昨天介紹完了 kv cache,觀念上很簡單,就是空間換取時間,但背後其實有很多優化的技巧等等。
底下以 nanoVLM 的 code 來做解析,程式當中沒有複雜的寫法很適合學習
prefill 階段是將 prompt 一次性轉換成 KV cache,生成第一個 token,後續開始 decode , Q 的維度 [B, 1, d]
Prefill → compute-bound (算力是瓶頸) → 適合高算力 GPU → 優化算子合併或簡化, 降低模型計算量
Decode → memory-bound (內存是瓶頸) → 適合記憶體較大的 GPU → 優化 kv cache 的訪問或量化
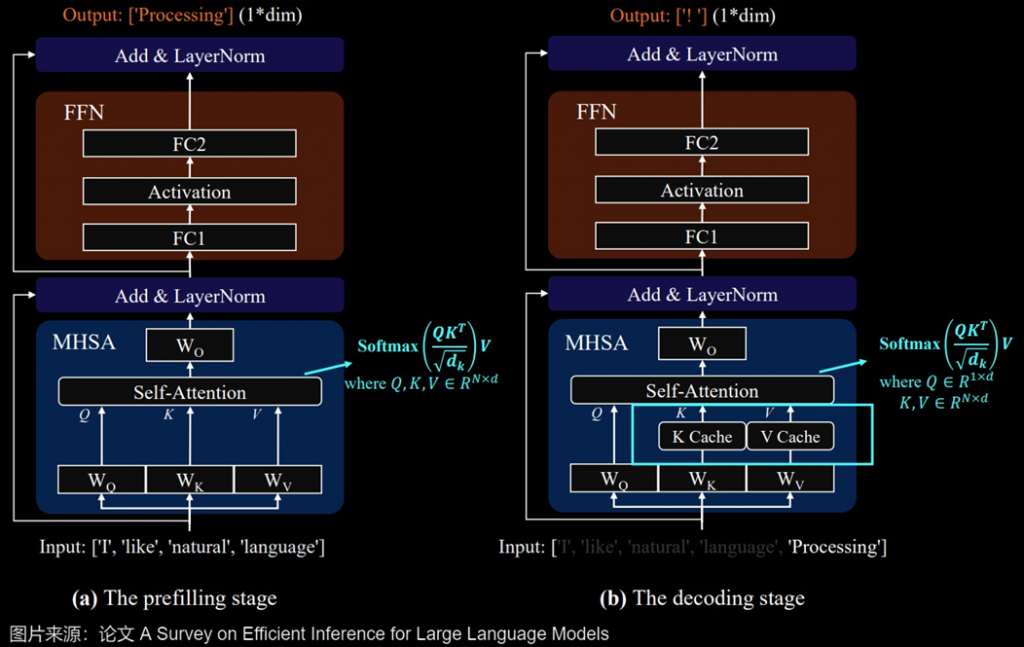
對應程式,以下是部分片段
讓我們先看一下主要在 attention 裡面的部分
Prefill 步驟: 直接儲存,因為 cache 裡面還沒有東西
Decode 步驟: 從 kv cache 拿出之前的 kv → 跟現有 kv 做 concat → 再儲存回 kv cache
def forward(self, x, cos, sin, attention_mask=None, block_kv_cache=None):
# 第一次沒有 kv_cache 稱作 prefill
is_prefill = block_kv_cache is None
B, T_curr, C = x.size() # T_curr is the sequence length of the current input x
q_curr = self.q_proj(x).view(B, T_curr, self.n_heads, self.head_dim).transpose(1, 2) # (B, n_heads, T_curr, head_dim)
k_curr = self.k_proj(x).view(B, T_curr, self.n_kv_heads, self.head_dim).transpose(1, 2) # (B, n_kv_heads, T_curr, head_dim)
v_curr = self.v_proj(x).view(B, T_curr, self.n_kv_heads, self.head_dim).transpose(1, 2) # (B, n_kv_heads, T_curr, head_dim)
# Apply rotary embeddings to the current q and k
q, k_rotated = apply_rotary_pos_embd(q_curr, k_curr, cos, sin)
# Check if we can use cached keys and values
if not is_prefill and block_kv_cache['key'] is not None:
# Concatenate with cached K, V
# k_rotated and v_curr are for the new token(s)
k = block_kv_cache['key']
v = block_kv_cache['value']
k = torch.cat([k, k_rotated], dim=2)
v = torch.cat([v, v_curr], dim=2)
block_kv_cache['key'] = k
block_kv_cache['value'] = v
else:
# No cache, this is the first pass (prefill)
k = k_rotated
v = v_curr
block_kv_cache = {'key': k, 'value': v}
# 中間省略計算
return attention_output, block_kv_cache
一個 block (模型的其中一層) 包含 attention 和 mlp,會發現 block_kv_cache 是再由外部傳入而已
對應程式
class LanguageModelBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.mlp = LanguageModelMLP(cfg)
self.attn = LanguageModelGroupedQueryAttention(cfg)
self.norm1 = RMSNorm(cfg) # Input Norm
self.norm2 = RMSNorm(cfg) # Post Attention Norm
def forward(self, x, cos, sin, attention_mask=None, block_kv_cache=None):
res = x
x = self.norm1(x)
# 單純的輸入和回傳 kv_cache
x, block_kv_cache = self.attn(x, cos, sin, attention_mask, block_kv_cache)
x = res + x
res = x
x = self.norm2(x)
x = self.mlp(x)
x = res + x
return x, block_kv_cache
包含多個 LanguageModelBlock,就是堆疊多層的 block,變成最後的 LLM 模型。
對應程式
class LanguageModel(nn.Module):
def __init__(self, cfg):
super().__init__()
# 其他省略
self.blocks = nn.ModuleList([
