昨天將 casual mask 講完了,通常會與 padding mask 搭配一起使用,不過每個實現多少都有些差別,不過目的都是一樣的。
參考文章(圖片來源): https://www.cnblogs.com/rossiXYZ/p/18765884
https://mp.weixin.qq.com/s?__biz=MzUzOTgwNDMzOQ==&mid=2247503288&idx=1&sn=ee4b2bc1b396a1e82725998911ded45d&scene=21&poc_token=HIodn2ijF4G-FdY5VoSgRpbi48qCpPb5iDlT1y-z
https://zhuanlan.zhihu.com/p/1916544153791214713
激活函數其實很多種,但比較常看到的是以下幾種
核心觀念: 增加非線性關係 → 提取有效訊息過濾無效訊息
這裡先提一下激活函數,因為等等會用到,那激活函數目的是為了添加非線性關係,因為 attention 本身可看成線性的運算,即使你再多層最終輸出仍然是輸入的線性組合,這樣子表達能力是有限的,所以才需要此函數,讓模型可以學習更複雜的函數關係。
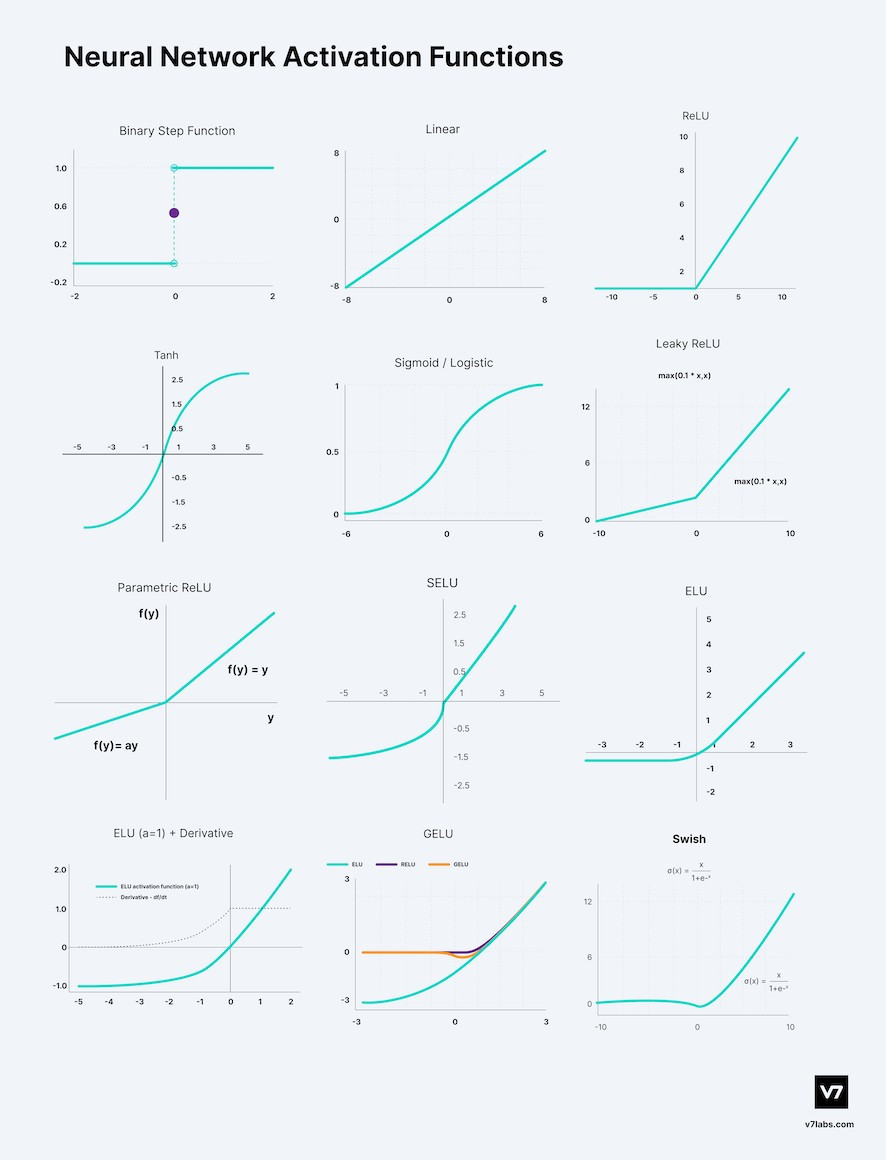
圖片來源: https://www.v7labs.com/blog/neural-networks-activation-functions
在核心觀念當中有提到,提取有效訊息過濾無效訊息,再搭配圖來看,比如 ReLU 的左半皆為 0,可簡單看成丟失了 50% 訊息,使用激活函數會與等下提到的 FFN 的升維有關。
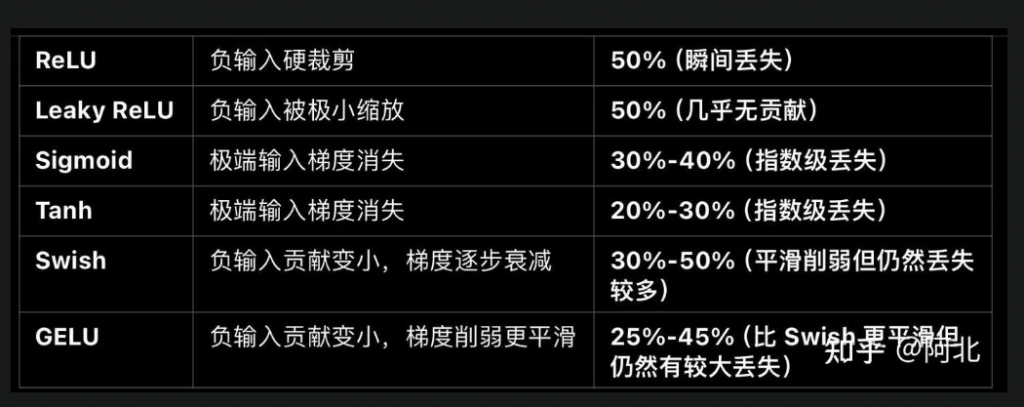
核心觀念: 知識庫 → 儲存更多訊息 → 表達能力更強
在 transformer 當中有一個 FFN 的 block,剛開始學的時候我以為這個沒那麼重要,因為他設計其實很簡單不難,但真正了解之後才發現,如果沒有這個 FFN 那即使你有 attention 也沒用。
可以參考下圖,你會發現架構上真的不難,最基本是兩個 Linear + 1 個 Activation,那會再加上 LayerNorm 和 Dropout。
