Cassandra 是用來處理大量寫入的高可用分散式 Key-Value NoSQL DB,雖然是 NoSQL 但其實有 Schema,只不過 Schema 需要定義一個 Key 作為 Sharding Key,因此查詢時一定要用 Key 不然會跨 Sharding (DB) 查詢效能很差,因此稱為 Key-Value DB。
Cassandra 使用 Log-Structured Merge Tree(LSM Tree)結構儲存資料,該結構由 Memtable 和 SSTable 組成:
UPDATE or INSERT,不負責查詢快取.db :依照 key 排序的資料,類似有序陣列。.idx:稀疏索引資料,也是有序陣列,例如每隔 N 筆 row 紀錄一個 item 到索引裡面,主要是直接用 .db 進行 binary search 時會跳來跳去有隨機 I/O,.idx 資料量較小可以載入記憶體進行 binary search 後在到 .db 裡進行順序 scan。.filter:bloom filter 結構用來快速判斷某個 key 是否在 SSTable 中。寫入流程是:
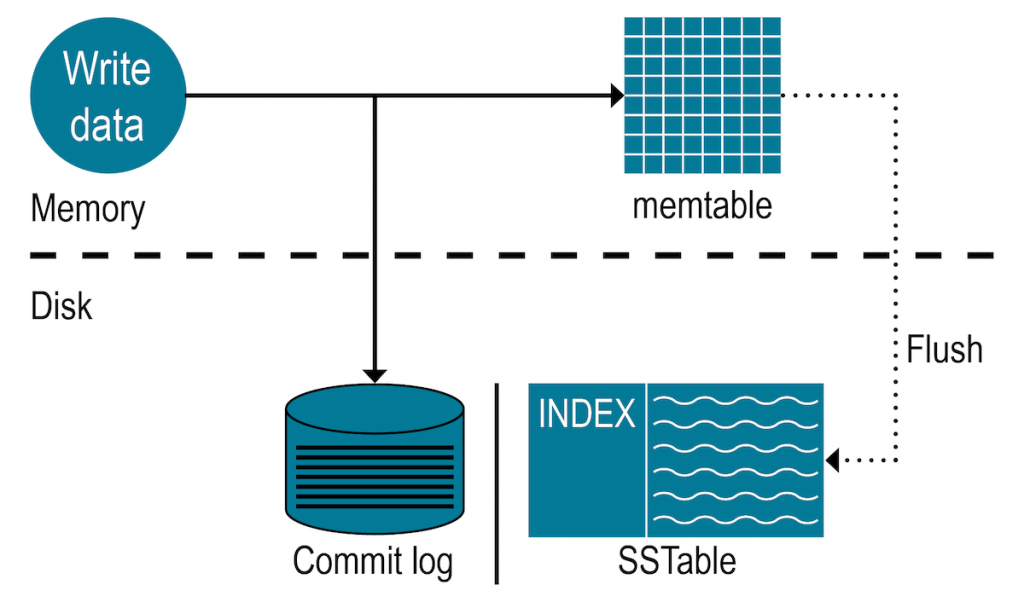
(圖來源:https://docs.datastax.com/en/planning/oss/schema-tuning.html)
SSTable 寫入後不能在修改,因此 UPDATE 資料是寫入一份新的 SSTable,並定期有 background thread 會把多個 SSTable Merge 成一個,相同 key 的資料會保留最新的一筆。
如果單純看寫入到記憶體和 WAL 的效能是差不多的,但 PG flush 時需要一次寫入多個 Dirty Page,而不同 Page 在不同硬碟位置,會有隨機 I/O,而 Cassandra 每次 flush 都是寫入一個完整的 SSTable,因此每次都是順序 I/O 一次寫入多筆資料。
此外高頻寫入情況下,PG 的 VACCUM 幾乎每次都要 scan 所有 heap page 幾乎是全表掃描,但 Cassandra會依照 compaction 策略只挑特定數量的 SSTable Merge,不需要每此都全表掃描。
因此在大量寫入情境下,Cassandra I/O 利用率更好,且 Merge 相較 VACCUM 執行更有彈性。
此外 Cassandra 的 Cluster 是 Multi-Master + Consistent Hashing 的Data Sharding 架構,同一個 Sharding 內的 DB 同時是 Master 也是彼此的 Slave,因此能乘載更大量的寫入請求。
Cassandra 採用 push 同步模式,負責處理寫入請求的 DB 為 Coordinator,處理完後會即時同步給其他 DB (Slave),如果 Slave 網路不通,會把該同步資料暫存到 system.hints 檔中,稱為 Hinted Handoff 功能,直到 Slave 恢復就會重送。
避免資料版本出錯,會使用 Last Write Wins 規則,每個寫入會有 microsecond 精度的 timestamp,如果 DB A 收到 DB B 的同步資料的 timestamp 比 DB A 自身資料還得早,就 skip 這筆同步。
如果 Slave 掛掉太久,system.hits 檔過期了,可以手動觸發 Anti-Entropy Repair,Slave 會向其他負責相同 sharding 的 DB 要求比對資料,但比對過程不可能把所有資料傳來傳去,因此會用 Merkle Tree:
