前兩天主要是講 kv cache 的計算量及需要暫存多少記憶體,給出了一個公式以及優化的方向。
參考文章: https://www.cnblogs.com/rossiXYZ/p/18823734
一樣在 SMALL LANGUAGE MODELS:
SURVEY, MEASUREMENTS, AND INSIGHTS 的論文當中,會發現 GQA 漸漸取代原本的 MHA,以現在 GPT-oss, Grok-2, Qwen 都採用 GQA,目的是為了減少我們前面提到過的 kv cache。
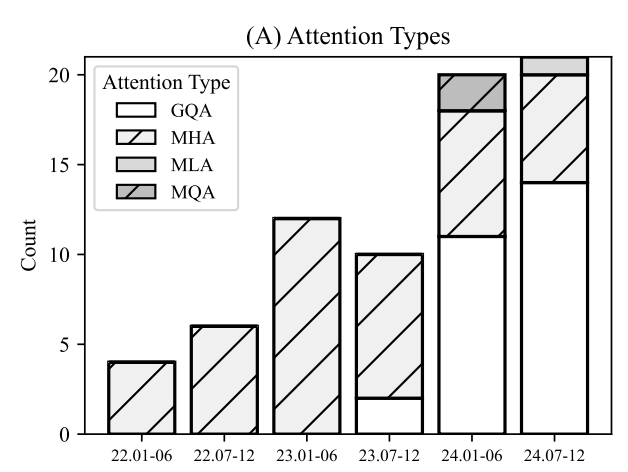
當初計算 kv cache 的公式: 2×B×L×H×D×PxN (其中 H 是 n_head),我們透過類似下圖的方法來減少 head 的數量,藉此來降低 kv cache 所需要的記憶體。
原先的 MHA 是一個頭會對應到一個 K 和 V,那 GQA/MQA 變成讓不同的頭共享一個 K 和 V,這樣子就可以大幅減少記憶體佔用並且更有效率。
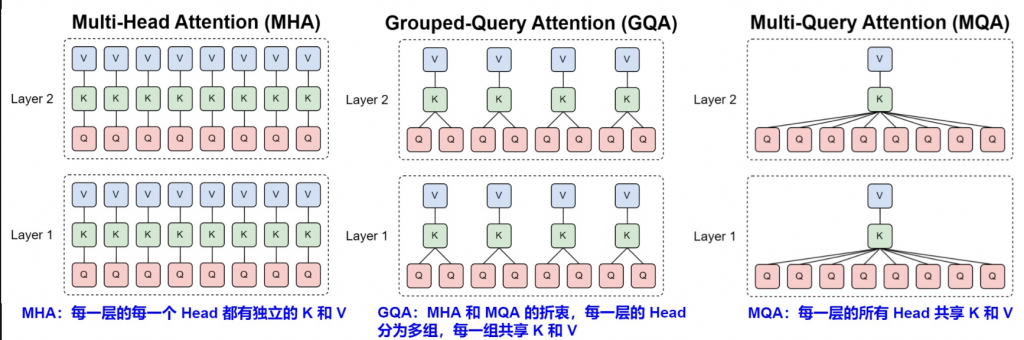
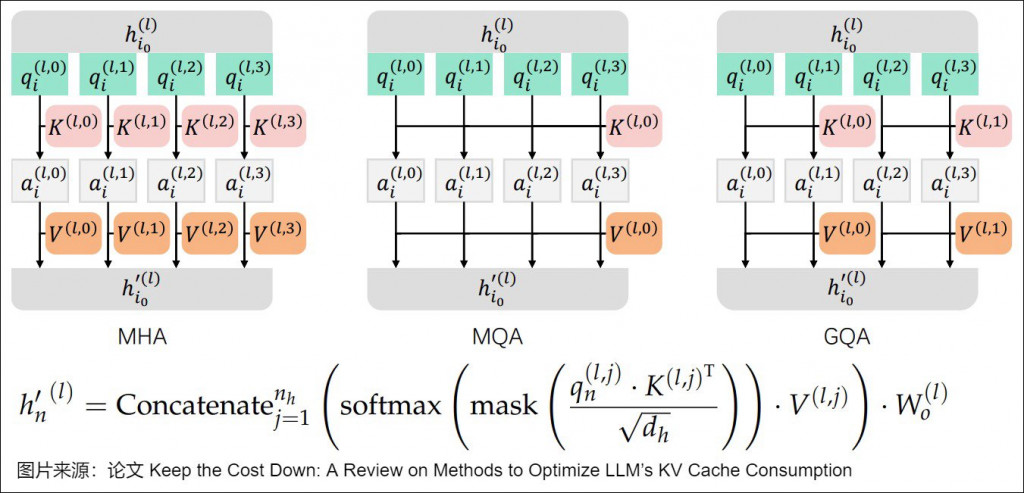
核心觀念: 讓多個 Q 共享少量的 K 和 V,減少運算開銷,透過分組機制更有效率運算
