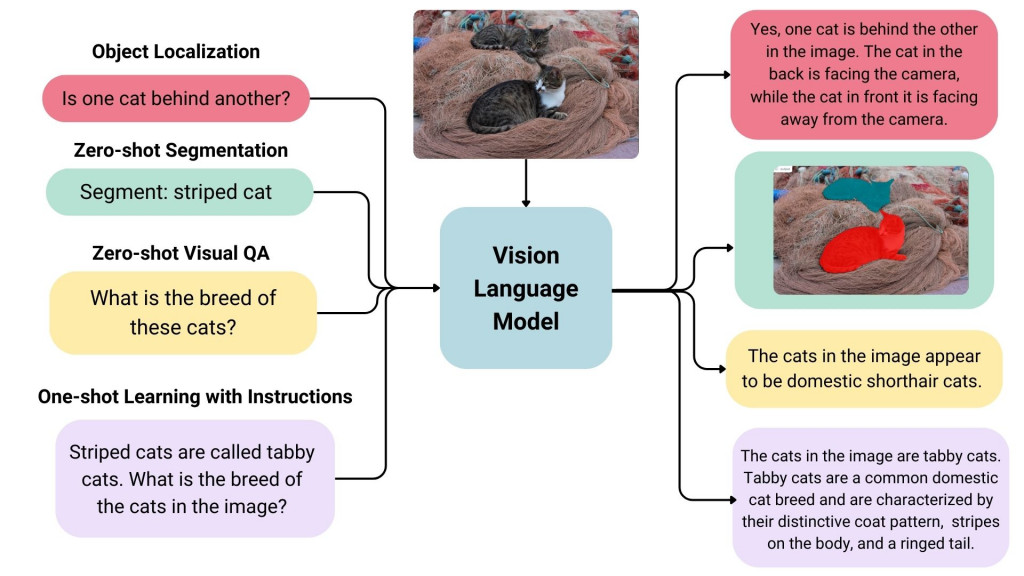
圖片來源:huggingface
在Day1 提到了VLM可以完成哪些任務,參考上面這張圖片可以理解得更清楚。
這些任務未來可以具體被應用在哪些領域:
此時我們是否會有疑問,電腦視覺發展已久,且針對影像處理任務,現今有許多應用利用深度學習的模型或演算法已有不錯的準確度,在未來有需要轉向使用VLM嗎,例如Day1提到的影像物件辨識任務,這幾年YOLO版本不斷的演進,目前在物件辨識的效能及準確度上都有不錯的發展,若這些應用並不需要語言理解,是否VLM並無法發揮更好的效果,也不需要轉向VLM應用? 這部分我需要再思考,可能等到我對VLM理解功力較深時候,最後幾天再來討論我的看法。
不過,不容置疑的是,當領域應用需要「影像 + 語言」跨模態整合,或需要人類可解釋輸出時,則使用VLM可更加智慧且能開發更廣泛的功能。
------------------------- 這是分隔線,以下純屬閒聊,可能與主題無關 ----------------------
這兩天匆忙地開始發文,只能先以過去僅有的VLM概念撐場面,有點乾....
預告 Day3: VLM的架構; Day4:如何訓練VLM,為什麼VLM可以看圖說話; Day5:目前有哪些VLM模型,開始動手做。


 iThome鐵人賽
iThome鐵人賽