昨天我們認識了開啟大數據時代的 Hadoop,它擅長用批次處理 (Batch Processing) 的方式,處理海量的非結構化資料,是資料湖的絕佳基石。然而,當場景轉移到資料倉儲,分析師需要對數十億筆結構化資料進行複雜的 SQL 交互式查詢時,Hadoop 的 MapReduce 就顯得力不從心。
這時,另一派武功 — MPP (Massive Parallel Processing, 大規模平行處理) 架構,便在資料倉儲領域大放異彩,成為了速度與激情的代名詞。
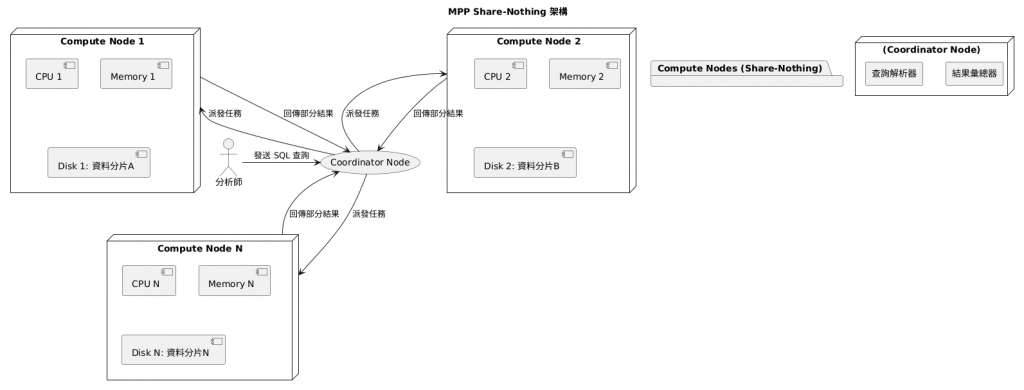
MPP 架構的核心思想是 "Share-Nothing"。想像一個大型圖書館,不是只有一位館員,而是有數百位館員,每位館員都配有自己獨立的書庫、電腦和辦公桌,互不干擾。
在 MPP 資料倉儲中,每一台伺服器節點 (Node) 都有自己獨立的 CPU、記憶體和硬碟。當一張巨大的資料表(例如十億筆訂單)載入時,系統會根據某個欄位(例如 customer_id)進行雜湊 (Hash) 計算,將資料打散,均勻地分佈到所有節點上。
當一個查詢進來時,例如 SELECT COUNT(*) FROM orders WHERE amount > 1000;:
| 特性 | MPP (e.g., Redshift, BigQuery) | Hadoop MapReduce |
|---|---|---|
| 設計目標 | 低延遲、高速的 SQL 交互式查詢 | 高吞吐量、離線批次處理 |
| 資料類型 | 結構化資料 | 結構化、非結構化 |
| 運算模式 | 記憶體內運算為主,速度快 | 磁碟 I/O 為主,延遲高 |
| 耦合度 | 儲存與運算緊密耦合 | 儲存 (HDFS) 與運算 (MapReduce) 解耦 |
| 適用場景 | 企業級資料倉儲、BI 報表 | 資料湖、ETL 預處理、AI 模型訓練 |
| 優點 | (1) SQL 介面友好,容易上手 (2) 速度快,適合交互式查詢 (3) 高度優化的分散式架構 | (1) 能處理結構化/非結構化資料 (2) 彈性大,適合大規模批次運算 (3) 開源生態系豐富 |
| 缺點 | (1) 擴展成本高,通常為商用產品 (2) 主要偏向結構化資料 (3) 不適合超大規模的非結構化處理 | (1) 延遲高,不適合即時互動 (2) 開發複雜度高 (需要寫 Map/Reduce 程式) (3) I/O 密集,效能受限 |
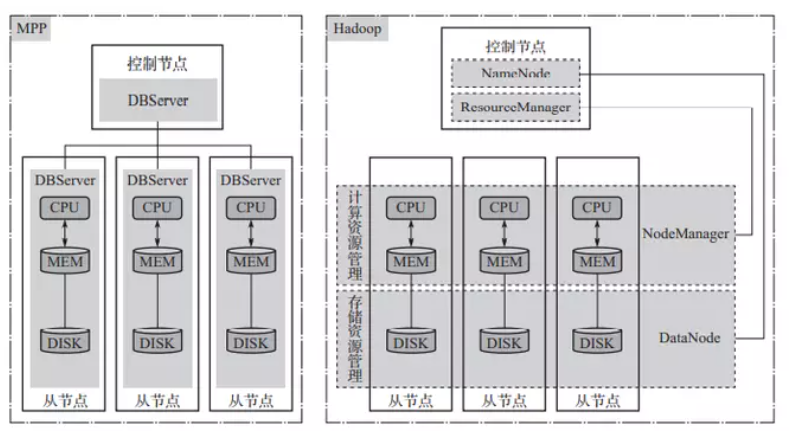
