VLM 的核心在於其具備將圖像轉換為 LLM 可理解的格式的能力,大部份的VLM運作包括三個主要組件:
圖像令牌和文本令牌同時被送入大型語言模型,模型使用其注意力機制將它們一起處理,故無論其來源是文本還是圖像,最終會生成一個文本回應,可以是字幕或圖像解釋,或是需要同時回覆圖像和文本內容的問題答案。
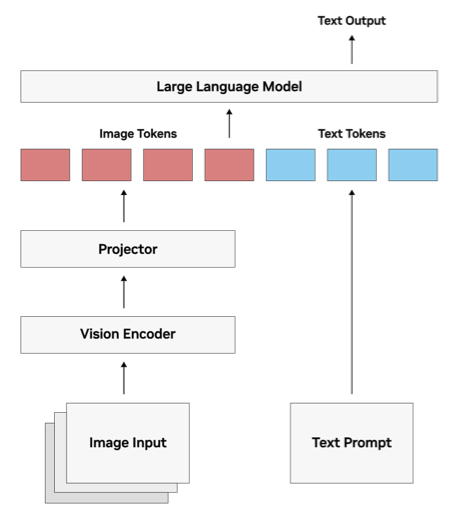
圖片來源:NVIDIA
VLM的訓練策略涉及對齊和融合來自視覺和語言編碼器的信息,以便可以學習將圖像與文本相關聯。有幾種訓練方法:
這四種訓練方法有時會混用。
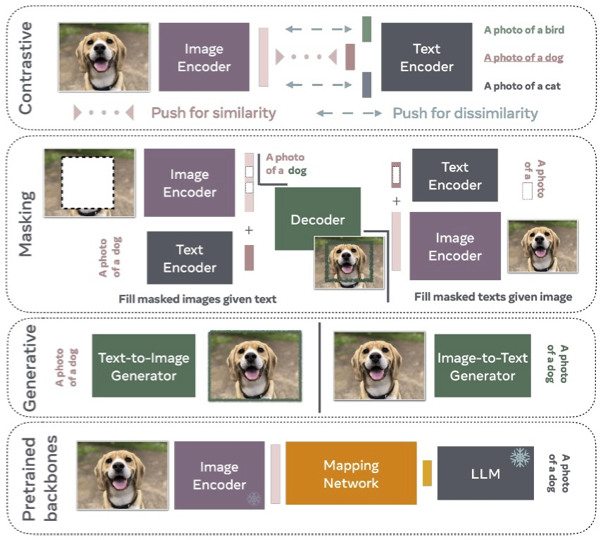
圖片來源:An Introduction to Vision-Language Modeling


 iThome鐵人賽
iThome鐵人賽