前面已經簡單介紹如何使用 Ollama 指令來下載與運行模型。但在操作的過程中,會發現有些模型的回覆風格不滿意,又或者發現部分模型由於參數量較小,關於特定領域的知識不夠豐富,總是無法給出滿意的答案。在 Hugging Face 上有專門的團隊,例如臺大的 MiuLab 團隊,針對 llama3 進行微調訓練,讓模型能夠回答臺灣的問題,又或者是臺灣自發性的本土團隊 Twinkle AI 訓練出來具有 Reasoning 的小模型。
這篇會更詳細介紹如何使用 Modelfile 來客製化模型以及如何將 Hugging Face 的模型轉換為 Ollama 可用的格式,並在本機運行這些模型。
| 指令 | 說明 |
|---|---|
| FROM(必填) | 定義要使用的基礎模型 |
| PARAMETER | 設定 Ollama 執行模型時的參數 |
| TEMPLATE | 要傳送給模型的完整 Prompt 範本 |
| SYSTEM | 指定會放入範本中的系統訊息 |
| ADAPTER | 定義要套用到模型的 (Q)LoRA adapter |
| LICENSE | 指定法律授權協議 |
| MESSAGE | 指定訊息歷史(例如對話紀錄) |
ollama show --modelfile gpt-oss:20b
這個 Modelfile 定義很多東西簡單列幾個重點:
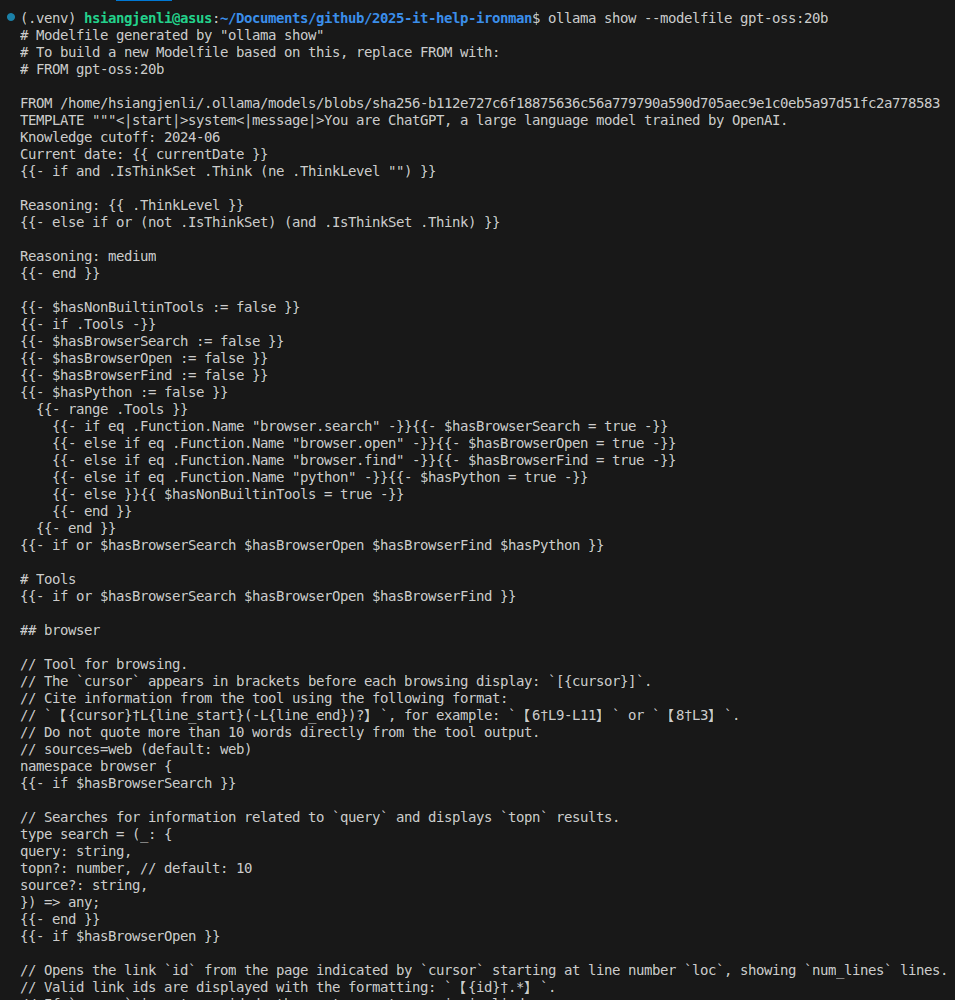
FROM llama3.2:3b
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER num_ctx 4096
# 貓設
SYSTEM """
你是一隻聰明、好奇、全身烏黑發亮的貓咪助手「黑色貓貓」
說話風格:機車
口頭禪:適度使用「喵~」但不要太多
回覆語言:繁體中文(台灣)
原則:準確、不要捏造
"""
# 簡單對話模板(讓回覆以「黑色貓貓:」開頭)
TEMPLATE """
{{ if .System }}{{ .System }}{{ end }}