MPP 與 Hadoop 比較表
圖片來源參考:https://www.cnblogs.com/huanghanyu/p/18191612
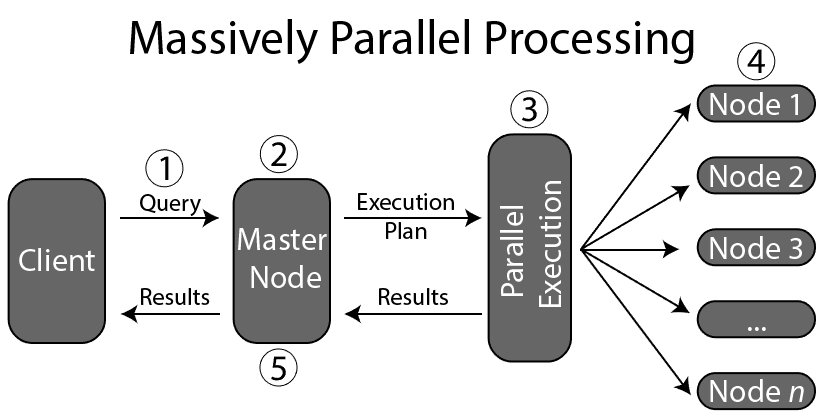
圖片來源參考:https://www.oreilly.com/library/view/mastering-tableau-2019-1/9781789533880/d335b673-9ec5-491d-b5cc-f879dce45ecc.xhtml
MPP 架構之所以能在雲端時代大行其道(代表產品如 Amazon Redshift, Google BigQuery, Snowflake),正是因為它完美契合了雲端資料倉儲的需求:極致的查詢效能。
AI 應用情境:
一個 AI 團隊在開發新模型時,常常需要對數十億筆的特徵資料 (Features) 進行探索性分析 (EDA),例如計算特徵的分佈、相關性等。如果使用 Hadoop,一個查詢可能要等幾十分鐘甚至數小時。而使用 MPP 資料倉儲,同樣的查詢可能在幾秒或幾分鐘內就能完成,大大加速了 AI 模型的迭代速度。
MPP 和 Hadoop 並非競爭關係,而是互補的。Hadoop 像是一艘巨大的貨輪,能以低成本運載任何形態的貨物(數據),但速度較慢;MPP 則像一艘快艇,專門運送標準貨櫃(結構化數據),速度極快。
理解這兩種架構的設計哲學,能幫助我們在建構現代資料平台時,為不同的任務選擇最合適的工具,讓貨輪與快艇各司其職。
| 功能清單 | MPP | Hadoop | 補充說明 |
|---|---|---|---|
| 數據最大吞吐量 | 弱 | 強 | MPP 相比 Hadoop,受限於單個伺服器的處理能力,因為單機的效能有上限 |
| 單機計算性能 | 強 | 弱 | MPP 多使用 C++,計算效能較高;Hadoop 基於 Java,效能較低 |
| 數據寫入效率 | 弱 | 強 | Hadoop 中每個節點工作相同且簡單,只需均勻分布即可;但 MPP 要確保資料必須傳送到指定的節點 |
| 數據讀取效率 | 強 | 弱 | MPP 在存儲時依照規則分布,讀取時依規則存取效率高;Hadoop 隨機分布,只保證均勻 |
| 安裝部署 | 簡單 | 複雜 | MPP 通常是一體化安裝;Hadoop 至少需安裝 Hive、HDFS、Zookeeper 等組件 |
| SQL 開發能力 | 強 | 弱 | MPP 理論上可支援更多函數處理;Hadoop 部分特殊計算需依賴程式碼實作 |


 iThome鐵人賽
iThome鐵人賽