⚡《AI 知識系統建造日誌》這不是一篇純技術文章,而是一場工程師的魔法冒險。程式是咒語、流程是魔法陣、錯誤訊息則是黑暗詛咒。請準備好你的魔杖(鍵盤),今天,我們要踏入魔法學院的基礎魔法課,打造穩定、可擴展的 AI 知識系統。
延續先前Ollam, RAG 介紹,若你錯過前情,可以先看看這幾篇:
noteserver Container
noteserver:
build:
context: .
dockerfile: ./services/noteservice/Dockerfile.noteserver
image: noteserver:latest
container_name: note
volumes:
- ./note:/app
- ./data/noteserver:/data
- ./docker_cache/hf_cache:/root/.cache/huggingface # avoid space out, you don't need to add this.
ports:
- "8022:8000"
env_file:
- .env
networks:
- langfuse-otel-net
Dockerfile.noteserver
FROM python:3.10-slim
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
git \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY services/noteservice/requirements.txt ./requirements.txt
COPY ./note /app
RUN pip install --no-cache-dir --upgrade pip
RUN pip install --no-cache-dir -r requirements.txt
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]
query_embedding = get_embedding(query)
chunks, sources, msg, arxiv_ids, total_hits = qdrant_client.search(
query=query,
query_vector=query_embedding,
size=system_settings.top_k,
min_score=0.3,
)
if chunks:
reranked = re_ranking(
chunks,
query,
vector_weight=vector_weight,
bm25_weight=bm25_weight,
) # 💡是可選步驟
prompt_data = langchain_client.prompt_builder.create_structured_prompt(
query, reranked, system_settings.user_language
)
resp = langchain_client.llm_context(
final_prompt,
query,
user_language=system_settings.user_language,
system_prompt=system_settings.system_prompt,
)
get_embedding 已經於 Day 7 | 穿越 RAG 魔法迷宮:打造智慧問答系統的秘訣 - RAG Pipeline 跟大家見面了。今天終於可以來看看 其餘幾個如何實現。 將目標轉向 qdrant_client.search rerank
rag pipeplne 說穿了就是 🔮 Embedding → 📚 Qdrant Hybrid Search → ⚖️ Re-ranking → 🏗️ Prompt Build → 🧠 LLM Generate
由於 過了一段時間,魔法也迭代換新了(畢竟連iphone 每年都可以迭代換新了),不過分吧,會將
qdrant_client.search 使用 hybird searchlangchain_client.prompt_builder.create_structured_prompt 換成 ollama_client.prompt_builder.create_structured_prompt 以及 ollama_client.prompt_builder.create_rag_prompt (其實就是 prompt 不同而已)langchain_client.llm_context 蛻變成 ollama_client.generate_rag_answer
🌟 核心魔法流程(RAG Pipeline 更新簡化版)
Query
│
▼
Embedding(get_embedding) → Dense Vector
│
▼
Qdrant Hybrid Search(Dense + BM25)→ Top K Candidates
│
▼
Optional Re-ranking(vector_weight + bm25_weight)→ 精準排序
│
▼
Prompt Builder(ollama_client.create_structured_prompt / create_rag_prompt)
│
▼
LLM Generate Answer(ollama_client.generate_rag_answer)
def retrieval_pipeline(
query: str,
system_settings: SystemSettings,
qdrant_client: QdrantClient,
search_mode: str = "hybrid",
rag_tracer: RAGTracer = None,
trace=None,
categories=None,
) -> Tuple[List[dict], List[str]]:
logger.info("Step 0: Embedding")
query_embedding = get_embedding(query)
logger.info("Step 1: Retrieval")
top_k = max(1, system_settings.top_k) # avoid zero
chunks, sources, msg, arxiv_ids, total_hits = qdrant_client.search(
query=query,
query_vector=query_embedding,
size=top_k * 2, # retrieve more for reranking
min_score=0.3,
hybrid=system_settings.hybrid_search,
categories=categories,
)
if not chunks:
logger.warning("No chunks retrieved, fallback to query as prompt")
return [], []
if not system_settings.reranker_enabled:
logger.info("Reranker disabled, skip reranking step")
return chunks[:top_k], sources
logger.info("Step 2: Re-ranking ")
vector_weight = 0.6
bm25_weight = 0.3
reranked = re_ranking(
chunks,
query,
vector_weight=vector_weight,
bm25_weight=bm25_weight,
)
return reranked[:top_k], sources
# --- Full RAG pipeline ---
async def ask_flow(
query: str,
system_settings: SystemSettings,
ollama_client: OllamaClient,
qdrant_client: QdrantClient,
rag_tracer: RAGTracer,
trace=None,
user_id: str = "anonymous",
model: str = "gpt-oss:20b",
) -> AskResponse:
search_mode = "hybrid" if system_settings.hybrid_search else "dense-only"
