昨天我們把 Auxiliary-Loss 的方式時做完了,這是比較早期提出來的方式,目前使用率還是蠻高的。
論文連結: https://arxiv.org/pdf/2408.15664
接著來看由上面論文提出,不使用 loss function,而是透過單一的 bias 改變選取 top_k 的方式,這麼做的好處,可以不影響模型原先的損失函數以及梯度計算。
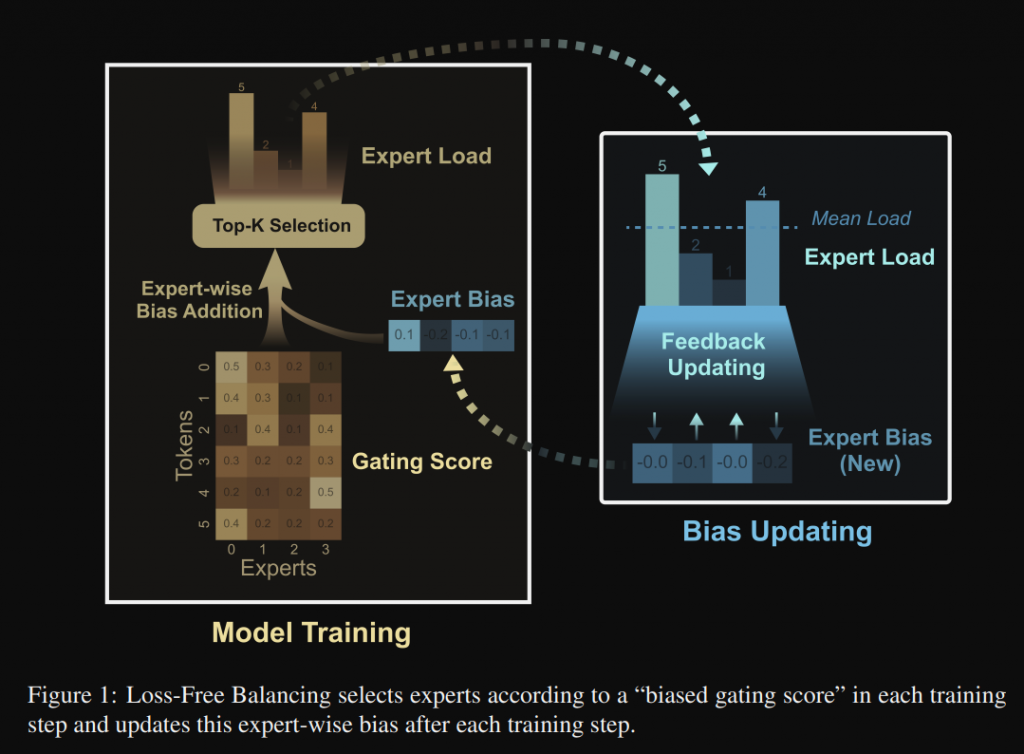
那數學式及流程圖如下,主要是藉由加入 bias 這項,來影響 top_k 的選擇。
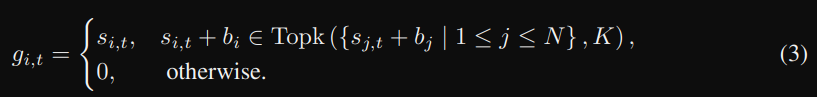

從上圖可以看到,如果專家 i 負載過高,則減少 bi,降低其被選中的機率。
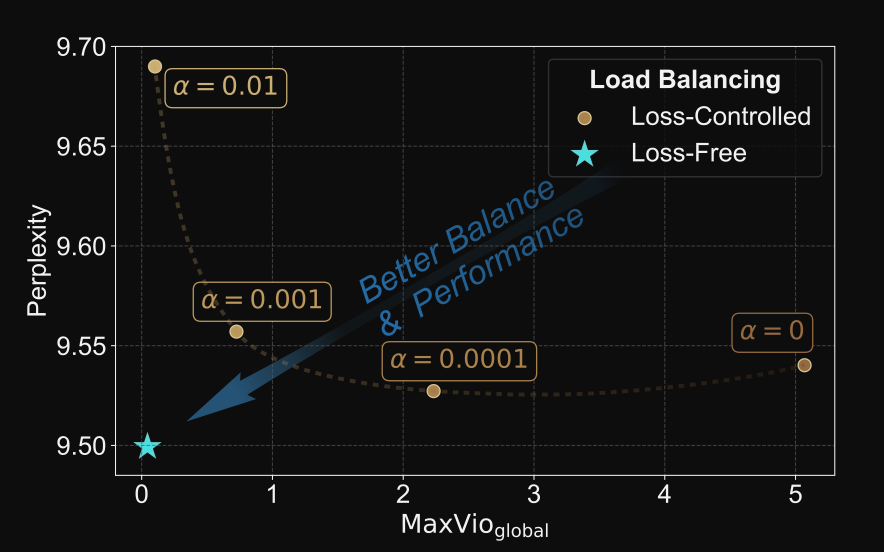
那論文當中比較給出比較圖(如下), loss-free 效果更好,而且簡潔有效。
我們照著論文當中的步驟實作就行了
程式參考:
https://github.com/wajihullahbaig/deepseekv3-minimal/blob/main/models/deepseek_v3.py
https://blog.csdn.net/shizheng_Li/article/details/147685729
import torch
from torch import nn
import torch.nn.functional as F
class MoEGateLossFree(nn.Module):
def __init__(
self,
top_k,
hidden_size,
n_routed_experts,
alpha = 0.001
):
super().__init__()
self.top_k = top_k
self.alpha = alpha
self.n_routed_experts = n_routed_experts
self.gate = nn.Linear(hidden_size, n_routed_experts, bias = False)
self.bias = nn.Parameter(torch.zeros(n_routed_experts), requires_grad = False)
def forward(self, x: torch.Tensor):
'''
x: (B, L, D)
'''
B, L, D = x.shape
# step 1: 攤平 -> (B * L, D)
x_flat = x.view(-1, D)
