在前七天的修煉中,我們了解了數據儲存的三種基本容器:資料庫、資料倉儲與資料湖。其中,「資料湖」這個能容納百川、儲存各式原始資料的概念,之所以能實現,很大程度上要歸功於一隻改變了世界的黃色小象 — Hadoop。
時間回到 2000 年初期,Google 為了處理數十億網頁的索引,發表了兩篇劃時代的論文:Google File System (GFS) 與 MapReduce。這啟發了 Doug Cutting 等人,最終催生了開源的 Hadoop。它的核心使命只有一個:用一群普通的廉價電腦,組成一個超級叢集,來解決單一伺服器無法處理的龐大數據儲存與運算問題。
Hadoop 的武功心法主要建立在兩大支柱上:
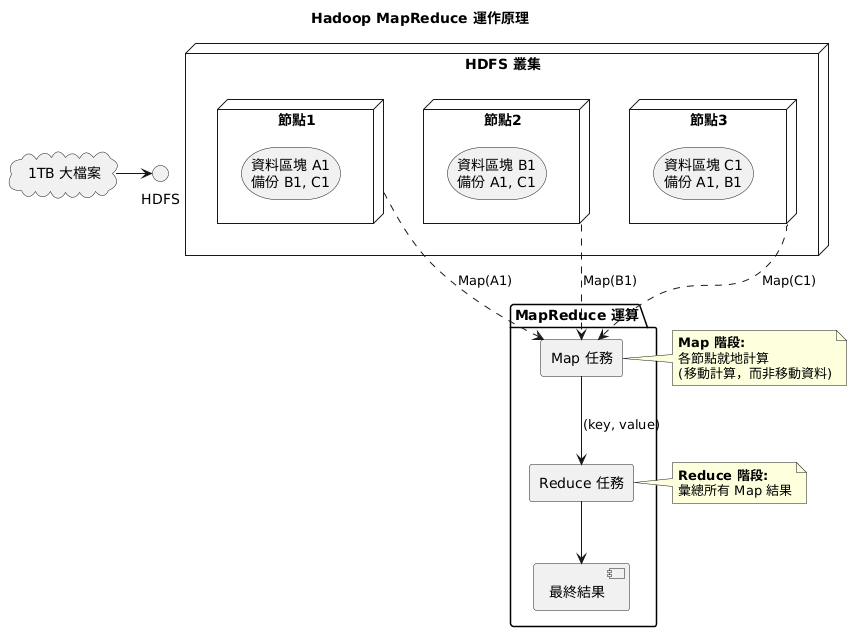
儘管 MapReduce 的設計較為僵硬、延遲較高,後來被 Spark 等更高效的記憶體內運算框架所取代,但 Hadoop 的歷史功績是不可抹滅的。
它用開源的力量,將過去只有 Google 等巨頭才能使用的分散式處理技術普及化,真正開啟了「大數據時代」。它所奠定的「儲存與運算分離」、「在地運算」等核心思想,至今仍深深影響著現代資料平台的架構設計。可以說,沒有這隻黃色小象,就沒有我們今天所熟知的資料湖,許多複雜的 AI 應用也將無從談起。


 iThome鐵人賽
iThome鐵人賽