前幾天我們已經把 MoE 介紹完也實作完了,主要是應用在 LLM 方面,那如果是其他任務呢?
前陣子開始研究 ASR 及 AST 相關研究,也就是 nemo 的 canary,是一個 multi-task 的模型,其中有推出兩種,一開始是 canary-1b,後來是 canary-1b-flash,當中有推出比較小 size 的模型,如 canary-180m-flash,我在公司機器是 4090 也就是 24G 記憶體,照我們學過的資源估計,要訓練 1b 的模型幾乎是難上加難,所以我轉而研究 180m,但我們之前提過了模型參數量會到一定大小才會有湧現現象,所以我開始研究能不能使用 MoE 來取代掉 FFN,並且參考以下論文,嘗試讓效果更好。
另外一個觀念稍微提一下,之所以會用這些模型,主要是因為他們用大量 GPU 以及大量語料去訓練,拿這樣子的 pre-trained model weights 接續著 fine-tune,通常效果都不錯(因為已經學會聲音特徵等等),所以我自己改架構的前提是能保留原先 weights 的部分,因此我將原先的 FFN 當作 shared expert,額外加上 routed expert,這樣子就不會浪費原先 FFN 的 weights 了。
架構圖如下,可以很清楚看到,分別在每一層的 Encoder 和 Decoder 各有兩個 FFN,
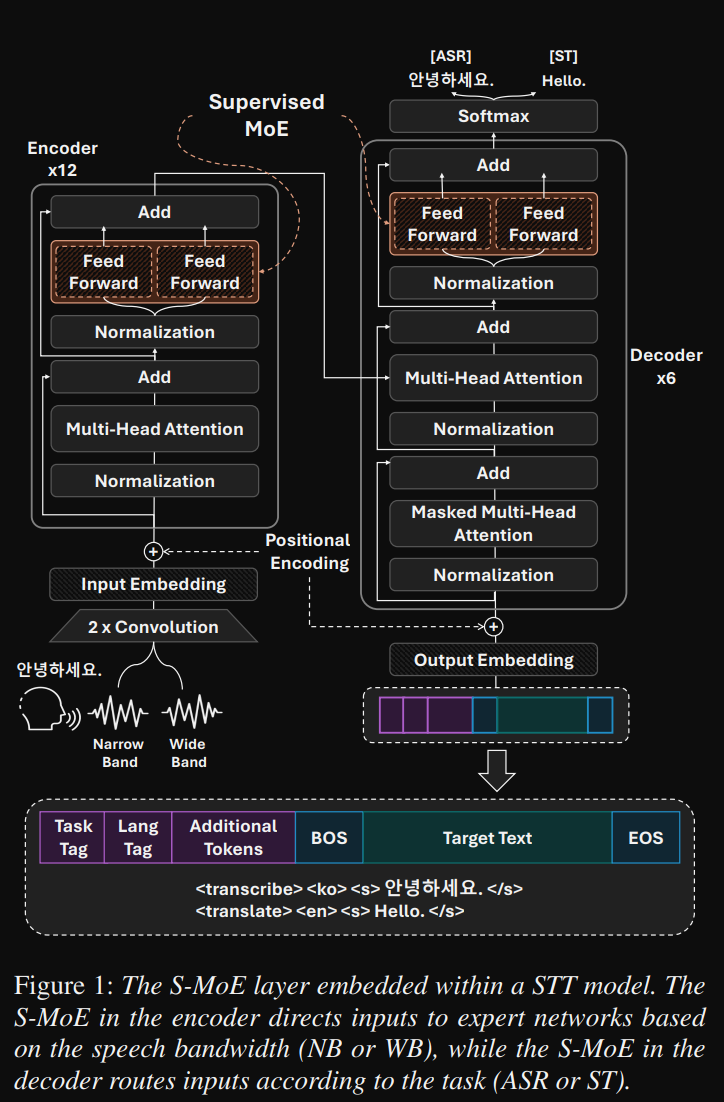
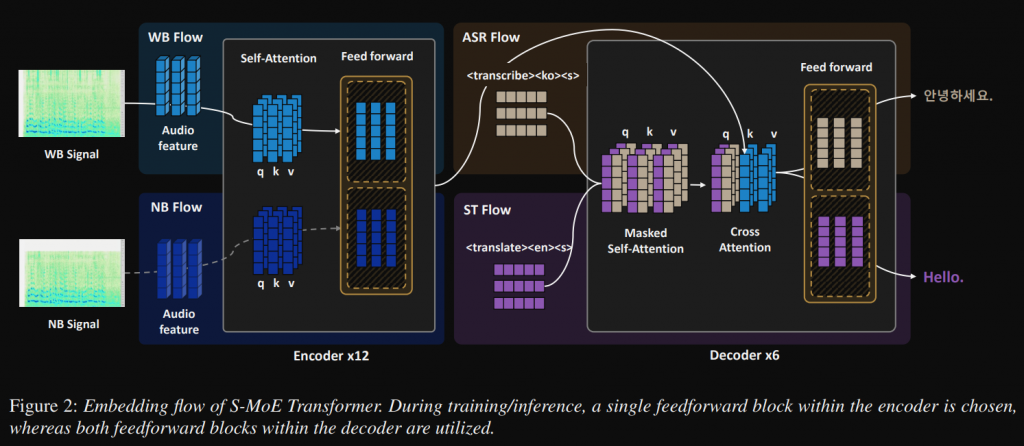
此篇是最新的一篇,有以下創新點:
在這篇文出之前其實我已經嘗試在 Decoder 使用 MoE,但沒有像論文當中直接用 Supervised 的方式,感覺這樣更高效,但有個需要考慮的是,論文只有韓語的 ASR 及韓語翻英文的 AST,並沒有更多語言,如果更多語言那還適合這種架構嗎? 還是多增加 FFN 來處理各個語言? 這感覺是可以思考及嘗試的點。
架構圖如下,本篇論文的重點是共用同一個 router,這樣的好處有以下幾點(參考第二個圖):
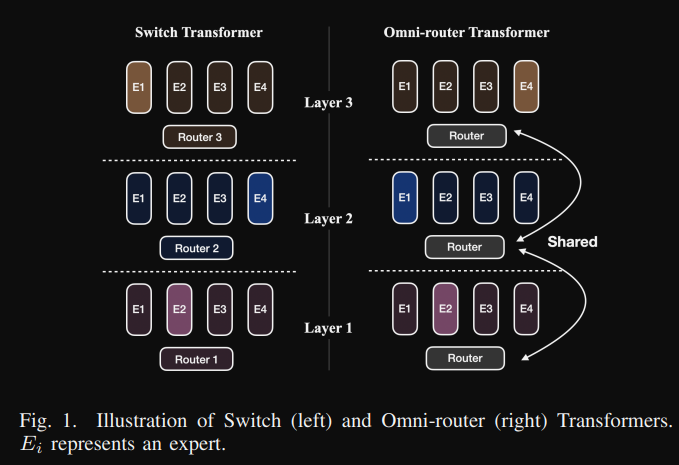
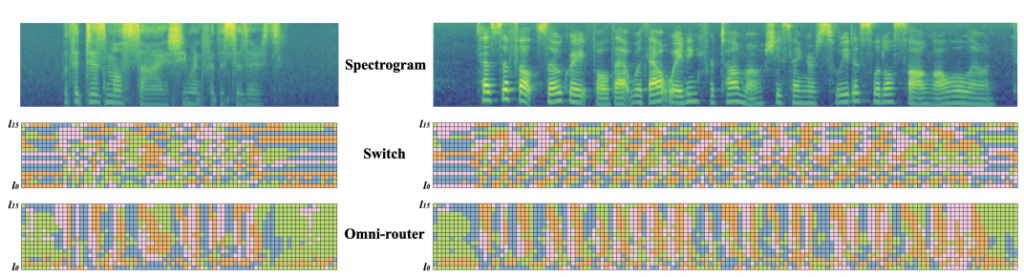
此篇論文主要是訓練 1M 小時的英文,測試專家數量有 2, 4, 8 然後只選擇 top-1,創新點: Shared Router。
不過論文並沒有針對多語言做訓練,不過應該可以想像每個語言應該會對應到1~2 個顏色專家。
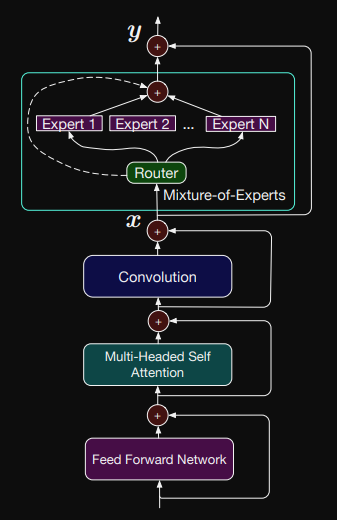
架構圖如下,這篇算是比較早期的論文,主要是採用 conformer 的 encoder 跟 nemo 的模型一樣,當中有前後兩個 FFN,論文有測試前後都改成 MoE (如第二個圖),主要是用 MoE 來增加多語言的效果。
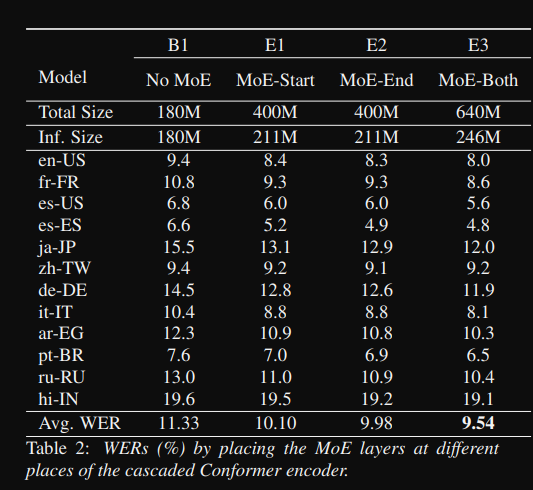
雖然只是簡單帶大家看以上三篇論文,但可以很清楚看到,透過 MoE 來增加模型的效能,未來應該會有更多將 MoE 應用在 ASR 的部分或其他任務。
以上是分享我自己實作的經驗,有時候有想法就可以去試試看,可能過沒多久就會有相關論文,而實作的嘗試可以讓你學得越多對架構越有想法,說不定有機會更進一步改善你的模型。
今天就先到這裡囉~


 iThome鐵人賽
iThome鐵人賽