正式將 LLM 平民化的工具 Ollama,在 2023 年的 7 月開始進行測試,在 9 月的時候已經可以在 Linux、WSL 上運作,同時支援 CPU 以及 GPU。一直到 2025 年都還是大部分的開發者在使用的工具,不論是簡單的聊天對話或是使用 AI Agent 做 Coding,幾乎在所有應用上都能看到 Ollama 的身影。
今天會簡單的安裝 Ollama(其實網路上已經一堆教學,但還是形式上走一遍)+ 操作基本的指令,實際運作幾個常見 LLM Model,順便在 Mac 跟只有純 CPU 的筆電上試試看效能如何。
使用 MacOS 或是 Windows 的話,可以直接到官網下載安裝檔,安裝完之後就可以直接使用(右上角會出現可愛的 Ollama 圖案就代表正常運作)。目前在 MacOS 和 Windows 的版本都支援簡易的 GUI 聊天界面。筆者開發主要是使用 Ubuntu,所以只能使用 CLI 的方式來操作。
docker run --rm -it -p 11434:11434 ollama/ollama:0.11.6
成功跑起來後到 http://localhost:11434 如果有看到 Ollama is running 的就代表成功了。
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
筆者目前經常使用的指令有:
pull:下載模型run:運行模型list:列出所有可用的模型rm:刪除模型ollama run llama3.2:3b
>>> hi
How can I assist you today?
/bye 結束對話>>> /bye
Usage:
ollama run MODEL [PROMPT] [flags]
Flags:
--format string Response format (e.g. json)
-h, --help help for run
--hidethinking Hide thinking output (if provided)
--insecure Use an insecure registry
--keepalive string Duration to keep a model loaded (e.g. 5m)
--nowordwrap Don't wrap words to the next line automatically
--think string[="true"] Enable thinking mode: true/false or high/medium/low for supported models
--verbose Show timings for response
