現在很紅的ChatGPT、Gemini、DeepSeek,他們都是「大型語言模型(Large Language Model)」,那大型語言模型到底是什麼?
要回答這個問題,應該回歸到「語言模型(Language Model)」本身,問問語言模型到底是什麼?
以下為一個小小的例子:
我今天晚餐吃了...
各位認為這句話後面應該接什麼呢🧐?
正常情況下,「吃了」後面應該會接「食物」,像是白飯、漢堡或是義大利麵,我們不會接像是櫃子、積木或是電池這些名詞,更不會去再接一個動詞。
換句話說,以這個句子而言,白飯、漢堡或是義大利麵這些詞出現在後面的機率,會遠大於櫃子、積木或是電池這些詞
語言模型簡單來說,就是預測字串中的下一個字。
今天就要來談談最簡單的語言模型,N-gram。
N-gram是什麼?
- N-gram為一串有n個字的字串序列
- Bigram就是有兩個字的字串序列,像是The school、school is這種就是由兩個單字所組成
- Trigram也就是有三個字的字串序列,像是The school is、school is next就是由三個單字所組成
- 但是N-gram也可以是指一個機率模型(Probabilistic Model),這個模型可以根據 n-1 個字來去預判下個字的機率
- 舉這個句子為例子:The school is next to the...,假設我們想根據我們所擁有的資訊,去看下一個字為 park 的機率,公式大概會長這樣:

- 但是其實我們不會這樣來去預測,因為語言具有無限的可能性,我們可以一直創造沒有人聽過的句子或是新詞,因此無法準確得到The school is next to the...的次數
從條件機率到N-gram
- The school is next to the park 這句話的機率為 P(The, school, is, next, to, the, park),用機率的 chain rule來看,公式為下
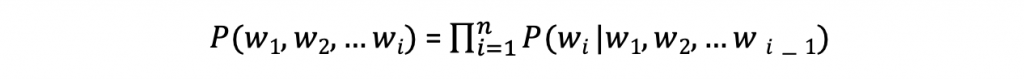
(註:chain rule有機會再細節一點講)
- 也就是每個詞的機率,取決於前面所有字
- 不過前面的字通常都會很長,機率算出來都會很小,因此N-gram就做了一個很相近的假設,也就是(以bigram為例):
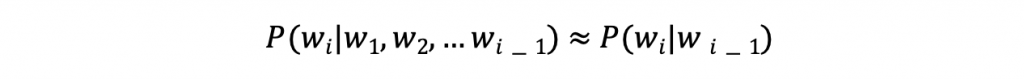
→ 我們只要根據前一個字來去預測下一個就好,這樣就可以用有限的語料來去做有效的預測
今天就先到這邊~明天繼續接續講下去~~


 iThome鐵人賽
iThome鐵人賽