今天進入比較專業的語彙:從 核心數量/組織、SM(Streaming Multiprocessor)、SIMT、記憶體階層 到 固定功能單元,建立你對「為何渲染天然屬於 GPU」的工程直覺。
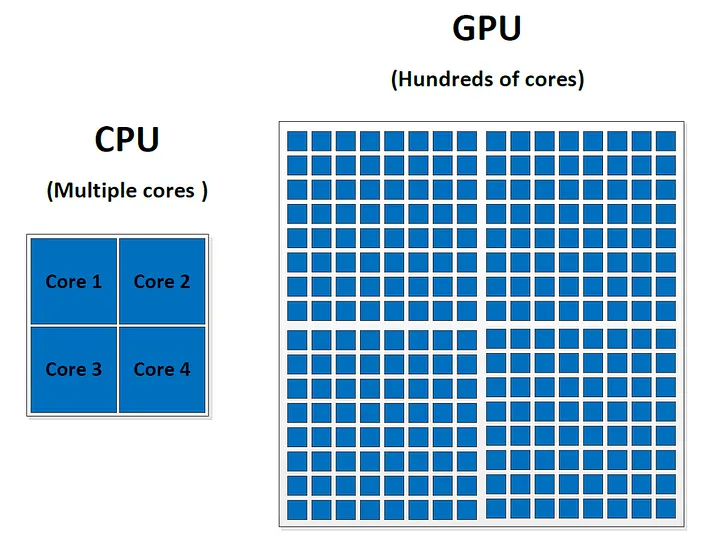
少量高效能核心(一般 4–32 threads/consumer,伺服器更多),強調:
適合控制流程複雜、資料依賴多的任務
大量簡化核心,組成多個 SM(Streaming Multiprocessor)(NVIDIA 名稱;AMD 稱 CU,Intel 稱 EU 群)
每個 SM 內含:
適合**資料平行(Data-Parallel)與吞吐量(Throughput)**導向的工作
示意圖:組織差異(簡化)
CPU: [超強核心]──大快取──[超強核心]──大快取──[超強核心]
GPU: [SM] [SM] [SM] [SM] [SM] [SM] ...(每個 SM 內含數十~上百 ALU)
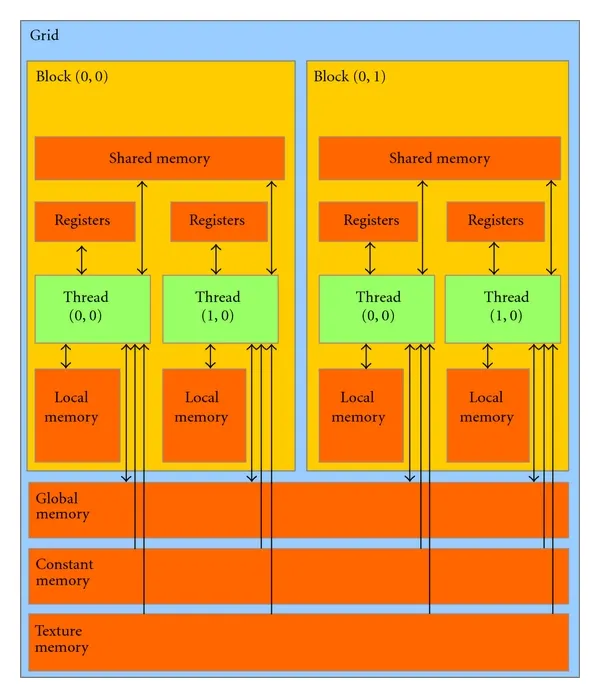
GPU 不是純粹的 SIMD;實務上是 SIMT:以 Warp(NVIDIA,通常 32 threads)或 Wavefront(AMD,通常 64 threads)為單位,同步執行同一條指令流程。
渲染的像素/片段著色恰好符合這種型態:
示意圖:SM 內的排程(概念)
[ SM ]
├─ Warp Scheduler #1 → Warp A → ALU → 記憶體等待 → 切換 → Warp B
├─ Warp Scheduler #2 → Warp C → ALU → ...
└─ Shared Mem / Registers / Texture Units
Warp 分歧(Divergence):若同一 warp 內 thread 的控制流程(if-else)不同,會序列化執行,效能下降——這也是 shader 設計要盡量避免分支發散的原因。
示意圖:GPU 記憶體層級(簡化)
DRAM(GDDR/HBM)
│
L2(全域)
┌───┴────┐
[SM] [SM] ... → 每個 SM:Registers / Shared Mem / Texture Units
渲染的特性:貼圖取樣具空間局部性(鄰近像素多取相近座標),幫助快取命中;再加上大量並行,能有效榨乾頻寬。
現代 GPU 除了可程式階段(Vertex/Fragment/Compute),還有**固定功能(Fixed-Function)**模組:
以 4K(3840×2160 ≈ 829 萬像素)、60 FPS 為例:
829 萬 × 60 ≈ 4.97 億像素/秒
每像素若進行 數十~上百次 ALU + 幾次貼圖取樣 → 數百億級指令/秒。
CPU 就算單核 IPC 再高,也很難在延遲與分支條件下達到同級吞吐;GPU 以 上萬條執行緒並行 迎戰,才是正解。
場景/遊戲邏輯、資源管理、命令錄製(Vulkan:Command Buffer)、綁定資源(Descriptor/BindGroup)、管線切換
效能常見瓶頸:
示意圖:簡化資料路徑
CPU(建資料/錄指令/綁定) → 提交 → GPU(多 SM 併行執行) → ROP/輸出
A. CPU vs GPU 組織
CPU:少數強核心 + 深快取 + 複雜控制 → 低延遲任務
GPU:多個 SM + SIMT + 高頻寬顯存 → 高吞吐任務(渲染/計算)
B. SM 內部(抽象)
[Warp Sched]─┬─ Warp0 → ALU/Load/Texture → 等待 → 切換 Warp1
└─ Warp2 → ...
Registers / SharedMem / Texture Units / L/S Units
C. 渲染資料流
頂點資料→頂點著色→光柵化→片段著色→測試/混色→影格
(GPU 可程式 + 固定功能協作)
渲染是大量「同程式、不同資料」的像素級運算,最適合交給具 SM/SIMT 架構、能以高 occupancy 隱藏延遲、並由固定功能單元輔助的 GPU;CPU 的任務是把資料與命令「餵好、餵滿」,讓 GPU 盡情吞吐。
往管線更細一層:從頂點到像素的旅程——頂點著色、光柵化、片段著色、深度/混色規則,一次看懂整條渲染管線。