# step 2.1: 透過 linear 計算 logits -> (B * L, n_routed_experts)
logits = self.gate(x_flat)
# step 3.1: 利用 softmax 計算 scores
scores = F.softmax(logits, dim = -1)
# step 3.2: 在計算 top_k 之前,將 gating scores 和 bi 相加
scores = scores + self.bias
# step 4: 選取 top_k
topk_scores, topk_idx = torch.topk(scores, k = self.top_k, dim = -1)
# step 5: Normalize, 讓總和為 1
topk_scores = topk_scores / (topk_scores.sum(dim = -1, keepdim = True) + 1e-6)
if True: # self.training
# ~~~ 更新 bias (from Algorithm 1) ~~~
# 跟剛才一樣用 one_hot,紀錄每個 token 的 top_k 選擇,哪個專家被選到
# step 3 from Algorithm 1
mask = F.one_hot(topk_idx, self.n_routed_experts).sum(dim = 1).float()
expert_load = mask.sum(dim = 0) # c_i, 剛才 ce 是比例, 現在 c_i 是實際 token 數量
avg_expert_load = expert_load.sum() / self.n_routed_experts # c_i_bar
# step 4 from Algorithm 1
load_violation_error = avg_expert_load - expert_load # e_i
# step 5 from Algorithm 1
with torch.no_grad():
bias_updates = self.alpha * torch.sign(load_violation_error)
self.bias.data += bias_updates
return topk_scores, topk_idx
if __name__ == "__main__":
import random
seed = 42
random.seed(seed)
torch.manual_seed(seed)
x = torch.rand(2, 20, 8)
gate = MoEGateLossFree(2, 8, 4)
gate(x)
MoE 的部分就實作到這囉~


 iThome鐵人賽
iThome鐵人賽