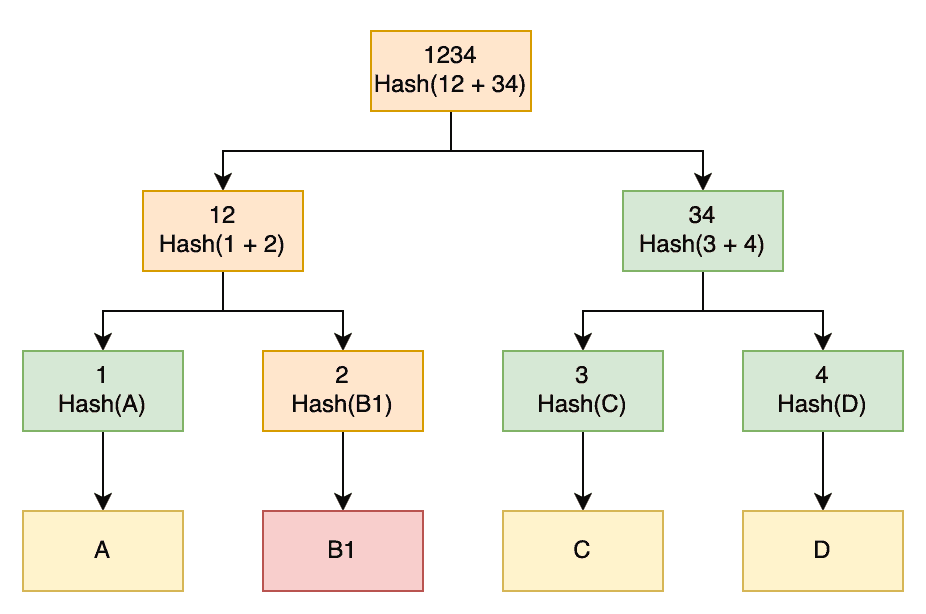
(圖來源:https://www.baeldung.com/cs/merkle-trees)
Cassandra 將所有資料的 hash 組成 Merkle Tree,每往上一層代表某段範圍的資料 hash,因此可先比對 root hash 若不一致,在找不一樣的 hash 往下比對,直到找出不一樣的資料,比對過程快,不用 O(N) 一筆筆比對,且只需要傳輸 hash value 就好,不需要傳完整資料,傳輸量小。
這就是 CAP 理論的取捨,Cassandra 是 AP 系統,捨棄即時一致性,支援高可用和最終一致性,雖然查詢在不同 DB 中查詢相同資料可能會有不同結果,但即便有某台 DB crush,整個 Cluster 仍可繼續接收讀寫請求。
相反地 CP 系統 (e.g zookeepr) 就只有一個 Master,所有寫入他負責並即時同步給 Slave,保證查詢在不同 DB 結果相同,但如果 Master crush 就無法處理寫入請求,要等重新選舉新的 Slave 變成 Master。
不過 Cassandra 仍提供寫入與查詢的 Consistent Level 功能:
Write Consistent Level:
ONE = 只要一個 db ack。QUORUM = 超過一半的 db ack。LOCAL_QUORUM = 超過一半同 region 的 db ack。ALL = 所有 db ack。Read Consistent Level:
ONE = 只問一個 DB。QUORUM = 向多個 DB 讀,取交集保證一致性。LOCAL_QUORUM = 向多個在同一個 region DB 讀,取交集保證一致性。如果 Read Consistent Level 設定 QUORUM 取交集時發現有人落後觸發 Read Repair,會馬上同步給他。
SSTable 是有序結構,查詢可以 O(logN) 完成,但相同 key 會散落在多個 SSTable,因此會是 O(m * logN)。
在定義 Schema 時,除了 sharding key 以外還可有 clustering key,例如:
CREATE TABLE orders (
user_id UUID,
order_id UUID,
product TEXT,
ts TIMESTAMP,
PRIMARY KEY ((user_id), order_id, ts)
);
user_id 為 sharding key,(order_id , ts) 為 clustering key,相同 user_id 資料會在用 order_id & ts 去排序,可用於範圍查詢。
此外 Cassandra 也支援額外的 Index,例如 Secondary Index 的 SSTable 結構是 key 為 index column,value 為 primary key,Secondary Index 會依照 index column 進行 sharding,因此用 secondary index 查資料很可能會跨 sharding 查詢。
另一種是 SSTable-Attached Secondary Index (SASI),在單個 SSTable 底下在建立額外的 index 結構 (e.g B-Tree or Trie),少一個 sharding 的管理,且搭配 sharding key 查詢效果佳應用廣 (e.g B-Tree 的 range 跟 Trie 的 prefix match 查詢)。


 iThome鐵人賽
iThome鐵人賽