⚡《AI 知識系統建造日誌》這不是一篇純技術文章,而是一場工程師的魔法冒險。程式是咒語、流程是魔法陣、錯誤訊息則是黑暗詛咒。請準備好你的魔杖(鍵盤),今天,我們要踏入魔法學院的基礎魔法課,打造穩定、可擴展的 AI 知識系統。
今天,我的探險目標是「將 RAG 的魔法力量封裝成 API」,讓前端開發者也能輕鬆召喚知識精靈。想像自己站在魔法工坊裡,每一個 endpoint 就是魔法水晶球,每一次呼叫都能從遠方召回智慧的碎片。
在上一天的冒險裡,我們已經探索了 RAG pipeline。今天,我要把它們組合成一個完整的 FastAPI 服務,讓 RAG 變成可即時呼叫的魔法道具。目標清單如下:
from dependencies import (
OllamaDep,
QdrantDep,
SettingsDep,
UserCacheDep,
)
# REST API routers
@ask_router.post("/api/v1/ask", response_model=AskResponse)
@observe_api
async def ask_question(
request: Query,
ollama_client: OllamaDep,
qdrant_client: QdrantDep,
user_cache_client: UserCacheDep,
langfuse_tracer: LangfuseDep,
settings: SettingsDep,
) -> AskResponse:
q = request.text.strip()
logger.info("ask_question %s", q)
rag_tracer = RAGTracer(langfuse_tracer)
start_time = time.time()
system_settings = user_cache_client.get_redis_system_setting(request.user_id)
top = system_settings.top_k
lang = system_settings.user_language
logger.info("ask_question %s, top_k=%s, user_language=%s", q, top, lang)
ask_r = AskRequest(
user_id=request.user_id,
query=request.text,
top_k=system_settings.top_k,
use_hybrid=True,
model=settings.MODEL_NAME,
)
response = await ask_flow(
query=q,
system_settings=system_settings,
ollama_client=ollama_client,
qdrant_client=qdrant_client,
user_id=ask_r.user_id,
model=ask_r.model,
rag_tracer=rag_tracer,
trace=trace,
)
return response
ask_flow 是 RAG 核心流程,負責檢索 chunks、建 prompt 並呼叫 LLM 生成答案。
詳見 Day14|RAG 魔法課 (上):Hybrid Search 與 Re-ranking 完整實戰
: 後面接的是型態 pydantic
Q: RAG 如何保證多用戶隔離?
A:透過 user_id 讀取使用者設定與 cache。
詳細可參考 http://localhost:8022/docs#/
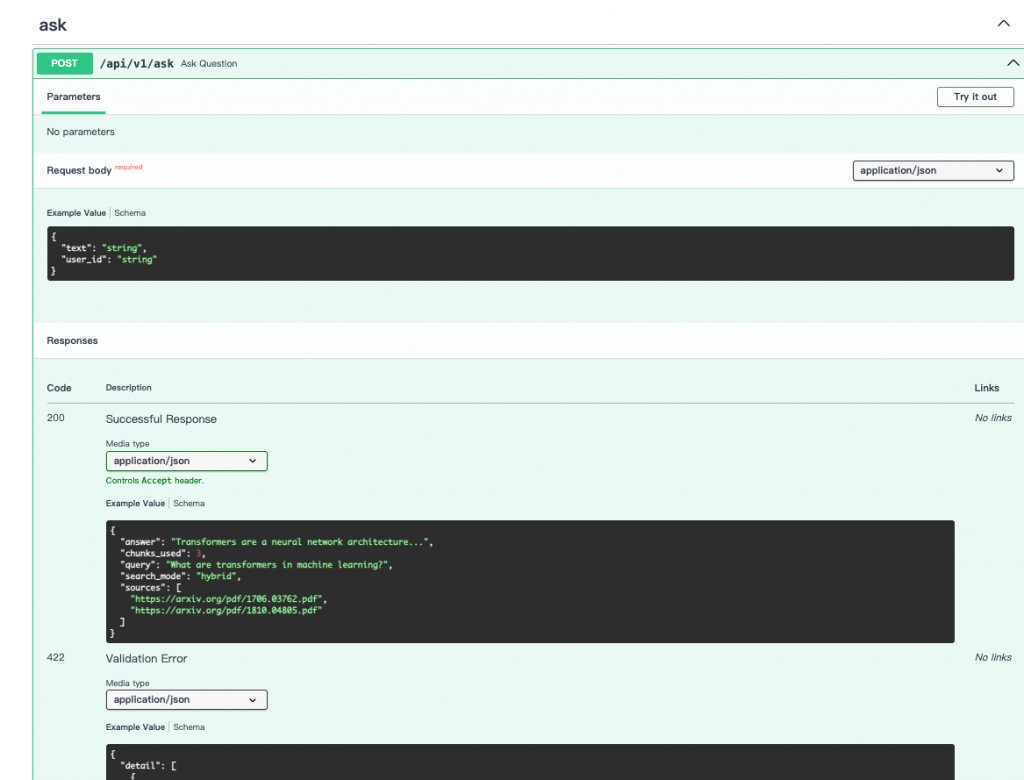
class Query(BaseModel):
text: str
user_id: str
這裡會使用 user_id 讀取使用者設定,例如語言、top_k、搜尋模式。
不知道有沒有發現圖片只有顯示 text 與 user_id 參數,其餘參數皆透過依賴注入自動注入:
ollama_client: OllamaDep,
qdrant_client: QdrantDep,
settings: SettingsDep,