我們比較一下 MHA(下圖一) 跟 GQA(下圖二),其中主要就是 kv 的部分,其中 g = (注意力頭數)/(KV 頭數)
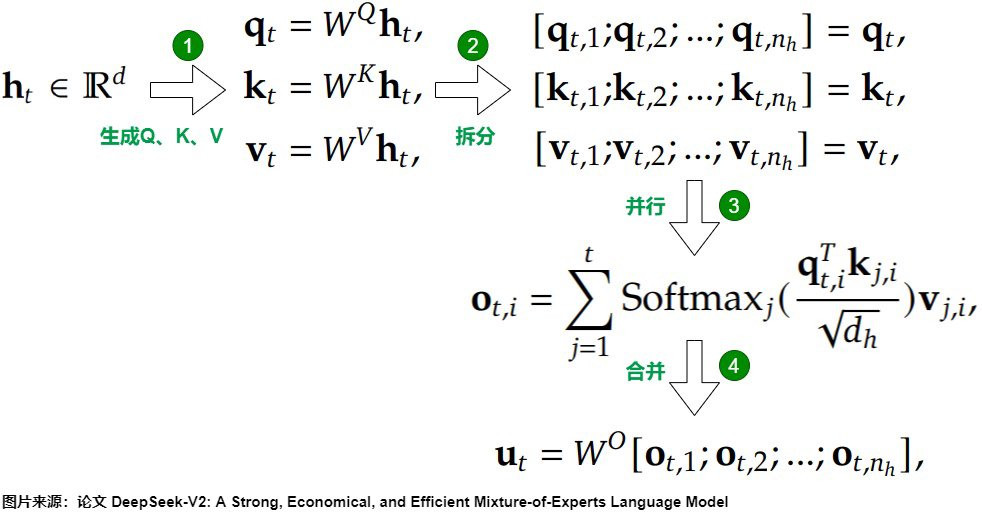

底下來看一下最近模型的設定,g 大概是 8 或者 16,然後 num_key_value_heads 最小為 4,如果像 MQA 一樣為 1 的話,那確實可以提升 decoder 中的推理能力,也大幅降低 kv cache,但這樣會帶來生成品質下降,訓練方面也不太穩定,這也就是目前主流是採用 GQA 的原因。
| gpt_oss_120b | qwen3-4b | qwen3-30B-A3B | qwen3-235B-A22B | grok-2 | llama3.3-70B | |
|---|---|---|---|---|---|---|
| num_attention_heads | 64 | 32 | 32 | 64 | 64 | 64 |
| num_key_value_heads | 8 | 8 | 4 | 4 | 8 | 8 |
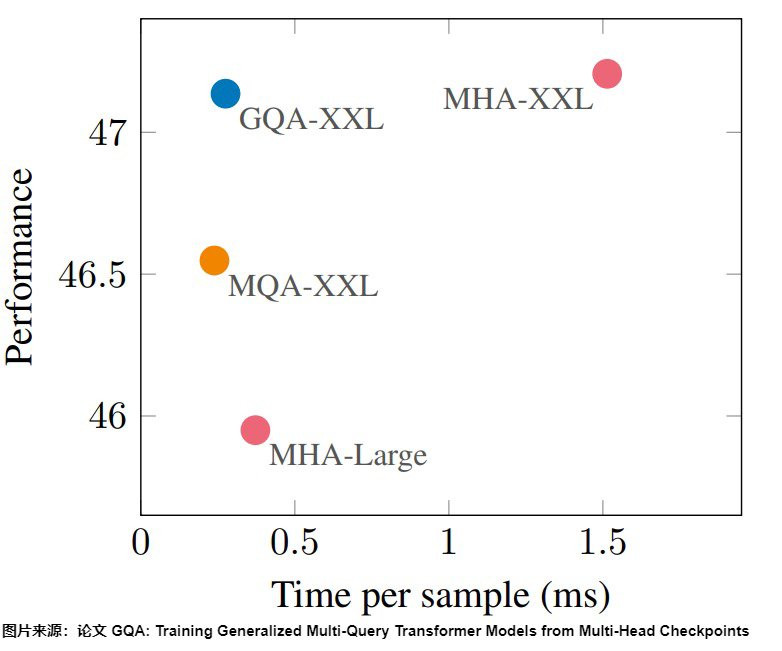
最後比較三個表徵能力,可以看到 GQA 和 MHA 分數差不了多少,但速度快蠻多的。
另外有興趣的可以參考這篇,更詳細計算 FLOPs。
今天就先到這裡囉~ 明天實作會更清楚。


 iThome鐵人賽
iThome鐵人賽