chunks, sources = retrieval_pipeline(
query, system_settings, qdrant_client, search_mode, rag_tracer, trace
)
if not chunks:
response = AskResponse(
query=query,
answer="I couldn't find any relevant information in the papers to answer your question.",
sources=[],
chunks_used=0,
search_mode=search_mode,
)
return response
logger.info("Step 4: Build prompt")
try:
prompt_data = ollama_client.prompt_builder.create_structured_prompt(
query, chunks, system_settings.user_language
)
final_prompt = prompt_data["prompt"]
except Exception:
final_prompt = ollama_client.prompt_builder.create_rag_prompt(
query, chunks, system_settings.user_language
)
parsed_response, response = await ollama_client.generate_rag_answer(
query=query,
chunks=chunks,
user_language=system_settings.user_language,
use_structured_output=True,
temperature=system_settings.temperature,
)
return AskResponse(
query=query,
answer=parsed_response.get("answer", "Unable to generate answer"),
sources=sources,
chunks_used=len(chunks),
search_mode=search_mode,
)
在現代資訊檢索系統中,單一的搜尋方法往往難以滿足不同查詢類型的需求。Dense embedding(稠密向量)可以捕捉語義,讓使用者即使查詢與文件中使用不同詞彙,也能找到相關內容;而傳統的 keyword-based 方法(如 Bag-of-Words、TFIDF、BM25)在精確匹配和特殊名稱識別上仍具有不可替代的優勢。本段落介紹如何在 Qdrant 中實現混合搜尋(Hybrid Search),同時利用稠密向量與稀疏向量的優勢。
一句話 : **Hybrid Search(混合搜尋)**是一種同時結合 向量搜尋(Vector Search) 與 傳統文字搜尋(Text Search) 的搜尋策略。
我們來談 Hybrid Search(混合搜尋)。我會從概念到實作都說清楚,並且跟我現在用的 Qdrant 範例做連結。
稀疏向量(Sparse Vectors)
傳統的基於關鍵字的檢索,也可以視為向量搜尋,只不過這些向量大部分維度為 0,即稀疏向量。向量的每個非零維度對應字典中某個詞的出現。稀疏向量的優勢在於:
BM25
BM25(Best Matching 25)是經典的稀疏向量方法,基於統計模型,不涉及神經網路,因此非常快速輕量,常作為搜尋基準。
BM25 的核心公式包含:
Dense 主要抓語意,Sparse 精確匹配,Hybrid 則兼顧兩者。

| 特性 / 搜尋方式 | Dense Vector Search (Embedding) | Sparse Search (BM25 / TF-IDF) | Hybrid Search (Dense + Sparse) |
|---|---|---|---|
| 原理 | 文字向量化 → 比較語意相似度 | 傳統文字檢索 → 關鍵字匹配 | 同時使用語意向量 + 關鍵字匹配,結果融合 |
| 優點 | 抓語意相關、關鍵字不同也能找到答案 | 精確匹配關鍵字、處理專有名詞或代碼有效 | - 結合雙方優勢、語意 + 精確匹配 |
| 缺點 | 精確字面匹配差、需要向量模型 | 無法捕捉語意相似、 容易漏掉同義詞 | - 較複雜、需要融合策略與計算成本 |
| 排序方式 | Cosine / Dot-product 相似度 | BM25 分數 | Dense + Sparse 結果融合 (如 RRF) |
| 適合場景 | 問答系統、語意搜索、相似文件查找 | 文件檢索、專有名詞檢索、精確匹配 | 大型知識庫、RAG pipeline、LLM 上下文準備 |
對 Day 5|資料的家:MinIO , Qdrant, PostgreSQL 的故事 — 文件與資料庫 的 Qdrant 施展小魔法 修改了一下 qdrant_client.search 使用 hybird search ,來展開談談吧
qdrant_client = QdrantClient("http://localhost:6333")
qdrant_client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config={
"dense": models.VectorParams(
size=768,
distance=models.Distance.COSINE,
),
},
sparse_vectors_config={
"bm25": models.SparseVectorParams(
modifier=models.Modifier.IDF,
)
},
)
for chunk_idx, chunk in enumerate(chunks):
point = models.PointStruct(
id=uuid.uuid4().hex,
vector={
# dense embedding 使用指定模型 all-mpnet-base-v2
"dense": vector, # 自己計算的向量
# sparse embedding (BM25) 自動計算
"bm25": models.Document(
text=chunk,
model="Qdrant/bm25",
),
},
payload={
**metadata,
"text": chunk,
"chunk_idx": chunk_idx,
},
)
points.append(point)
qdrant_client.upsert(
collection_name=COLLECTION_NAME, points=batch_points
)
query_vector 這邊使用自己的 embedding 。雖然models.Document 會自動幫我 做 Vector Embedding,但是只限一些 hugging face 的embedding模型
query_vector = embedding(query)
query_result = self.client.query_points(
collection_name=self.settings.COLLECTION_NAME,
prefetch=[
models.Prefetch(query=query_vector, using="dense", limit=5 * size),
models.Prefetch(
query=models.Document(
text=query,
model="Qdrant/bm25",
),
using="bm25",
limit=5 * size,
),
],
# Fusion query enables fusion on the prefetched results
query=models.FusionQuery(fusion=models.Fusion.RRF),
limit=size,
with_payload=True,
).points
Prefetch 的 using="dense" → 語意向量搜尋。Prefetch 的 using="bm25" → 傳統文字搜尋。FusionQuery(fusion=RRF) → 將兩個搜尋結果融合,排序出最終結果。RRF = Reciprocal Rank Fusion,一種融合多個搜尋結果排序的方法。
敏感的你可能觀察到 Qdrant 的 query_points 已經會回傳 排序好的結果(不論是 dense-only 或 hybrid with RRF),那為什麼還要額外做 re_ranking?