user_cache_client: UserCacheDep,
class AskResponse(BaseModel):
"""Response model for RAG question answering."""
query: str = Field(..., description="Original user question")
answer: str = Field(..., description="Generated answer from LLM")
sources: List[str] = Field(..., description="PDF URLs of source papers")
chunks_used: int = Field(..., description="Number of chunks used for generation")
search_mode: str = Field(..., description="Search mode used: bm25 or hybrid")
再來看 Streaming endpoint 先來討論 FastAPI StreamingResponse 與 SSE(Server-Sent Events)
Takes an async generator or a normal generator/iterator and streams the response body.
StreamingResponse 是 FastAPI 提供的一種 流式回應,適合用於:
它的核心就是 傳入一個可迭代物件(generator 或 async generator),FastAPI 會邊生成邊傳送給客戶端。
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import time
app = FastAPI()
def generate_numbers():
for i in range(5):
yield f"{i}\n"
time.sleep(1) # 模擬耗時
@app.get("/numbers")
def get_numbers():
return StreamingResponse(generate_numbers(), media_type="text/plain")
在處理長時間生成的模型輸出(例如 LLM token-by-token 回應)時,FastAPI 的 StreamingResponse 非常適合。搭配 SSE(Server-Sent Events)可以實現前端即時更新 UI。
基本概念
StreamingResponse:FastAPI 提供的響應類型,可以逐步產生資料,而不是一次性返回完整資料。
data: {"chunk": "Hello"}\n\n
當你想傳遞結構化資料(例如 chunk 與 done 標記)時:
data: {"chunk": "RAG ", "done": false}
data: {"chunk": "is powerful.", "done": true}
於是 將 標準 SSE (Server-Sent Events) + FastAPI StreamingResponse
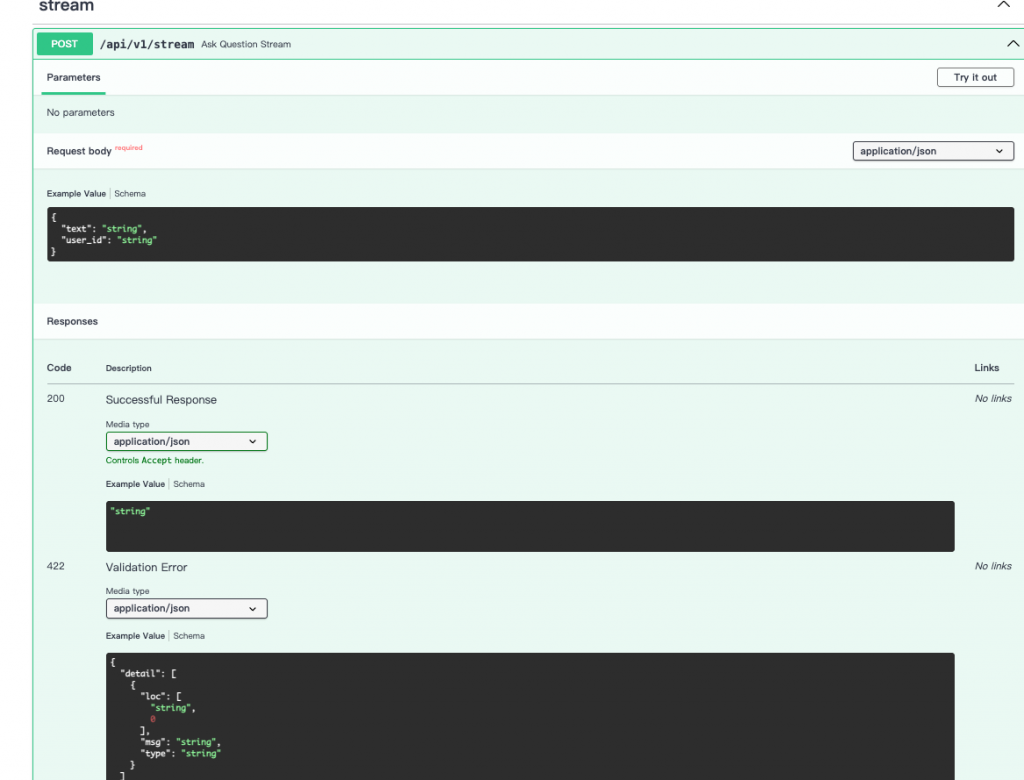
@stream_router.post("/api/v1/stream")
async def ask_question_stream(
request: Query,
ollama_client: OllamaDep,
qdrant_client: QdrantDep,
user_cache_client: UserCacheDep,
langfuse_tracer: LangfuseDep,
):
q = request.text.strip()
logger.info("ask_question_stream %s", q)
system_settings = user_cache_client.get_redis_system_setting(request.user_id)
top = system_settings.top_k
