在前一篇我們透過縣市平均值排行,了解到各縣市在整體空氣品質上的差異。不過單看「平均值」仍不足以說明日常生活的真實體驗,因為平均可能會被極端值拉高或拉低。
舉例來說:
若某縣市30天裡有20天是「良好」,但10天是「非常糟」,平均數值可能看起來還好,但實際上居民會經歷多次嚴重污染日。相反地,另一個縣市可能每天都在「普通」等級,看似沒有很乾淨,但也沒有太差。因此,今天我們要將AQI指數轉換成等級,並計算各縣市不同等級的分布比例。
import pandas as pd
import matplotlib.pyplot as plt
# 設定中文字型(避免亂碼)
plt.rcParams["font.family"] = "Heiti TC"
plt.rcParams["axes.unicode_minus"] = False
# 讀取資料
df = pd.read_csv("IT_AQI/AQI.csv")
# 建立 AQI 等級分類
def classify_aqi(value):
if value <= 50:
return "良好"
elif value <= 100:
return "普通"
elif value <= 150:
return "對敏感族群不健康"
elif value <= 200:
return "對所有族群不健康"
elif value <= 300:
return "非常不健康"
else:
return "危害"
df["AQI等級"] = df["aqi"].apply(classify_aqi)
# 計算各縣市 AQI 等級比例
city_aqi_level = df.groupby(["county", "AQI等級"]).size().reset_index(name="count")
# 換算比例
city_total = city_aqi_level.groupby("county")["count"].sum().reset_index(name="total")
city_aqi_level = city_aqi_level.merge(city_total, on="county")
city_aqi_level["比例"] = city_aqi_level["count"] / city_aqi_level["total"]
# 轉換成堆疊條形圖格式
pivot_df = city_aqi_level.pivot(
index="county", columns="AQI等級", values="比例"
).fillna(0)
# 繪製堆疊長條圖
pivot_df.plot(kind="bar", stacked=True, figsize=(12, 6), colormap="tab20")
plt.title("各縣市 AQI 等級分布比例")
plt.xlabel("縣市")
plt.ylabel("比例")
plt.legend(title="AQI 等級", bbox_to_anchor=(1.05, 1), loc="upper left")
plt.tight_layout()
plt.show()
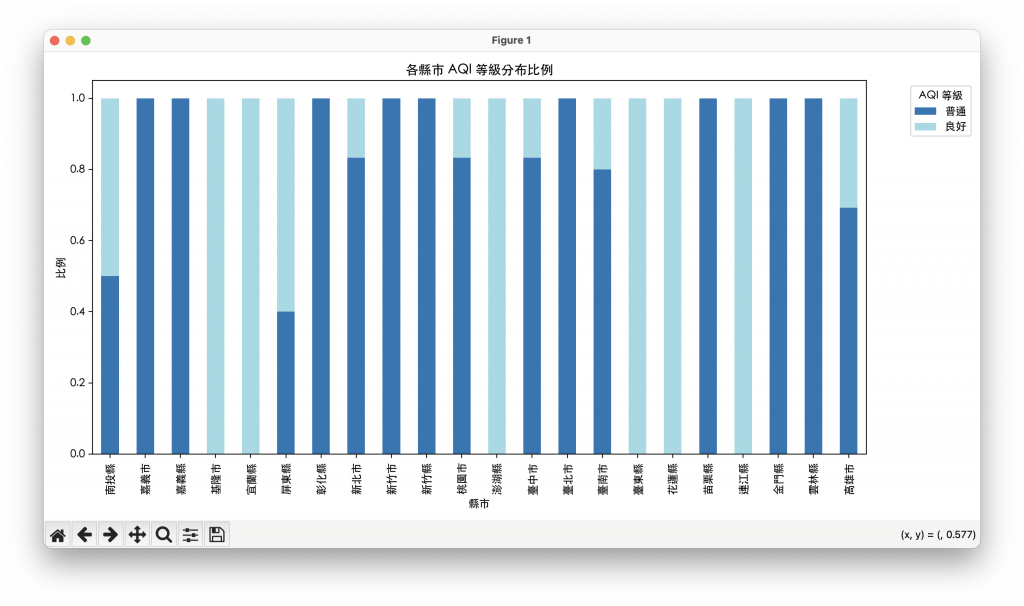
在圖表中,每一個縣市是一根「堆疊長條」,由不同顏色區塊組成,代表該縣市不同AQI等級的比例。
例如:


 iThome鐵人賽
iThome鐵人賽