昨天稍微介紹了 padding mask,基本上語音或文字相關都需要處理這部分,所以了解一下不吃虧。
參考文章及圖片來源:https://www.cnblogs.com/rossiXYZ/p/18758992
這裡先介紹一下自回歸,主要是等下的 mask,需要先知道這個觀念。
自回歸是根據之前已生成內容,用遞歸的方式預測下一像要生成的內容,簡單可以想成使用過去內容去預測下一個機率分布。
老樣子先來張圖,這裡最一開始輸入"今" 得到輸出"天"(機率最高),然後把"今"跟"天" concat 在一起,變成"今天"當輸入,依此類推
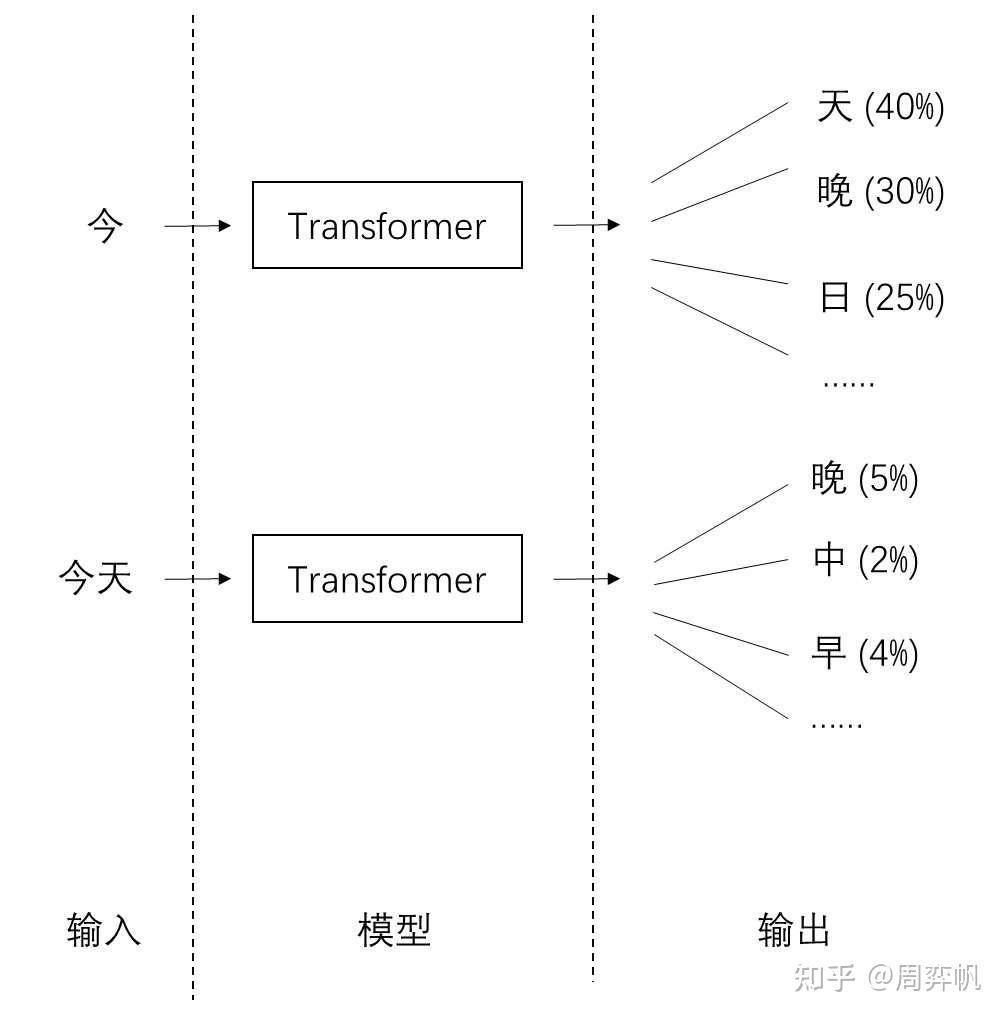
圖片來源: https://zhuanlan.zhihu.com/p/710748815
或者可看: https://yuegs.com/2025/03/28/fnn/ 動態圖表示
看完上面的說明你可能會有以下問題
Q: 這樣子模型不是越跑越久?
A: 沒錯,尤其是 self-attention 有大家常提到的二次時間的複雜度,但可以透過 kv-cache 或一些技術改善。
Q: LLM 常聽到 prompt,就是這個輸入嗎?