lang = system_settings.user_language
logger.info("ask_question_stream %s, top_k=%s, user_language=%s", q, top, lang)
return StreamingResponse(
rag_stream(
ollama_client=ollama_client,
qdrant_client=qdrant_client,
query=q,
system_settings=system_settings,
user_id=request.user_id,
langfuse_tracer=langfuse_tracer,
),
media_type="text/event-stream", # 前端 fetch 會逐段讀取
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
},
)
rag_stream 必須是一個 async generator,每 yield 一個事件
async def rag_stream(
ollama_client: OllamaClient,
qdrant_client: QdrantClient,
query: str,
system_settings: SystemSettings,
langfuse_tracer: LangfuseTracer,
user_id: str = "anonymous",
categories: List[str] = None,
) -> str:
...
async for chunk in ollama_client.generate_stream(
prompt=final_prompt, temperature=system_settings.temperature
):
if chunk.get("response"):
text_chunk = chunk["response"]
yield f"data: {json.dumps({'chunk': text_chunk})}\n\n"
if chunk.get("done", False):
yield f"data: {json.dumps({'answer': full_response, 'done': True})}\n\n"
break
...
main.py 與服務啟動
FastAPI lifespan 管理服務啟動/關閉
設定允許的來源
註冊路由,告訴系統各 endpoint 所在位置
import os
from contextlib import asynccontextmanager
from api.routers import chat_history, ping, setting, user
from api.routers.ask import ask_router, stream_router
from config import get_settings
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from logger import AppLogger
from services.cache.factory import make_all_cache_clients
from services.langchain.factory import make_langchain_client
from services.minio.factory import make_minio_client
from services.ollama.factory import make_ollama_client
from services.qdrant.factory import make_qdrant_client
from starlette.concurrency import run_in_threadpool
logger = AppLogger(__name__).get_logger()
@asynccontextmanager
async def lifespan(app: FastAPI):
"""
Lifespan for the API.
