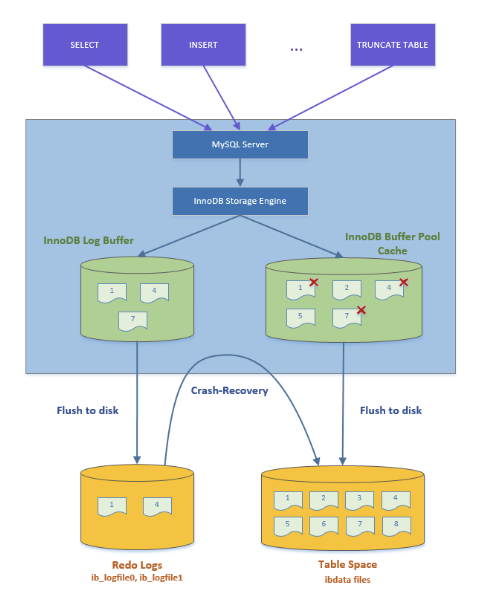
Transaction ACID 中 Durability 要求資料不可遺失,因此一旦 Transaction Commit 後,資料就要寫進硬碟,不能只放在記憶體中。
但 MySQL INSERT or UPDATE 都要找到 B+Tree 中的 Page 更新,不同資料位於不同 Page,頻繁更新時等於是隨機 I/O,對硬碟效能影響很大,例如:
如果是順序 I/O 寫入資料,傳統硬碟磁頭只要往前,而 SSD 只要不斷往空白區塊寫入不用擦除,效能都比隨機 I/O 好。
MySQL 使用 Write Ahead Log (WAL) 結構優化寫入效能,WAL 是 append-only 的檔案,只能往檔案後面空白空間寫資料,不能覆蓋前面的內容,而 Redo Log 是 MySQL 實現 Durability 的 WAL。
當資料更新時,MySQL 會先把 Page 載入 Buffer Pool 並在記憶體中修改 Page 內容,隨後把修改的內容寫入 Redo Log 中,此時寫入就完成了,隨後會有異步 process (aka flush process) 定期把被修改的 Page (aka dirty page) 寫入硬碟 (Table Space) 中的 B+Tree 結構。
Redo Log 不會放整個 Page 資料,而是儲存 Page 的修改內容 (e.g space_id, page_no, file offset, change payload),當 DB crash 後重啟,可重放 Redo Log 內容,將修改資料同步到 B+Tree 結構。
(圖來源:https://blog.naver.com/writer0713/222342927580)
Redo Log 只儲存修改內容,雖然可節省空間,但在 recovery 時帶來新的挑戰。
由於 flush process 寫入單位為整個 Page,如果寫入一半時 OS crash 或者硬碟出問題,會導致 Page 處於半更新狀態 (aka torn page),header LSN (更新版本) 會與 tailer LSN 不一致,此時直接重放 Redo Log 可能無法正確恢復 torn page,因為 page 內容與 Redo Log 紀錄的狀態不一致(例如,file offset 100 的數據預期是 id=2,但實際可能是 id=3 或損壞)。
因此 MySQL 用了另一個順序寫入結構 Doublewrite Buffer 解決這個問題,flush process 會先把 dirty page 寫入 Doublewrite Buffer,整個 page 成功寫入 Doublewrite Buffer 後才會更新到 B+Tree 結構中的 Page。
當 os crash db 重啟時,如果檢查到 B+Tree 中 page 為 torn page,可透過 Doublewrite Buffer 內容直接覆蓋上去,如果 Doublewrite Buffer 裡的 page 為 torn page 就直接棄用,這樣 B+Tree 就不會有 torn page ,重放 redo log 不會有問題。
此時可調整 innodb_flush_log_at_trx_commit 參數:
innodb_flush_log_at_trx_commit=1 1 是預設參數,寫入後就馬上把 Buffer Pool 中修改資料寫進 Redo Log File,並呼叫 fsync 確保 OS 把異動從 OS Cache 寫入 Disk。innodb_flush_log_at_trx_commit=0 0 是效能最好的參數,寫入時異動資料只保留在 Buffer Pool 並透過 Background Log Writer Thread 每秒更新到 Redo Log File,且更新時不呼叫 fsync 而是 write syscall 將資料寫進 OS File Cache 讓 OS 自行決定何時將 OS Cache 寫入 Disk。innodb_flush_log_at_trx_commit=2 2 是介於中間的參數,寫入時異動資料保留在 Buffer Pool, Background Log Writer Thread 每秒更新到 Redo Log File,且更新時執行 fsync 確保 OS 把異動寫入 Disk。預設 innodb_flush_log_at_trx_commit=1 最保險,但瞬間大量寫入造成大量 I/O 可能導致 Redo Log 寫入延遲,crash 時資料還是會丟失。
因此 MySQL 實作 Group Commit 優化,將瞬間多個寫入合併在一起,只執行一次 I/O & fsync syscall 將多筆異動寫入 Redo Log File,實作方法是透過共享鎖 & LSN (更新版本):
假設 orders Table 有 (uid) 的 Index,在執行 UPDATE orders SET uid=1, status=1 WHERE id = 2 時,MySQL 會透過 Clustered Index 找到 Leaf Page 放進 Buffer Pool 更新,同時還要更新 (uid) 的 Secondary Index ,因此也會把 Secondary Index Leaf Page 放進 Buffer Pool 更新,且除了 Leaf Page 查詢經過的 Page 也會被放進快取。
因此建立太多 Index 不僅會提高寫進 Redo Log 的資料量,還會載入更多資料到記憶體擠壓到空間。
MySQL 為避免單純寫入造成大量 Secondary Index Page 載入到記憶體,使用 Change Buffer 結構來做到延遲更新,同樣是 UPDATE orders SET uid=1, status=1 WHERE id = 2 ,有了 Change Buffer 後,MySQL 只要載入 Clustered Index 的 Leaf Page 和查詢路徑 Page 到 Buffer Pool 更新,同時 Secondary Index 的更新只需要載入查詢路徑 Page 同時定位到 page_no 後,將更改內容和 page_no 寫入 Change Buffer 中,後續若有查詢需要這個 page_no (Leaf Page),才會真的去讀取,並與 Change Buffer 中異動內容 merge,同時 flush process 也會定期把 Change Buffer 內容更新回 B+Tree Page 中。
有了 Change Buffer ,寫入時能減少載入 Secondary Index Leaf Page 的 I/O 跟記憶體資料,當然缺點就是讀取 Secondary Index 時,多了一個從 Change Buffer 中 Merge 的過程,且不適用於 Unique Index 因為必須載入 Leaf Page 檢查是否有衝突。
總結,建立太多 Index 不只影響寫入效能還會影響查詢效能,雖然有 Change Buffer 優化,但只用於 non-unique index,效果可能不明顯。


 iThome鐵人賽
iThome鐵人賽