A: 沒錯,LLM 在 inference 有兩個階段 prefill 和 decode ,prefill 階段就是將你輸入的 prompt 做第一次計算產生出第一個 token,後續就進到 decode 階段開始遞迴生成 token。
核心觀念: 防止模型偷看
在剛才的第二個 QA,談到的是 inference,如果是訓練的話只有 prefill 階段 (畢竟訓練還給他慢慢遞迴,要訓練到何時),需要搭配我們接下來要講的 mask。 (inference 也還是會用,主要是跟訓練相同)
上面名稱我最喜歡最後一個,也就是 look-ahead mask,因為名稱上最直觀,也就是只看前面不能看後面,那至於會長怎樣呢?
會是底下圖當中的下三角矩陣,可以想像第一行一個 x 代表只看"新"(搭配下下圖),第二行兩個 x 代表只看"新年"依此類推。
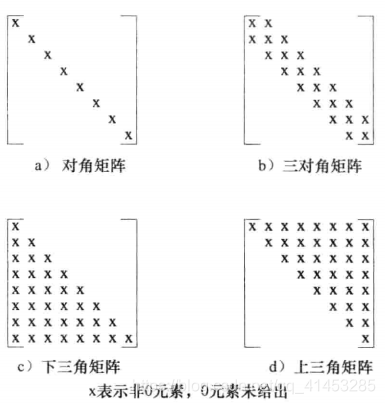
圖片來源: https://blog.csdn.net/weixin_53666393/article/details/122496413
那會跟 padding mask 一起做計算,得到下圖。
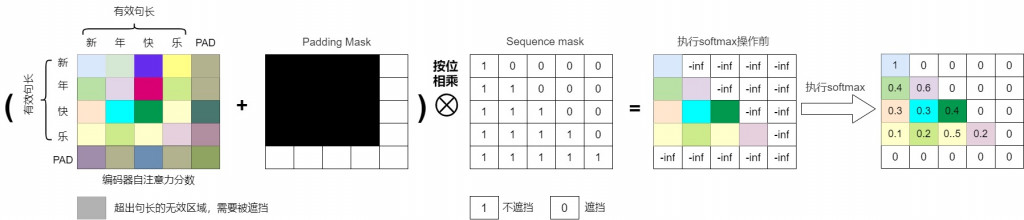
理解完剛才的部分,可以發現不難,其實就是一個下三角矩陣而已,torch 這部分已經有可以使用的 function → torch.triu
單純 mask 的部分基本上大家都差不多,但寫法上有兩種,但不管是哪種只要記得目的是要讓 softmax 完的結果是0就行。
底下給出的是方法一,但又跟圖上說明的不一樣,這裡使用 bool,主要用於後面可以直接 OR 做運算(speechbrain 這部分實現),程式方面更精簡。
import torch
def mask():
B, H, L = 2, 2, 5 # (batch, n_head, seq_len)
attn_scores = torch.rand(B, H, L, L)
# padding mask: shape (B, L)
padding_mask = torch.tensor([
[False, False, False, True, True],
[False, False, False, False, False]
])
# causal mask: shape (L, L)
causal_mask = torch.triu(torch.ones(L, L, dtype=torch.bool), diagonal=1) # 上三角為 True
# padding mask reshape -> (B, 1, 1, L)
pad_mask_expanded = padding_mask[:, None, None, :] # (B,1,1,L)
causal_mask_expanded = causal_mask[None, None, :, :] # (1,1,L,L)
print(f'mask 之前:\n {attn_scores}')
# 合併兩個 mask (logical OR -> 有一個 true 就是 true)
combined_mask = pad_mask_expanded | causal_mask_expanded # (B,1,L,L) broadcast to (B,H,L,L)
# 填入很大的負數
attn_scores_masked = attn_scores.masked_fill(combined_mask, -1e9)
print(f'mask 之後:\n {attn_scores_masked}')
attn_weights = torch.softmax(attn_scores_masked, dim=-1)
print(f'softmax 之後:\n {attn_weights}')
if __name__ == "__main__":
mask()
可以再參考下圖,知道使用時機。

這裡可以參考 minimind 跟 speechbrain 超連結當中的 code,可以更清楚瞭解大家是怎麼處理這段的,不管是哪一個目的都是為了讓 softmax 完的結果為0,今天就到這裡囉~~


 iThome鐵人賽
iThome鐵人賽