# 啟動前
yield
# 關閉前
"""
logger.info("Starting RAG API...")
settings = get_settings()
app.state.settings = settings
# Initialize search service
qdrant_client = make_qdrant_client()
app.state.qdrant_client = qdrant_client
# Initialize other services (kept for future endpoints and notebook demos)
# app.state.arxiv_client = make_arxiv_client()
# app.state.pdf_parser = make_pdf_parser_service()
# app.state.embeddings_service = make_embeddings_service()
app.state.minio_client = make_minio_client()
app.state.ollama_client = make_ollama_client()
app.state.langchain_client = make_langchain_client()
app.state.langfuse_tracer = make_langfuse_tracer()
_clients = make_all_cache_clients()
app.state.cache_user_client = _clients["user"]
app.state.cache_paper_client = _clients["paper"]
logger.info("🚀 startup_event triggered")
await run_in_threadpool(app.state.qdrant_client.create_collection)
logger.info("✅ note_collection ready")
await run_in_threadpool(app.state.minio_client.create_note_bucket)
logger.info("✅ note_bucket ready")
logger.info("API ready")
yield
# Cleanup
logger.info("API shutdown complete")
app = FastAPI(
title="Note for arXiv Paper",
description="Personal arXiv CS.AI paper curator with RAG capabilities",
version=os.getenv("APP_VERSION", "0.1.0"),
lifespan=lifespan,
)
origins = ["http://apiGateway:8000"] # importance 請保護好自己
# 設定允許的來源
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# REST API routers
app.include_router(ask_router) # RAG question answering with LLM
app.include_router(stream_router) # Streaming RAG responses
app.include_router(user.router, tags=["user"])
app.include_router(setting.router, tags=["setting"])
app.include_router(chat_history.router, tags=["chat_history"])
app.include_router(ping.router, tags=["Health"])
友善版
api/ # FastAPI endpoints & schemas
services/ # 核心業務邏輯與外部服務整合
db/ # 資料庫 CRUD 與存取
arxiv_rag_pipeline.py # RAG pipeline 核心
main.py # FastAPI 啟動入口
完整版
├── api/ # FastAPI API layer
│ ├── auto_metrics.py # Automatic metrics endpoints or collection
│ ├── routers/ # API routers (endpoint definitions)
│ │ ├── ask.py # Endpoint to handle user "ask" requests (RAG queries)
│ │ ├── chat_history.py # Endpoint to fetch or manage chat history
│ │ ├── notes.py # Endpoint to manage user notes
│ │ ├── ping.py # Health check endpoint
│ │ ├── setting.py # Endpoint to manage system/user settings
│ │ └── user.py # Endpoint to manage user information
│ └── schemas/ # Pydantic schemas for request/response validation
│ ├── ask.py
│ ├── health.py
│ ├── history.py
│ ├── ollama.py
│ ├── query.py
│ ├── SystemSetting.py
│ └── user.py
│
├── arxiv_rag_pipeline.py # Main RAG pipeline for embedding, search from qdrant, build prompt, llm
├── config.py # Configuration settings (API URLs, DB connections, environment variables)
├── dependencies.py # FastAPI dependencies (e.g., DB sessions, authentication)
├── exceptions.py # Custom exception classes
├── __init__.py # Package initialization
├── logger.py # Centralized logging utilities
├── main.py # FastAPI application entry point
│
├── services/ # Core service layer
│ ├── cache/ # Caching utilities
│ │ ├── client.py
│ │ ├── factory.py
│ │ ├── metrics.py # Redis metrics utilities
│ ├── langchain/ # LangChain integration
│ │ ├── client.py
│ │ ├── factory.py
│ ├── langfuse/ # Langfuse client for tracing/logging LLM usage
│ │ ├── client.py
│ │ ├── factory.py
│ │ └── tracer.py
│ ├── minio/ # MinIO client for PDF or asset storage
│ │ ├── client.py
│ │ ├── factory.py
│ ├── ollama/ # Ollama LLM client
│ │ ├── client.py
│ │ ├── factory.py
│ ├── prompts/