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
OLLAMA_NOHISTORY Do not preserve readline history
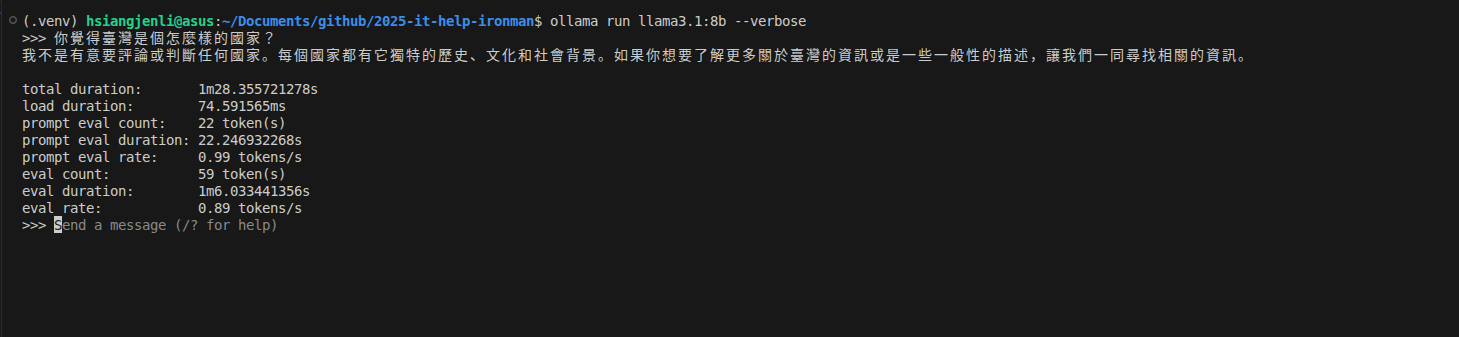
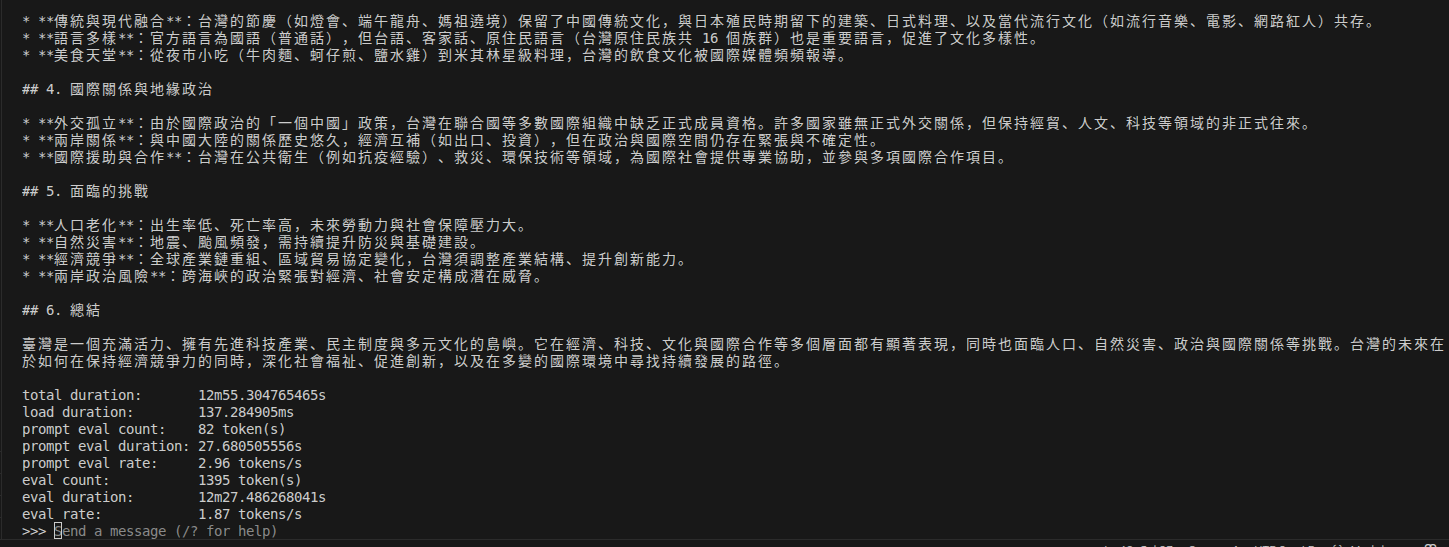
| 模型 | MacOS - M2(24GB RAM) | Ubuntu 24.04 - Intel® Core™ i5-13500H (40GB RAM) |
|---|---|---|
llama3.1:8b |
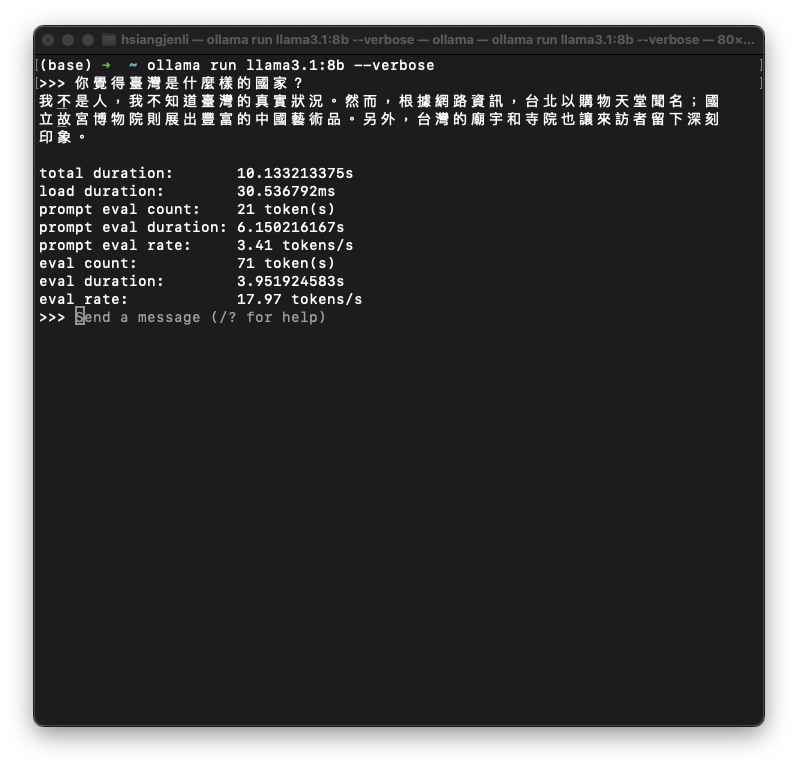
36.71/token/s | 0.89 token/s |
llama3.2:3b |
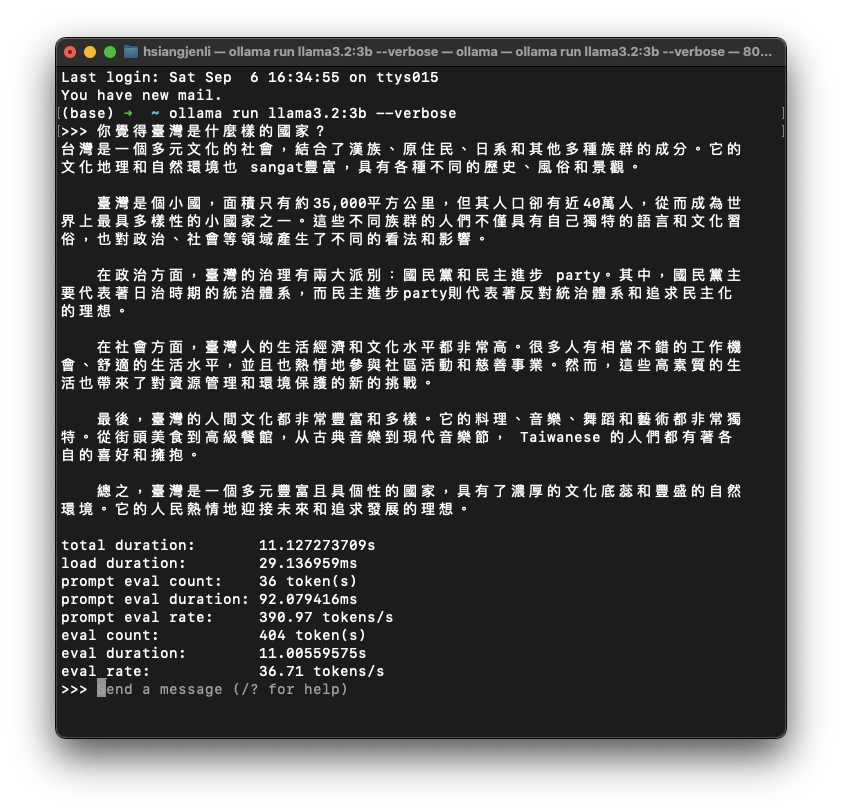
17.97 token/s | 2.02 token/s |
gpt-oss:20b |
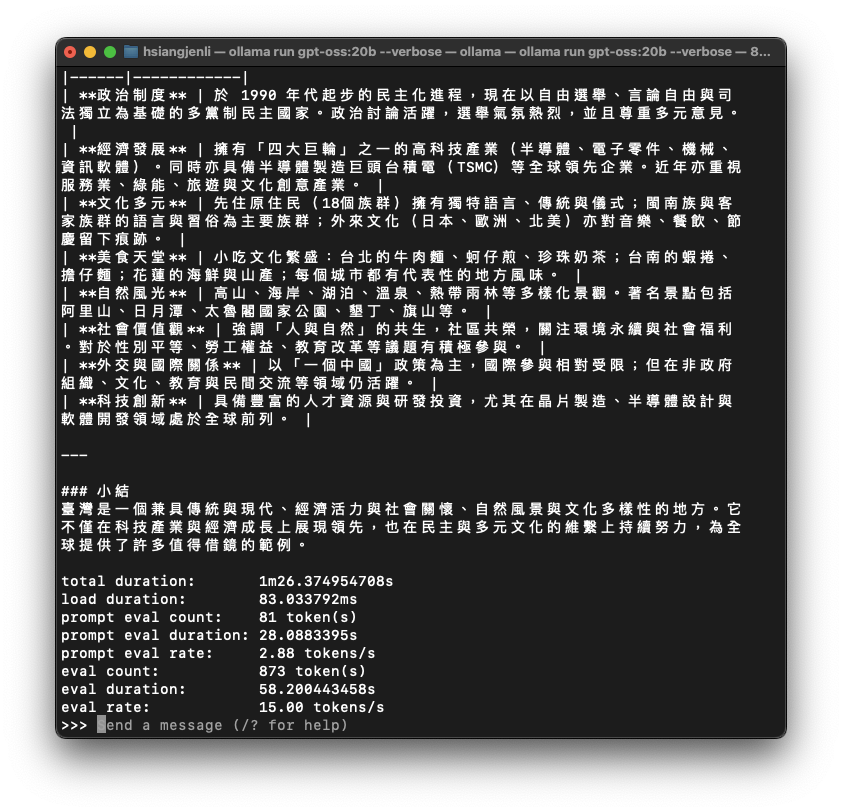
15.00 token/s | 1.87 token/s |
令人意外,
gpt-oss:20b的速度竟然與llama3.1:8b差不多


 iThome鐵人賽
iThome鐵人賽