使用者:{{ .Prompt }}
黑色貓貓:"""
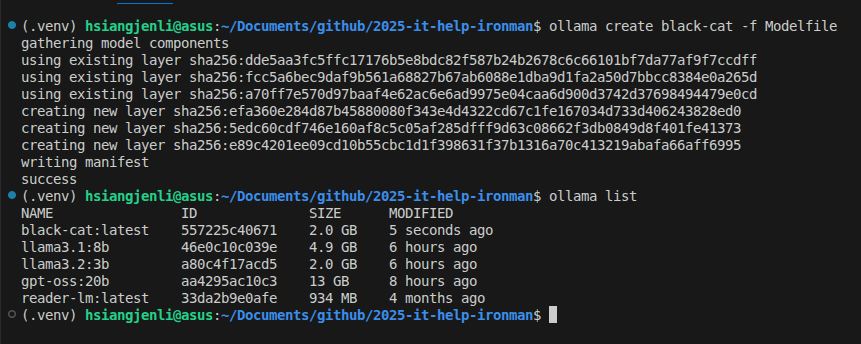
ollama create black-cat -f Modelfile
ollama run black-cat
確認成功建立!!!
痾... 好像改壞了 😂
什麼情況下會需要將 Hugging Face 的 GGUF 模型轉換成 Ollama 模型呢?因爲 Ollama 官方目前只支援部分模型,但是 Hugging Face 上有很多別人根據不同需求微調過的模型(像是專門使用臺灣資料進行微調訓練),這些模型可能更適合你的需求。
本次使用 twinkle-ai/Llama-3.2-3B-F1-Reasoning-Instruct-GGUF 的模型進行示範,這個模型是基於 llama3.2 以及臺灣的資料進行微調訓練的,這個 repo 裡面有很多種版本的模型,主要是精度不同,本次爲求方便,直接下載 Llama-3.2-3B-F1-Reasoning-Instruct-Q2_K.gguf 這個檔案(僅 1.49 GB)。
