在自然語言處理與生成式 AI 的發展中,Self-Attention(自注意力) 機制可說是顛覆傳統模型的一大突破。傳統的 RNN 或 LSTM 主要依靠序列的順序進行處理,因此在處理長距離依賴關係時,往往會遇到梯度消失或記憶困難的問題。而 Self-Attention 則透過一種「全局關注」的方式,使得模型能在同一層中同時考量序列中不同位置的資訊。
Self-Attention 的核心公式如下:
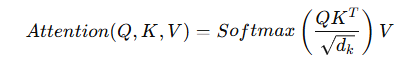
其中:
Q(Query):表示查詢向量
K(Key):表示關鍵向量
V(Value):表示數值向量
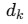 :為向量的維度,用來進行縮放,避免內積值過大
:為向量的維度,用來進行縮放,避免內積值過大
這個機制的力量在於,它能夠快速計算序列中任意兩個元素之間的關聯性。例如,在一句話中,模型能夠讓「它」這個代詞,正確地對應到前面提到的某個名詞,而不必受限於序列的距離。
相比之下,傳統的序列模型需要逐步傳遞訊息,導致長依賴問題。而 Self-Attention 的計算是平行化的,能同時處理整個序列,因此在運算效率與語意理解能力上,都有明顯優勢。
也因為這項特性,Self-Attention 成為 Transformer 架構 的基石,並進一步推動了 BERT、GPT 等大型語言模型的誕生。它不僅僅提升了模型的準確度,更讓生成式 AI 在翻譯、對話、文本生成等任務中展現出前所未有的能力。

