在完成資料初步介紹後,接下來我們將焦點放在資料結構的檢查與整理上。資料中包含每個縣市在1月到12月的違規土地面積,為方便後續可視化分析,我們將資料轉換為長格式(long format),也就是每筆資料包含「縣市名稱」、「月份」、「違規面積」三個欄位。這種格式便於繪製折線圖、熱力圖,並且能清楚觀察縣市與月份之間的關係。
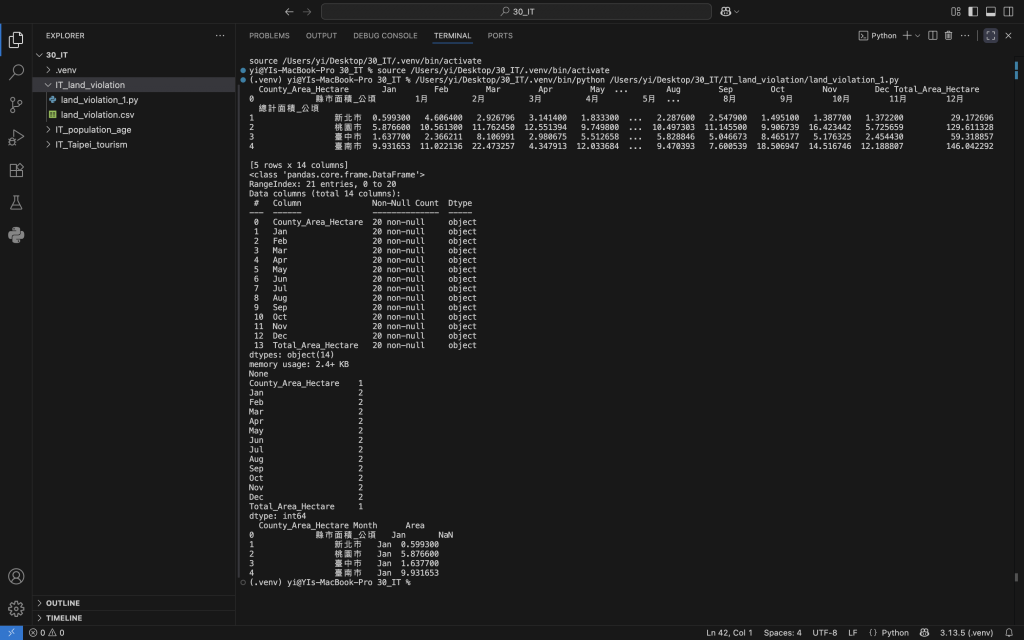
在數據檢查過程中,我們確認月份欄位為數值型態,並且缺失值情況非常少,這意味著資料的完整性良好。透過長格式轉換,我們能夠將原本12個月份欄位整合為一個「月份」欄位與一個「面積」欄位,這種整理方式有助於後續進行多縣市、多月份的比較。
例如,使用pandas的melt函數即可完成這種轉換。完成後,每一列資料代表特定縣市在某個月份的違規土地面積,這為我們的折線圖與熱力圖分析打下基礎。長格式資料的另一個優點是便於統計每個月份的總面積,或計算縣市在年度內的貢獻比例。
資料整理完成後,我們已經能夠進行縣市年度排行、月份趨勢分析以及縣市間比較。透過這個過程,我們對資料結構有了全面理解,也確定後續分析將以長格式資料為核心,確保可視化呈現能夠清楚、直觀地表達縣市與月份之間的關係。
import pandas as pd
# 讀取 CSV 資料
df = pd.read_csv("IT_land_violation/land_violation.csv")
# 檢查資料結構
print(df.head())
print(df.info())
# 月份欄位
months = [
"Jan",
"Feb",
"Mar",
"Apr",
"May",
"Jun",
"Jul",
"Aug",
"Sep",
"Oct",
"Nov",
"Dec",
]
# 將月份欄位轉為數值型態
df[months] = df[months].apply(pd.to_numeric, errors="coerce")
# 檢查缺失值
print(df.isnull().sum())
# 將資料轉換為長格式
df_long = df.melt(
id_vars=["County_Area_Hectare"],
value_vars=months,
var_name="Month",
value_name="Area",
)
# 查看長格式資料
print(df_long.head())


 iThome鐵人賽
iThome鐵人賽