│ │ └── rag_system.txt # Prompt template for RAG pipeline
│ │ └── prompts.py # Prompt management utilities
│ ├── qdrant/ # Qdrant vector DB integration
│ │ ├── client.py
│ │ ├── factory.py
│ │ └── sample_qdrant.py
│ ├── fetch_chat.py # Fetch chat history or conversation context
│ ├── rerank.py # Reranking retrieved results
│ ├── store_chat_and_usage.py # Store chat history and usage metrics
│ ├── system_setting.py # System configuration utilities
│ ├── user_info.py # User information utilities
│ ├── estimate_tokens.py # Estimate token usage for LLM calls
│ ├── embedding.py # Functions for generating embeddings from paper text
│ ├── evaluate.py # Evaluation utilities (e.g., accuracy, relevance scoring)
│
├── db/ # DB layer
│ ├── crud/ # CRUD operations for FastAPI endpoints
│ │ ├── chat_history.py
│ │ ├── note.py
│ │ ├── setting.py
│ │ └── user.py
│ ├── __init__.py
│ ├── postgres.py # PostgreSQL connection and utilities
│ └── storage_metrics.py # General storage metrics
│
└── tests/
└── test_ollama_client.py # Unit tests for Ollama client integration
API / Routers Layer (api/routers/)
api/schemas/)Services Layer (services/)
services/cache/)Pipeline Layer (arxiv_rag_pipeline.py)
Storage / Repositories Layer (db/)
db/crud/)storage_metrics.py, cache/metrics.py)Models & Schemas (db/postgresql.py, api/schemas/)
async def rag_stream(
ollama_client: OllamaClient,
qdrant_client: QdrantClient,
query: str,
system_settings: SystemSettings,
langfuse_tracer: LangfuseTracer,
user_id: str = "anonymous",
categories: List[str] = None,
) -> str:
try:
rag_tracer = RAGTracer(langfuse_tracer)
start_time = time.time()
search_mode = "hybrid" if system_settings.hybrid_search else "dense-only"
with rag_tracer.trace_request(user_id, query) as trace:
chunks, sources = retrieval_pipeline(
query,
system_settings,
qdrant_client,
search_mode,
rag_tracer,
trace,
categories,
)
if not chunks:
yield f"data: {json.dumps({'answer': 'No relevant information found.', 'sources': [], 'done': True})}\n\n"
logger.info("Step 4: Build prompt")
# context = build_prompt(query, reranked)
with rag_tracer.trace_prompt_construction(trace, chunks) as prompt_span:
final_prompt = ollama_client.prompt_builder.create_rag_prompt(
query, chunks, system_settings.user_language
)
rag_tracer.end_prompt(prompt_span, final_prompt)
logger.info(
f"Step 5: LLM stream generation with final_prompt = {final_prompt}"
)
with rag_tracer.trace_generation(trace, "hybrid", final_prompt) as gen_span:
full_response = ""
final_chunk = None
async for chunk in ollama_client.generate_stream(
prompt=final_prompt, temperature=system_settings.temperature
):
# 每一個 chunk 是模型生成的一部分文字
logger.info("chunk: %s", chunk)
if chunk.get("response"):
text_chunk = chunk["response"]
full_response += text_chunk
# yield json.dumps(chunk) + "\n\n"
logger.info(f"data: {json.dumps({'chunk': text_chunk})}\n\n")
yield f"data: {json.dumps({'chunk': text_chunk})}\n\n"
if chunk.get("done", False):
rag_tracer.end_generation(gen_span, full_response, "hybrid")
# logger.info(f"full_response {full_response}")
yield f"data: {json.dumps({'answer': full_response, 'done': True})}\n\n"
final_chunk = chunk # ← save last chunk
break
rag_tracer.end_request(trace, full_response, time.time() - start_time)
if final_chunk:
usage = store_chat_and_ollama_usage(
user_id,
query,
final_chunk=final_chunk,
prompt=final_prompt,
response=full_response,
)
print("Token Usage:", usage)
except Exception as e:
error_msg = {"error": str(e)}
yield f"data: {json.dumps(error_msg)}\n\n"
generate_stream
class OllamaClient:
"""Client for interacting with Ollama local LLM service."""
