昨天我們確立了數據作為 AI 基石的核心心法。但光有心法還不夠,真正要將數據煉成黃金,需要不同門派的高手通力合作。在數據江湖中,最常被提起的有三大角色:資料工程師 (Data Engineer)、資料分析師 (Data Analyst) 與資料科學家 (Data Scientist)。
許多人對這三個角色的分工感到困惑,甚至認為他們做的事情差不多。今天,我們就來徹底釐清這三者之間的三角關係,以及他們如何在一個 AI 專案中協同作戰。
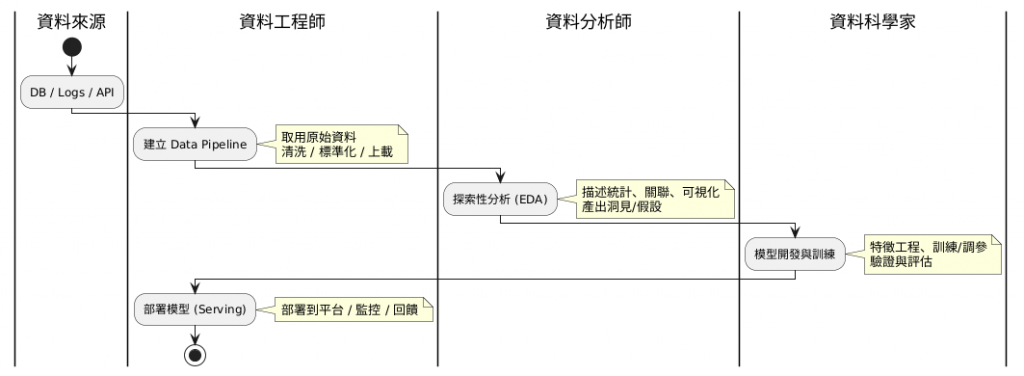
想像我們要打造一個電商的「智慧推薦系統」AI 專案,來看看這三位英雄如何發揮所長:
核心任務: 打造穩定、高效的數據管線 (Data Pipeline)。他們負責從各種來源(如 App 點擊、交易資料庫、使用者日誌)收集、儲存並處理數據,確保資料的品質與可用性。
AI 專案中的角色: 他們會建立一條自動化的管線,將使用者的瀏覽、點擊、購買等行為數據,源源不絕地送到資料科學家能取用的地方。他們就像是確保水源乾淨且暢通的「水利工程師」。
這三者並非獨立運作,而是緊密的協作關係。一個典型的 AI 專案流程就像一場接力賽:
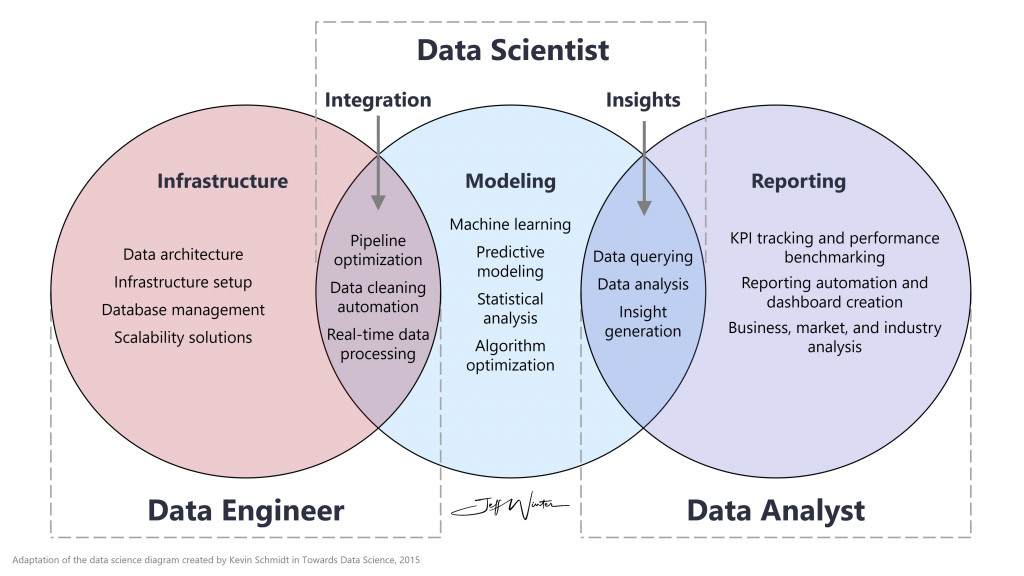
圖片來源參考:https://www.jeffwinterinsights.com/insights/data-engineer-vs-scientist-vs-analyst
理解這三種角色的差異,不僅有助於企業組建高效的數據團隊,也能幫助有志投身數據領域的你,找到最適合自己的定位。你是享受建構穩定系統、打通數據血脈的工程師?還是熱衷於從數字中找出故事、影響決策的分析師?或是著迷於演算法與模型、創造預測未來的科學家?
無論選擇哪個門派,記住,江湖上沒有最強的個人,只有最強的團隊。


 iThome鐵人賽
iThome鐵人賽