Qdrant 幫你快速抓 Top-K 候選,Re-rank 才是讓 LLM 看見真正最 relevant 資料的關鍵。
👉 也就是說,當你呼叫 Qdrant,得到的 points 已經是 依照 RRF 或某一種策略排序的。
原因在於 控制權 和 策略細緻化:
自訂權重
Qdrant 的 RRF 是一種 rank fusion,並不是「可調權重」的融合。
RRF = Reciprocal Rank Fusion,本質上是依照排名位置加分,公式是
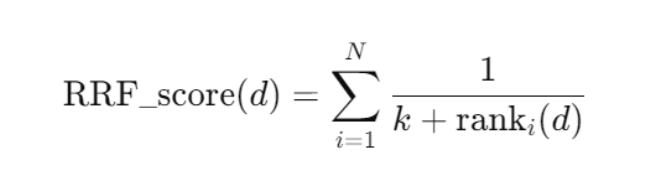
(每個檢索系統的影響力相同)
這是 RRF 沒有提供的功能,所以才需要 後處理 re-ranking。
加入更多訊號
除了 Qdrant 原本的分數,你可能還想引入:
實驗迭代
透過自己 re-ranking,可以隨時更換公式,而不用依賴 Qdrant 內建的 fusion 模式。
通常會有兩層 ranking:
Retriever ranking (Qdrant)
Reranker ranking (本地 re-ranking)
vector_weight = 0.6, bm25_weight = 0.3,就是想要更細緻地控制 dense 與 bm25 的影響力。from typing import Any, List, Dict
import jieba
from rank_bm25 import BM25Okapi
def re_ranking(
chunks: List[Dict[str, Any]],
query: str,
vector_weight: float = 0.6,
bm25_weight: float = 0.3,
field_weights: dict = None,
) -> List[Dict[str, Any]]:
"""
Hybrid reranking: vector similarity + BM25 text matching + 欄位加權
chunks: list of payload dict,需包含 text/title/abstract 與向量相似度 score
field_weights: 欄位權重,例如 {'text':1.0, 'title':0.8, 'abstract':0.5}
"""
if field_weights is None:
field_weights = {"text": 1.0, "title": 0.8, "abstract": 0.5}
query_tokens = list(jieba.cut(query.lower()))
scored_chunks = []
for chunk in chunks:
# 1️⃣ Vector similarity
vector_score = chunk.get("score", 1.0) # 假設 retrieval 已給向量相似度
# 2️⃣ BM25 score
bm25_total = 0.0
for field, weight in field_weights.items():
content = chunk.get(field, "")
if not content:
continue
tokens = list(jieba.cut(content.lower()))
bm25 = BM25Okapi([tokens])
score = bm25.get_scores(query_tokens)[0] # 單篇文件的 BM25 分數
bm25_total += weight * score
# 3️⃣ Combine scores
total_score = vector_weight * vector_score + bm25_weight * bm25_total
chunk_with_score = chunk.copy()
chunk_with_score["vector_score"] = vector_score
chunk_with_score["bm25_score"] = bm25_total
chunk_with_score["total_score"] = total_score
scored_chunks.append((total_score, chunk_with_score))
# 排序
scored_chunks.sort(key=lambda x: x[0], reverse=True)
reranked_chunks = [chunk for score, chunk in scored_chunks]
return reranked_chunks
# {
# "id": "doc2",
# "title": "深度學習應用",
# "abstract": "卷積神經網路在影像辨識的應用。",
# "text": "包含 CNN、RNN、Transformer 的案例。",
# "score": 0.75,
# "vector_score": 0.75, # 向量分數
# "bm25_score": 2.1, # BM25 欄位加權後分數
# "total_score": 1.38 # 最終分數 (排序依據)
# }
✅ 結論
Qdrant 排序提供一個 快速、通用的初始 ranking。
今天的魔法課帶大家認識了 Qdrant Hybrid Search(提升 recall) 與 自訂 re-ranking(提升 precision),兩者搭配才能讓 LLM 吃到最 relevant 的知識
明天再來討論 build_prompt -> generate。必經魔法需要CD 時間。
from typing import Dict, List, Optional
from config import Settings
from logger import AppLogger
from qdrant_client import QdrantClient as Client
from qdrant_client import models
from qdrant_client.http.exceptions import UnexpectedResponse
logger = AppLogger(__name__).get_logger()
class QdrantClient:
def __init__(self, settings: Settings):
self.settings = settings
self.client = Client(
url=settings.QDRANT_URL,
timeout=60,
)
def create_collection(self):
try:
self.client.create_collection(