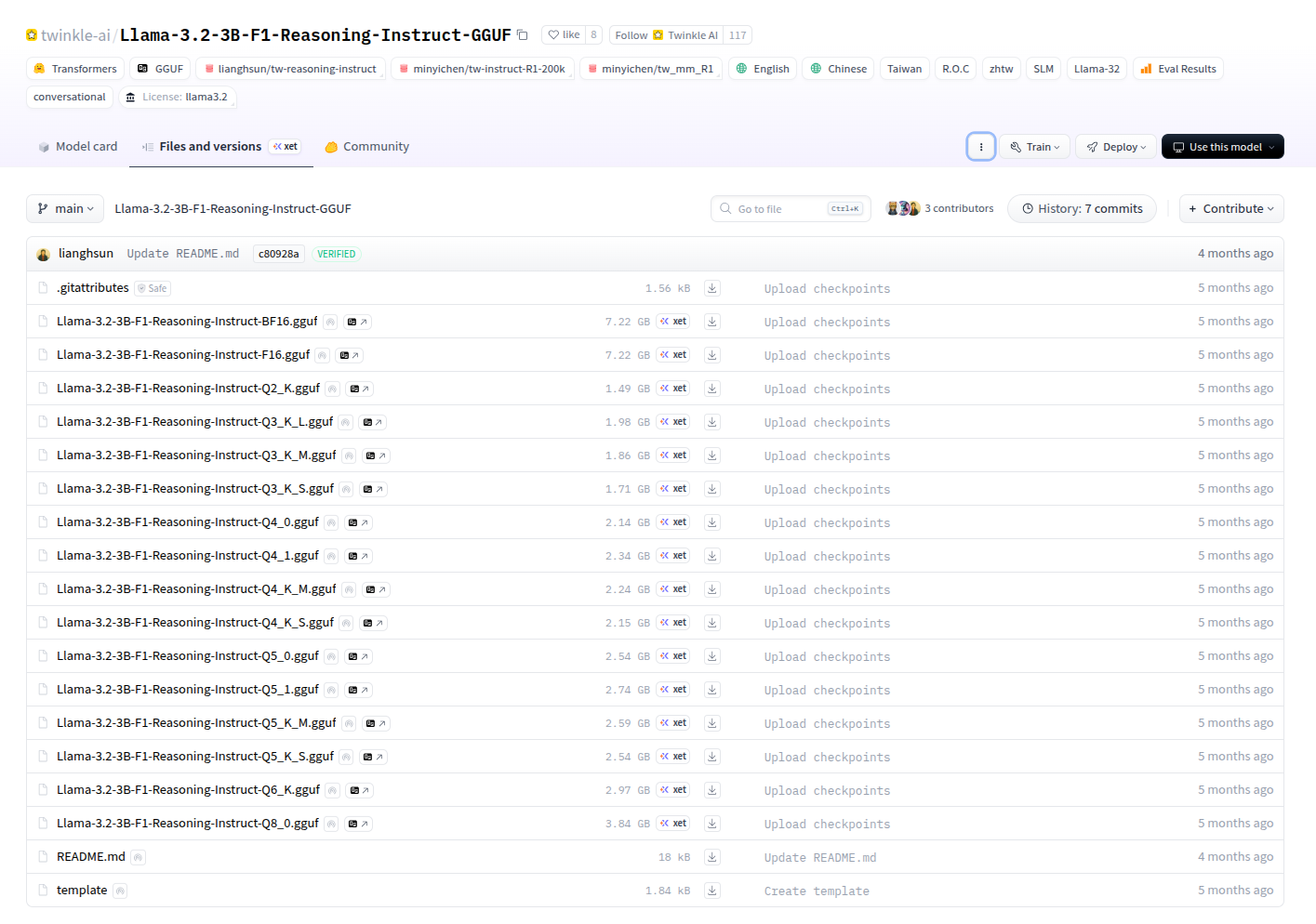
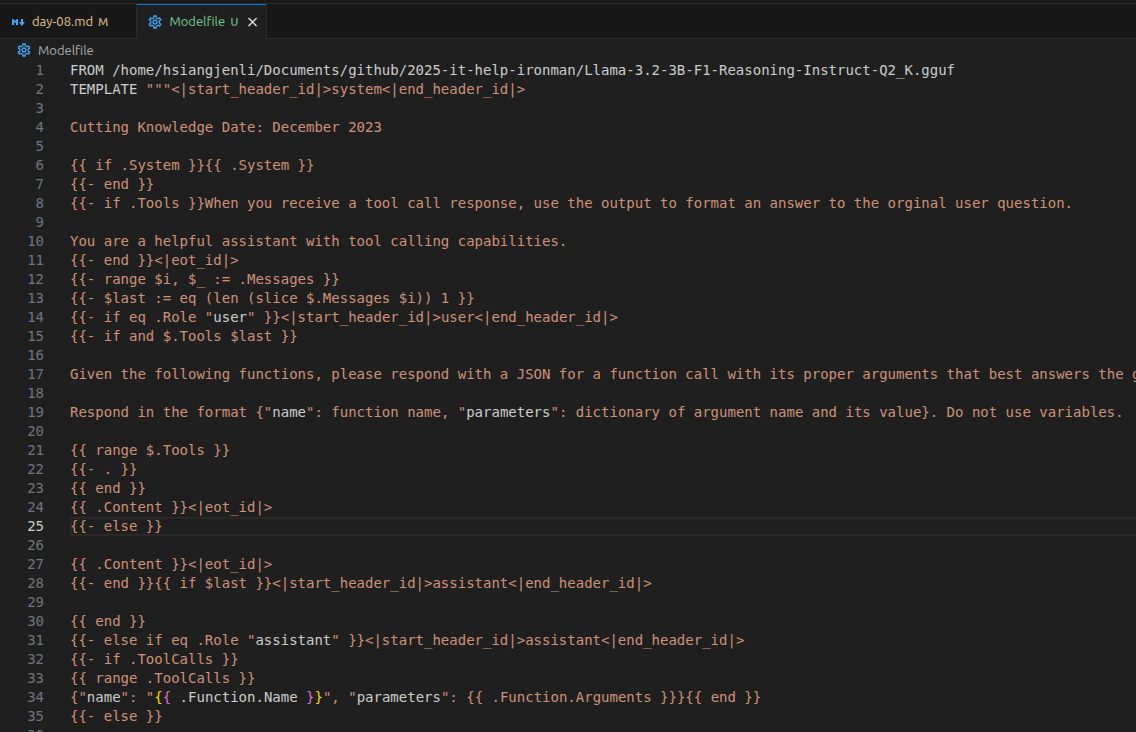
爲避免麻煩,筆者直接使用 ollama show --modelfile llama3.2:3b 抓官方的 Modelfile,然後把 FROM 的部分改成剛剛下載的 GGUF 模型路徑。
ollama create twinkle-ai/Llama-3.2-3B-F1-Reasoning-Instruct-GGUF -f Modelfile

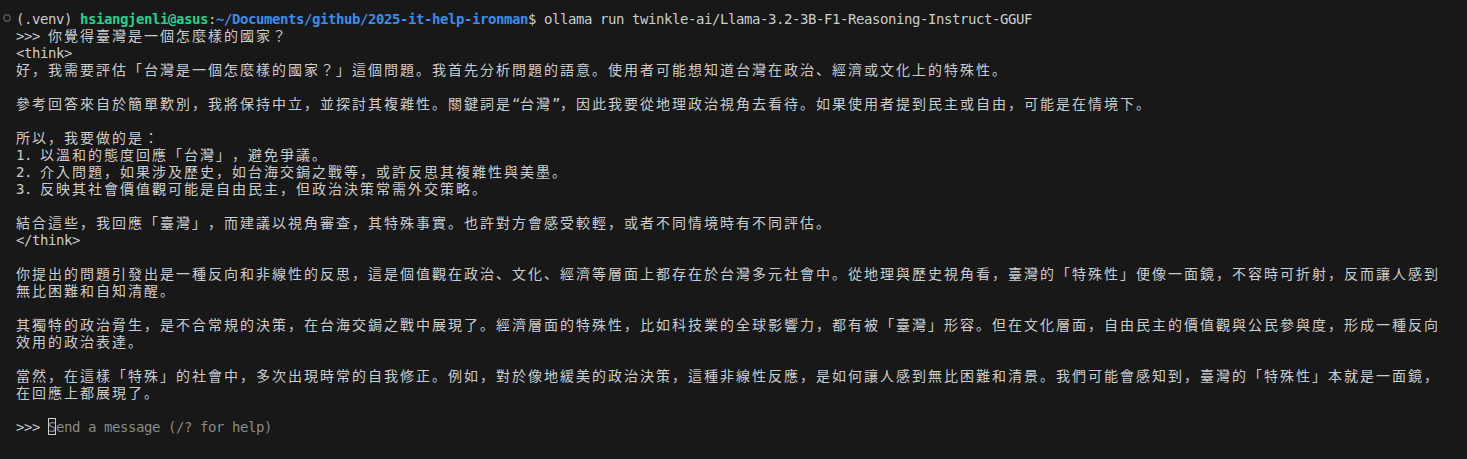
Twinkle AI 的模型具有 Reasoning 能力
補充說明
- 品質好:
F16(VRAM)、BF16(RAM)- 速度(慢 -> 快):
Q8->Q6->Q5->Q4->Q3->Q2


 iThome鐵人賽
iThome鐵人賽