Transformer 是深度學習領域中最具代表性的模型之一,自 2017 年由 Vaswani 等人提出以來,已成為自然語言處理(NLP)與電腦視覺(CV)等多領域的核心技術。其最大特點在於 完全捨棄了循環神經網路(RNN)與卷積神經網路(CNN),而改以 自注意力機制(Self-Attention) 來建構序列表示。
嵌入層(Embedding Layer)
將輸入的文字或特徵向量轉換為固定維度的向量表示,並加上 位置編碼(Positional Encoding),以保留序列中單詞的先後順序。
編碼器(Encoder)
每一層包含兩個子模組:
多頭自注意力機制(Multi-Head Self-Attention)
允許模型同時從不同角度學習序列中的關聯性。
前饋全連接層(Feed Forward Network, FFN)
對注意力輸出的特徵進行非線性轉換。
解碼器(Decoder)
除了具備與編碼器相同的結構外,還增加了 遮罩多頭注意力(Masked Multi-Head Attention),以確保在生成過程中,模型僅能利用當前與過去的資訊,而不會「偷看」未來的輸出。
給定輸入向量 Q、K、V:
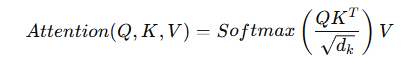
這個公式的核心思想是:計算輸入序列中不同位置之間的關聯性(相關度),並據此加權求和。
並行化運算:不同於 RNN 必須逐步處理序列,Transformer 可以同時處理所有位置的資料,大幅提升訓練速度。
長距依賴建模:自注意力能捕捉遠距離單詞之間的依存關係,優於傳統序列模型。
可擴展性高:透過疊加更多層的編碼器與解碼器,能在不同任務中靈活應用。
Transformer 的出現徹底改變了深度學習的研究與應用方式,它不僅在 NLP 任務上奠定了基礎,還推動了 BERT、GPT 系列、Vision Transformer (ViT) 等眾多模型的誕生。如今,Transformer 已不只是 NLP 的工具,更是跨領域人工智慧的標準架構。