collection_name=self.settings.COLLECTION_NAME,
vectors_config={
"dense": models.VectorParams(
size=768,
distance=models.Distance.COSINE,
),
},
sparse_vectors_config={
"bm25": models.SparseVectorParams(
modifier=models.Modifier.IDF,
)
},
)
print(
f"✅ Qdrant collection `{self.settings.COLLECTION_NAME}` created successfully."
)
except UnexpectedResponse as e:
# 如果已存在就當作正常,不丟錯
if "already exists" in str(e):
logger.info(
f"ℹ️ Qdrant collection `{self.settings.COLLECTION_NAME}` already exists, skipping creation."
)
else:
raise # 其他 UnexpectedResponse 直接丟出
def get_collections(self):
return self.client.get_collections()
def search(
self,
query: str,
query_vector: Optional[List[float]] = None,
size: int = 10,
categories: Optional[List[str]] = None,
min_score: float = 0.25,
hybrid: bool = True,
) -> tuple[List[Dict], List[str], str, List[str], int]:
# Step 1: 建立 Qdrant filter
must_conditions = []
if categories:
for cat in categories:
if cat:
must_conditions.append(
models.FieldCondition(
key="categories", match=models.MatchValue(value=cat)
)
)
filter_cond = models.Filter(must=must_conditions) if must_conditions else None
logger.info(f"filter_cond {filter_cond}")
# Step 2: Qdrant search
# Hybrid search:向量 + filter
if hybrid:
# 🚀 Hybrid search (dense + sparse)
logger.info("Hybrid search (dense + sparse)")
query_result = self.client.query_points(
collection_name=self.settings.COLLECTION_NAME,
prefetch=[
models.Prefetch(query=query_vector, using="dense", limit=5 * size),
models.Prefetch(
query=models.Document(
text=query,
model="Qdrant/bm25",
),
using="bm25",
limit=5 * size,
),
],
# Fusion query enables fusion on the prefetched results
query=models.FusionQuery(fusion=models.Fusion.RRF),
limit=size,
with_payload=True,
)
else:
logger.info("Dense-only search")
# 🚀 Dense-only search
query_result = self.client.query_points(
collection_name=self.settings.COLLECTION_NAME,
query=query_vector,
using="dense",
limit=size,
with_payload=True,
)
# Extract essential data for LLM
chunks = []
arxiv_ids = []
sources = set()
msg = ""
for hit in query_result.points:
if hit.score < min_score:
continue
payload = hit.payload
logger.info(f"payload {payload}")
arxiv_id = payload.get("arxiv_id", "")
# Minimal chunk data for LLM
chunks.append(
{
"arxiv_id": arxiv_id,
"chunk_text": payload.get("text", payload.get("abstract", "")),
}
)
if arxiv_id:
arxiv_ids.append(arxiv_id)
arxiv_id_clean = arxiv_id.split("v")[0] if "v" in arxiv_id else arxiv_id
sources.add(f"https://arxiv.org/pdf/{arxiv_id_clean}.pdf")
info_str = f"title: {payload['title']} \n Score: {hit.score}\n arxiv_id : {payload['arxiv_id']}"
msg += f"Retrieved {len(chunks)} chunks from collection {self.settings.COLLECTION_NAME}\n{info_str}\n\n\n"
logger.info(
f"search found {len(chunks)} chunks, {len(sources)} sources\n\n with filter {filter_cond}\n\n"
)
return chunks, list(sources), msg, arxiv_ids, len(query_result.points)


 iThome鐵人賽
iThome鐵人賽