓在於:不同的資料型別(Project / User / Event)都放進同一張表,靠 PK、SK 來組織與查詢。
這裡我們的規劃是:
PK = ProjectId (查詢效率最高 API Calls 不會浪費在重複查詢)
SK = 有前綴的字串 (透過前綴來區分不同實體)
而ProjectId 會成為我們的主要 PartitionKey,同一專案底下的資訊會集中在一個分區。
| PK (PartitionKey) | SK (SortKey) | EntityType | Attributes |
|---|---|---|---|
| PROJECT# | METADATA | Project | title, description, owner |
| PROJECT# | USER# | Member | role, joinDate |
| PROJECT# | EVENT# | Event | title, startTime, endTime, notes |
這樣:
SK = METADATA
begins_with(SK, USER#)
begins_with(SK, EVENT#)
不用 JOIN,全都在同一個 Partition。
問題來了:我們視情況還需要以使用者為 Key 的查詢,像是以下這些情境:
在 DynamoDB 裡,雖然我們已經用完了 PK 和 SK,但我們可以靠 GSI 來幫我們完成這個查詢邏輯。
我們先看一張對照表:
| 使用場景 | PK (PartitionKey) | SK (SortKey) | 查詢方式 |
|---|---|---|---|
| 查專案細節 | PROJECT#<ProjId> |
METADATA |
PK=PROJECT#123, SK=METADATA |
| 查專案的成員清單 | PROJECT#<ProjId> |
USER#<UserId> |
PK=PROJECT#123, begins_with(SK,USER) |
| 查專案的事件清單 | PROJECT#<ProjId> |
EVENT#<EventId> |
PK=PROJECT#123, begins_with(SK,EVENT) |
| 查某位使用者參與哪些專案 | USER#<UserId> (投影到 GSI1PK) |
PROJECT#<ProjId> (GSI1SK) |
透過 GSI,PK=USER#456 |
這裡的最後一行就是關鍵:
即使在原始表裡,User 資料是掛在 Project 底下,但我們可以建立一個 GSI,讓查詢「從使用者反查專案」變得容易。
python
from aws_cdk import (
aws_dynamodb as dynamodb,
core
)
class DynamoDemoStack(core.Stack):
def __init__(self, scope: core.Construct, id: str, **kwargs):
super().__init__(scope, id, **kwargs)
table = dynamodb.Table(
self, "ProjectTable",
partition_key=dynamodb.Attribute(
name="PK",
type=dynamodb.AttributeType.STRING
),
sort_key=dynamodb.Attribute(
name="SK",
type=dynamodb.AttributeType.STRING
),
billing_mode=dynamodb.BillingMode.PAY_PER_REQUEST
)
# 建立一個 GSI 來支援「使用者反查專案」
table.add_global_secondary_index(
index_name="GSI1",
partition_key=dynamodb.Attribute(
name="GSI1PK",
type=dynamodb.AttributeType.STRING
),
sort_key=dynamodb.Attribute(
name="GSI1SK",
type=dynamodb.AttributeType.STRING
),
projection_type=dynamodb.ProjectionType.ALL
)
如此一來我們就可以透過PK Project 來查詢 Event,同時也可以透過原本不是PK的User來去找出 Project 進而實現儀表板以及日曆行程管理的邏輯

可以把 GSI 想像成「分身表格」只不過同樣的 item 被換了Primary Key(Partition Key + Sort Key) 於是可以用不同的方式來查資料
如果需要在同一專案內,根據不同條件排序活動(例如依照狀態或起始時間),我們可以利用 LSI:
status 作為 SortKeystartTime 作為 SortKey這樣:
今天我們的實作重點放在「把專案、成員、事件」放在同一個 Table 裡,並透過 GSI 讓查詢能夠靈活切換。
這種做法在 DynamoDB 的世界裡有一個很大的優勢:天然的可擴展性。
查詢分區化 (Partitioning)
所有跟同一個專案相關的資料,都會被放到相同的 Partition 裡。這樣查詢專案成員或事件時,就能快速掃描,而不用像關聯式資料庫那樣做多表 JOIN。
高併發讀寫
DynamoDB 的底層是分散式設計,每個 Partition 可以獨立擴展。
單表設計意味著我們的資料模型是「查詢導向」,不會被過多的隨機 Query 拖垮。
GSI 提供彈性的查詢路徑
我們可以根據業務需求隨時新增 GSI,讓原本「需要跨表 JOIN」才能完成的邏輯,在單表中以投影欄位的方式完成。
簡化 Schema 演進
新的 Entity 只要定義好 PK / SK 前綴,就能直接加入同一個 Table。
不需要動資料庫結構,也不會因為 Schema Migration 而造成系統中斷。
DynamoDB 單表設計讓「查詢快速」和「系統擴展」兩者兼得,很適合做為大型高併發系統(像是遊戲後端、IoT 平台)的資料庫解決方案,但同時因為按需計費 (Pay per request) 也很適合我們的小小專案。
今天我們完成了業務邏輯到資料模型設計的部分,成功定義了協作平台的資料庫設計
藉此經驗我們也能分割出來 RDB 經典的 SQL 模式與 DynamoDB 的資料設計思考角度的不同
希望在今天的實作過程中有讓大家滿意,往後我們將會繼續向專案中的其他部件進行實作,敬請期待

 iThome鐵人賽
iThome鐵人賽