LanguageModelBlock(cfg) for _ in range(cfg.lm_n_blocks)
])
def forward(self, x, attention_mask=None, kv_cache=None, start_pos=0):
if self.lm_use_tokens:
x = self.token_embedding(x)
# T_curr is the length of the current input sequence
B, T_curr, _ = x.size()
# Create position_ids for the current sequence based on start_pos
current_position_ids = torch.arange(start_pos, start_pos + T_curr, device=x.device).unsqueeze(0).expand(B, -1)
cos, sin = self.rotary_embd(current_position_ids) # Get rotary position embeddings for current tokens
# Initialize new KV cache if none provided
# 因為每層都是單獨的計算
# 所以每層 decoder 的 attn 都會有一個 kv cache
# 所以依照層數來創建一個 kv_cache_list 來儲存
if kv_cache is None:
kv_cache = [None] * len(self.blocks)
# 依照 i (代表層數) 來代入對應的 kv cache, 以及將回傳的 kv cahce 再儲存回去
for i, block in enumerate(self.blocks):
x, kv_cache[i] = block(x, cos, sin, attention_mask, kv_cache[i])
x = self.norm(x)
# Compute logits if we are using tokens, otherwise stay in the embedding space
if self.lm_use_tokens:
x = self.head(x)
return x, kv_cache
第一個 self.forward 是在 Prefill 階段,也就是計算 prompt,然後儲存在 kv_cache_list。
後續在 for 迴圈的 self.forward 就是在 Decode 階段,一次只傳入一個 token (next_output) + KV cache (kv_cache_list) (像下圖一樣)
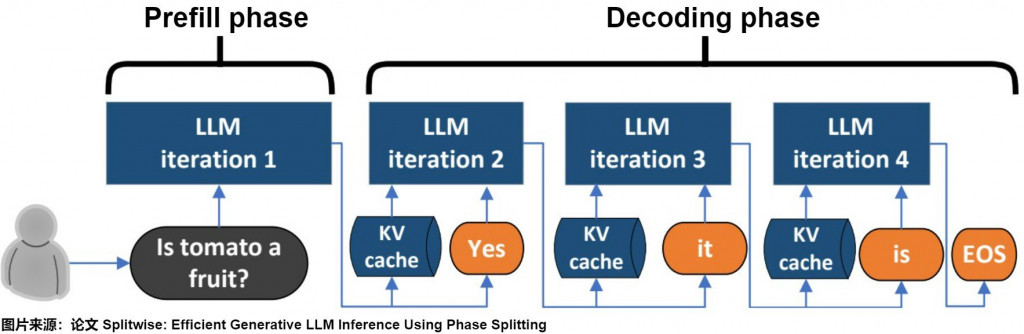
對應程式
@torch.inference_mode()
def generate(self, inputs, max_new_tokens=20):
# Add batch dimension if needed
if inputs.dim() == 1:
inputs = inputs.unsqueeze(0)
generated_outputs = inputs.clone()
# Prefill 階段, 計算 prompt
prompt_output, kv_cache_list = self.forward(
generated_outputs,
attention_mask=None,
kv_cache=None,
start_pos=0
)
last_output = prompt_output[:, -1, :]
# Decode Phase with KV cache
for i in range(max_new_tokens):
if self.lm_use_tokens:
# Now the model outputs logits
next_output = torch.argmax(last_output, dim=-1, keepdim=True)
else:
# Now the model outputs embeddings
next_output = last_output.unsqueeze(1)
generated_outputs = torch.cat((generated_outputs, next_output), dim=1)
# The token being processed is `next_token`. Its position is `generated_outputs.size(1) - 1`.
current_token_start_pos = generated_outputs.size(1) - 1
if i == max_new_tokens - 1:
break
# 一次輸入一個 token, 然後傳入 kv_cahe_list
decode_step_output, kv_cache_list = self.forward(
next_output,
attention_mask=None,
kv_cache=kv_cache_list,
start_pos=current_token_start_pos
)
last_output = decode_step_output[:, -1, :]
return generated_outputs
今天算是比較輕鬆,只是參考人家寫的程式而已,可以等之後自己實作的時候再參考這整個流程就好,今天就到這裡囉~


 iThome鐵人賽
iThome鐵人賽