def __init__(self, settings: Settings):
"""Initialize Ollama client with settings."""
self.base_url = settings.OLLAMA_API_URL
self.model_name = settings.MODEL_NAME
self.timeout = httpx.Timeout(float(settings.OLLAMA_TIMEOUT))
self.prompt_builder = RAGPromptBuilder()
self.response_parser = ResponseParser()
async def generate(
self,
prompt: str = "",
**kwargs,
) -> str:
...
async def generate_rag_answer(
self,
query: str,
chunks: List[Dict[str, Any]],
use_structured_output: bool = False,
temperature: float = 0.5,
user_language: str = "English",
) -> Dict[str, Any]:
...
async def generate_stream(self, prompt: str = "", **kwargs):
"""
Generate text with streaming response.
Args:
model: Model name to use
prompt: Input prompt for generation
**kwargs: Additional generation parameters
Yields:
JSON chunks from streaming response
"""
try:
async with httpx.AsyncClient(timeout=self.timeout) as client:
data = {
"model": self.model_name,
"prompt": prompt,
"stream": True,
**kwargs,
}
logger.info(f"Starting streaming generation: model={self.model_name}")
async with client.stream(
"POST", f"{self.base_url}/api/generate", json=data
) as response:
if response.status_code != 200:
raise OllamaException(
f"Streaming generation failed: {response.status_code}"
)
async for line in response.aiter_lines():
if line.strip():
try:
yield json.loads(line)
except json.JSONDecodeError:
logger.warning(
f"Failed to parse streaming chunk: {line}"
)
continue
except httpx.ConnectError as e:
raise OllamaConnectionError(f"Cannot connect to Ollama service: {e}")
except httpx.TimeoutException as e:
raise OllamaTimeoutError(f"Ollama service timeout: {e}")
except OllamaException:
raise
except Exception as e:
raise OllamaException(f"Error in streaming generation: {e}")
from typing import Annotated
from config import Settings, get_settings
from fastapi import Depends, Request
from services.cache.client import CacheClient
from services.langchain.client import LangChainClient
from services.minio.client import MinioClient
from services.ollama.client import OllamaClient
from services.qdrant.client import QdrantClient
def get_ollama_client(request: Request) -> OllamaClient:
"""Get Ollama client from the request state."""
return request.app.state.ollama_client
def get_langchain_client(request: Request) -> LangChainClient:
"""Get langchain client from the request state."""
return request.app.state.langchain_client
def get_user_cache_client(request: Request) -> CacheClient | None:
"""Get cache client from the request state."""
return getattr(request.app.state, "cache_user_client", None)
def get_qdrant_client(request: Request) -> QdrantClient:
"""Get Qdrant client from the request state."""
return request.app.state.qdrant_client
def get_minio_client(request: Request) -> MinioClient:
"""Get Minio client from the request state."""
return request.app.state.minio_client
# Dependency annotations
QdrantDep = Annotated[QdrantClient, Depends(get_qdrant_client)]
MinioDep = Annotated[MinioClient, Depends(get_minio_client)]
SettingsDep = Annotated[Settings, Depends(get_settings)]
OllamaDep = Annotated[OllamaClient, Depends(get_ollama_client)]
LangchainDep = Annotated[LangChainClient, Depends(get_langchain_client)]
UserCacheDep = Annotated[CacheClient | None, Depends(get_user_cache_client)]
FROM python:3.10-slim
# 安裝系統依賴(ffmpeg、tesseract OCR、OpenGL)
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
git \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY services/noteservice/requirements.txt ./requirements.txt
COPY ./note /app
RUN pip install --no-cache-dir --upgrade pip
RUN pip install --no-cache-dir -r requirements.txt
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]


 iThome鐵人賽
iThome鐵人賽