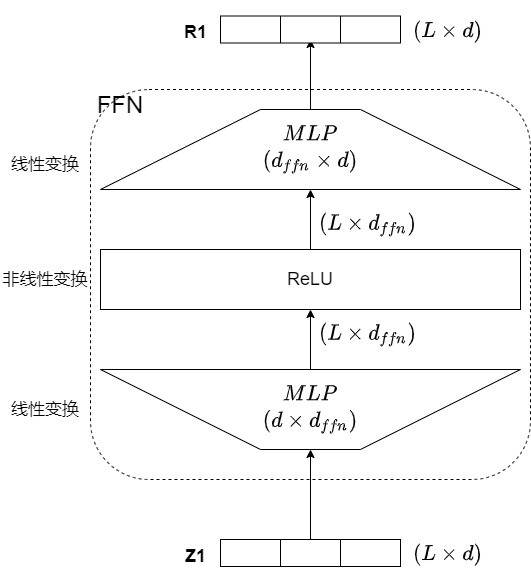
看完上圖之後又來幾個QA拉
Question:
Ans 1 觀念
FNN 取名為 position-wise feed forward networks, position-wise 表示對序列中的每個元素分別採用相同的線性變換,有以下優點:
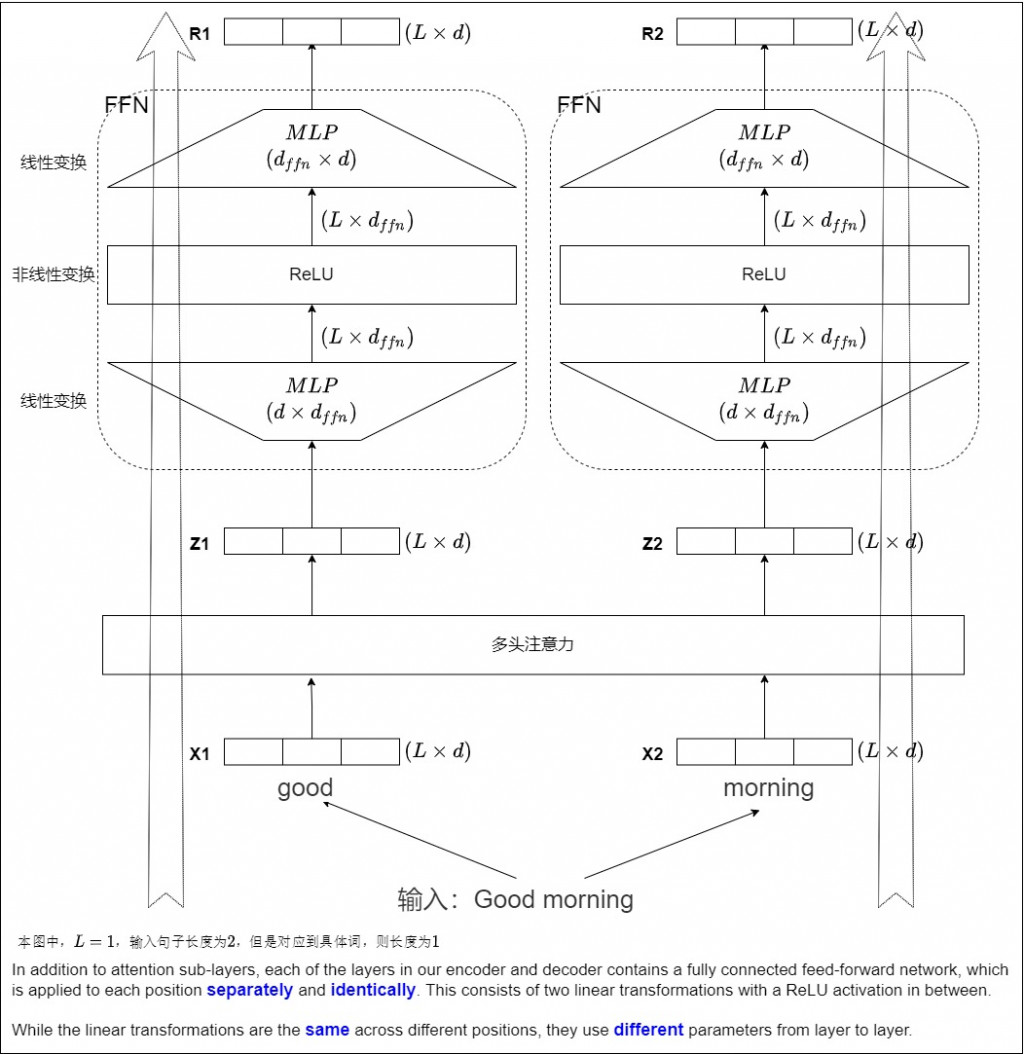
總結:
Attention 負責讓單詞彼此交流,FFN 則是幫每個單詞自己消化資訊。
Ans 2 觀念
透過升維與降維兩個動作,來提取更多豐富的語義訊息
升維: 其主要作用是擬合一個更高維度的映射空間,從而提升模型的表達能力和擬合精度。 有效擴展網路的自由度,使得模型能夠學習更多的特徵表示,從而提升模型的擬合能力。
