VAE 雖然能生成多樣化的結果,但其生成的圖片(尤其是複雜圖片)往往比較模糊,缺乏細節。如果我們不追求像素級別的重建,而是以以假亂真為目標,那麼 GAN 就是我們的敲門磚。
生成對抗網路 (Generative Adversarial Network, GAN) 在 2014 年被提出,整個模型由兩個相互競爭、共同進化的神經網路組成:
生成器 (generator):接收一個隨機的噪點向量 z(類似 VAE 中的潛在變量),並盡其所能地將這個噪點,變換成一張看起來真實的圖片,用來欺騙另一個網路。
判別器 (discriminator):接收一張圖片,並盡其所能地準確判斷這張圖片的真偽。它會依照判別出的真實程度輸出一個介於 0 到 1 之間的機率值。
訓練的流程,就是不斷地交換固定生成器與判別器,無止盡的生成、判別、回饋,如此交替訓練。理想的結果是,生成器生成的圖片已經達到了「以假亂真」的境界,使得判別器完全無法分辨,只能隨機猜測(輸出機率為 0.5)。此時,我們就得到了一個非常強大的圖像生成器。
優點:GAN 生成的圖片通常比 VAE 更清晰、更銳利,因為它沒有重建損失的束縛,其唯一的目標就是讓圖片看起來「真實」。
缺點:GAN 的訓練過程非常不穩定,很容易出現模式崩潰 (Mode Collapse)(生成器只會生成幾種單調的、它認為最能騙過判別器的圖片)或梯度消失/爆炸等問題,需要大量的調參技巧。
深度卷積生成對抗網路 (Deep Convolutional GAN, DCGAN) 是第一個將卷積神經網路 (CNN) 成功應用於 GAN 的工作。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import os
# --- 1. 設定超參數與設備 ---
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
latent_size = 100 # 噪點 z 的維度
hidden_size = 256
image_size = 784 # 28x28
num_epochs = 50
batch_size = 128
learning_rate = 0.0002
# --- 2. 載入 MNIST 數據集 ---
# 我們將圖片像素值從 [0, 1] 縮放到 [-1, 1],這對 GAN 的穩定性很重要
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# --- 3. 定義生成器與判別器 ---
# 生成器 G
class Generator(nn.Module):
def __init__(self, latent_size, hidden_size, image_size):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size * 2),
nn.ReLU(),
nn.Linear(hidden_size * 2, image_size),
nn.Tanh() # Tanh 激活函數將輸出縮放到 [-1, 1]
)
def forward(self, x):
return self.main(x)
# 判別器 D
class Discriminator(nn.Module):
def __init__(self, image_size, hidden_size):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(image_size, hidden_size * 2),
nn.LeakyReLU(0.2), # LeakyReLU 可以防止梯度消失
nn.Linear(hidden_size * 2, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid() # Sigmoid 激活函數將輸出壓縮到 [0, 1]
)
def forward(self, x):
return self.main(x)
# 建立模型實例
G = Generator(latent_size, hidden_size, image_size).to(device)
D = Discriminator(image_size, hidden_size).to(device)
# --- 4. 定義損失函數與優化器 ---
criterion = nn.BCELoss() # 二元交叉熵損失
d_optimizer = optim.Adam(D.parameters(), lr=learning_rate)
g_optimizer = optim.Adam(G.parameters(), lr=learning_rate)
# --- 5. 訓練模型 ---
print("開始訓練 GAN...")
if not os.path.exists('gan_results'): os.makedirs('gan_results')
for epoch in range(num_epochs):
for i, (images, _) in enumerate(train_loader):
batch_size = images.size(0)
images = images.reshape(batch_size, -1).to(device)
# 建立真假標籤
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# --- (1) 訓練判別器 ---
# 訓練判別器分辨真實圖片
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
# 訓練判別器分辨偽造圖片
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images.detach()) # 使用 detach() 避免計算生成器的梯度
d_loss_fake = criterion(outputs, fake_labels)
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# --- (2) 訓練生成器 ---
# 我們希望生成器能讓判別器認為偽造圖片是「真實」的
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels) # 注意:這裡的標籤是 real_labels
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
if (i+1) % 200 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], d_loss: {d_loss.item():.4f}, g_loss: {g_loss.item():.4f}')
# 每個 epoch 結束後,儲存一批生成的圖片
fake_images_reshaped = fake_images.reshape(batch_size, 1, 28, 28)
save_image(fake_images_reshaped, f'gan_results/epoch_{epoch+1}.png')
print("訓練完成!")
結果
Epoch 10
Epoch 20
Epoch 30
Epoch 40
Epoch 50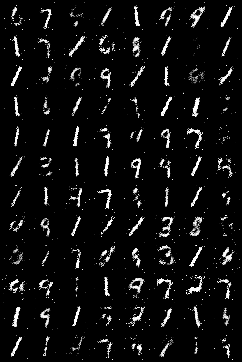


 iThome鐵人賽
iThome鐵人賽