昨天我們成功實作了 DCGAN 並用於生成手寫數字,但問題是「我們沒辦法指定 GAN 具體會生成什麼內容」。因此今天將要學習,如何進行可控的生成。
條件生成對抗網路 (conditional GAN, cGAN) 的想法非常直觀:在訓練和生成時,為生成器和判別器,都額外提供一個「條件」資訊 y。這個 y 可以是任何想要的控制變因,如圖像標籤、一段文字,或是另一張圖片。
cGAN 的結構也有所改動
生成器:輸入不再只是隨機噪點 z,而是噪點 z 和條件 y 的拼接。生成器現在的任務是,學習生成一個既真實、又符合條件 y 的圖像 G(z|y)。
判別器:輸入不再只是一張圖片 x,而是圖片 x 和條件 y 的拼接。判別器現在的任務是,判斷這張圖片 x 是否不僅真實,而且還與給定的條件 y 相匹配。
判別器除了懲罰很假的圖片,也會懲罰雖然看起來真實,但類別錯誤的圖片,達到生成對應內容的效果。
2018 年由輝達推出的 StyleGAN 讓我們可以對生成結果的各個層次的「風格」 進行獨立、精細的控制,並取得了空前的成功。核心創新點包含
風格注入 (style injection)
映射網路 (mapping network):StyleGAN 不再像傳統 GAN 那樣,直接將噪點 z 餵給生成器。它首先用一個 8 層的 ANN(映射網路 f),將輸入的潛在編碼 z,轉換成一個中間的潛在編碼 w。作者認為,這個 w 所在的潛在空間,比 z 空間能更好地分離不同的特徵。
自適應實例正規化 (AdaIN):w 並不是只在生成器的開頭輸入一次,而是會被轉換成「風格 (style)」向量,並透過 AdaIN 這個操作,在生成器的每一層都被注入進去。這使得 w 能夠控制從低階特徵(如細微的皮膚紋理、髮絲)到高階特徵(如臉型、髮型、身份)的方方面面。
漸進式增長 (Progressive Growing):為了生成高解析度圖片(如 1024×1024),StyleGAN 借鑒了 ProGAN 的思想。它在訓練時,先從一個極低解析度(如 4×4)的生成器和判別器開始訓練,待其穩定後,再逐漸地、平滑地增加新的層,將解析度提升到 8×8, 16×16, ...,直到目標的 1024×1024。這種由易到難的訓練方式,極大地增強了訓練的穩定性和最終的生成品質。
隨機噪點輸入:為了生成更逼真的、隨機性的細節(例如雀斑、毛孔、頭髮的精確位置),StyleGAN 在生成器的每一層,還會額外輸入一些隨機的噪點圖。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import os
# --- 1. 設定超參數 (與 Day 24 類似,但增加了 num_classes) ---
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
latent_size = 100
hidden_size = 256
image_size = 784
num_classes = 10 # 0-9 共 10 個類別
num_epochs = 50
batch_size = 128
learning_rate = 0.0002
# --- 2. 載入 MNIST 數據集 ---
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# --- 3. 修改生成器與判別器 ---
# 生成器 G
class Generator(nn.Module):
def __init__(self, latent_size, hidden_size, image_size, num_classes):
super(Generator, self).__init__()
# 輸入維度是噪點 + 類別嵌入
self.main = nn.Sequential(
nn.Linear(latent_size + num_classes, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size * 2),
nn.ReLU(),
nn.Linear(hidden_size * 2, image_size),
nn.Tanh()
)
def forward(self, z, labels):
# 將噪點 z 和 one-hot 編碼的 labels 拼接
cgan_input = torch.cat([z, labels], 1)
return self.main(cgan_input)
# 判別器 D
class Discriminator(nn.Module):
def __init__(self, image_size, hidden_size, num_classes):
super(Discriminator, self).__init__()
# 輸入維度是圖片 + 類別嵌入
self.main = nn.Sequential(
nn.Linear(image_size + num_classes, hidden_size * 2),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size * 2, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid()
)
def forward(self, img, labels):
# 將圖片和 one-hot 編碼的 labels 拼接
cgan_input = torch.cat([img, labels], 1)
return self.main(cgan_input)
G = Generator(latent_size, hidden_size, image_size, num_classes).to(device)
D = Discriminator(image_size, hidden_size, num_classes).to(device)
# --- 4. 損失函數與優化器 (與 Day 24 相同) ---
criterion = nn.BCELoss()
d_optimizer = optim.Adam(D.parameters(), lr=learning_rate)
g_optimizer = optim.Adam(G.parameters(), lr=learning_rate)
# --- 5. 訓練模型 (主要改動在輸入) ---
print("開始訓練 cGAN...")
if not os.path.exists('cgan_results'): os.makedirs('cgan_results')
def to_one_hot(labels, num_classes):
"""將標籤轉換為 one-hot 編碼"""
one_hot = torch.zeros(labels.size(0), num_classes).to(device)
one_hot.scatter_(1, labels.view(-1, 1), 1)
return one_hot
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
batch_size = images.size(0)
images = images.reshape(batch_size, -1).to(device)
labels_one_hot = to_one_hot(labels, num_classes) # 將標籤轉為 one-hot
real_labels_val = torch.ones(batch_size, 1).to(device)
fake_labels_val = torch.zeros(batch_size, 1).to(device)
# --- (1) 訓練判別器 ---
outputs = D(images, labels_one_hot) # 傳入圖片和條件
d_loss_real = criterion(outputs, real_labels_val)
z = torch.randn(batch_size, latent_size).to(device)
# 讓生成器也使用同樣的標籤條件
fake_images = G(z, labels_one_hot)
outputs = D(fake_images.detach(), labels_one_hot)
d_loss_fake = criterion(outputs, fake_labels_val)
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad(); d_loss.backward(); d_optimizer.step()
# --- (2) 訓練生成器 ---
outputs = D(fake_images, labels_one_hot)
g_loss = criterion(outputs, real_labels_val)
g_optimizer.zero_grad(); g_loss.backward(); g_optimizer.step()
if (i+1) % 200 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], d_loss: {d_loss.item():.4f}, g_loss: {g_loss.item():.4f}')
# --- 6. 生成指定的數字 ---
with torch.no_grad():
# 我們要生成 10 個數字 (0-9),每個生成 10 個樣本
num_samples = 10
fixed_z = torch.randn(num_samples * num_classes, latent_size).to(device)
fixed_labels = torch.arange(0, num_classes).repeat(num_samples).to(device)
fixed_labels_one_hot = to_one_hot(fixed_labels, num_classes)
generated_images = G(fixed_z, fixed_labels_one_hot).view(-1, 1, 28, 28)
save_image(generated_images, f'cgan_results/epoch_{epoch+1}.png', nrow=num_classes)
print("訓練完成!")
結果
Epoch 10
Epoch 20
Epoch 30
Epoch 40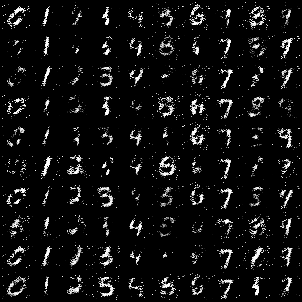
Epoch 50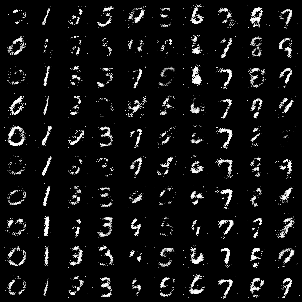


 iThome鐵人賽
iThome鐵人賽