用下圖可以更好理解,假設我要在二維分出紅球跟藍球,你會發現非常的難,但如果我提高維度變成是在三維,你會發現只需要一個平面就可以分出兩群。 所以在低維空間中,向量的表示能力有限(二維很難分出兩群),很難捕捉數據的複雜結構,但升高維度,可以更好的表達(三維就能簡單分出兩群)。
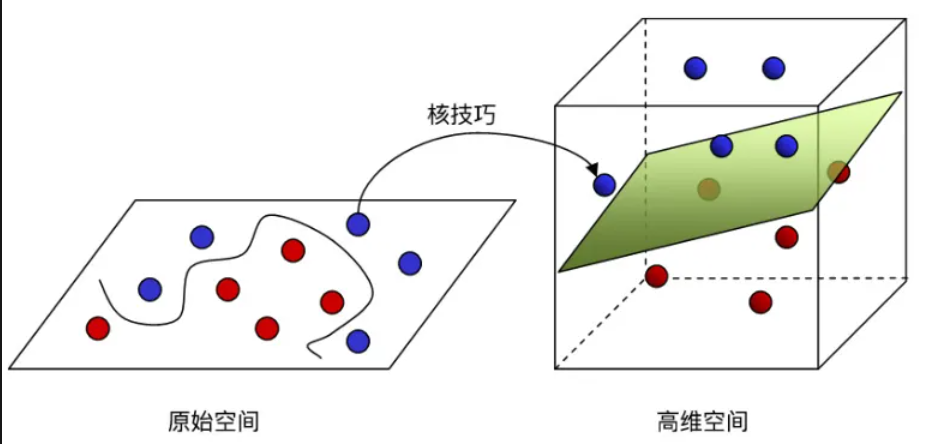
降維: 其主要作用是濃縮特徵, 維度還原, 限制計算複雜度。
Ans 3 觀念
一樣參考之前提到過的論文在 SMALL LANGUAGE MODELS:
SURVEY, MEASUREMENTS, AND INSIGHTS
論文當中有提到,SLM 當中的架構分布
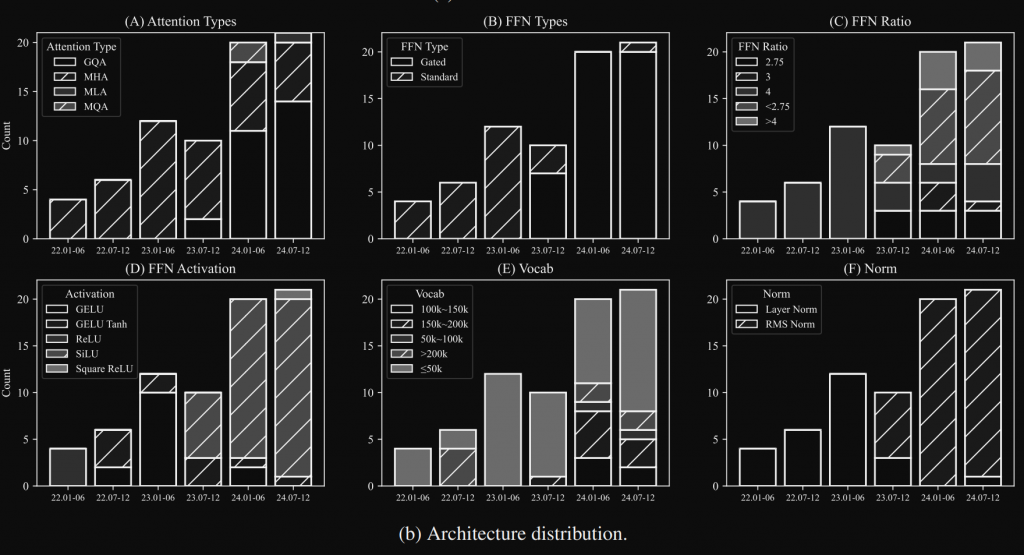
其中有幾個我們還沒提到,不過光看 FFN 的趨勢,會發現已經改變很多了。
如果使用 ReLU 通常 Ratio 會是4,簡單的理解為,當達到4倍可以抵消剛才上面提到的 ReLU 丟棄 50% 的訊息,所以這就是為什麼需要在非線性函數前做升維的動作。
更詳細的說明可參考這篇。
因為篇幅不想太長,剩下我們明天繼續囉~


 iThome鐵人賽
iThome鐵人賽