今天要來談談Entropy,中文為「熵」或「資訊熵」,從字面上看起來像是一個化學元素😁,幾乎完全無法推斷他到底是什麼東西。
但其實Entropy的概念很簡單,簡單一句話來說就是指訊息所帶有的資訊量。
以下就來介紹一下Entropy囉~
舉例來說,我記得小時候補習班下課時,都是媽媽來接我回家,有一天下課出了大門後,突然發現是爸爸來接我,我那個時候思緒萬馬奔騰,想說怎麼會是爸爸來接我...?(不用擔心,沒什麼特別的故事,單純只是換人來接而已😂)
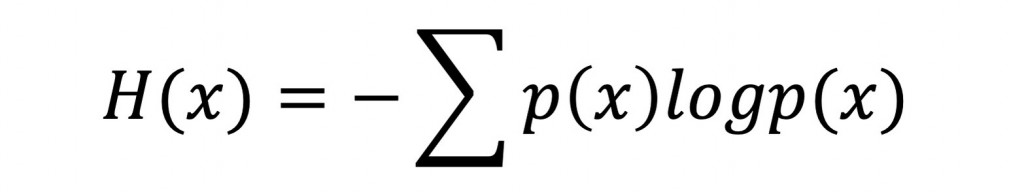
這邊簡單介紹一下Cross-entropy(交叉熵)~


 iThome鐵人賽
iThome鐵人賽