Self-Attention 的核心概念
Self-Attention(自注意力)機制是 Transformer 成功的關鍵。在這個機制中,模型會將輸入序列中的每個詞與其他詞建立關聯權重,從而決定「該關注哪些詞」。這裡就涉及三組向量:查詢(Query)、鍵(Key)和值(Value)。
Q / K / V 的角色
每個輸入詞(token)會先被轉換為向量表示(Embedding),接著再透過三個不同的矩陣轉換,分別得到:
Query(Q)查詢向量:代表「我要找什麼」
Key(K)鍵向量:代表「我能提供什麼」
Value(V)值向量:代表「具體的資訊內容」
計算注意力分數
模型會將 Q 與所有的 K 做點積運算,得到「相關性分數」(score(Q,K)=Q⋅Kᵀ)。這些分數代表當前詞應該關注其他詞的程度。
舉個例子,句子 「小明把蛋糕送給小華,他非常開心」 中,當處理「他」這個詞時,「他」的查詢向量會逐一去和其他詞(如「小明」、「小華」)的鍵向量計算相似度。如果「小華」的分數較高,模型就會給「小華」更大的權重,並從「小華」的值向量中提取更多資訊,最後在「他」的表示中體現出「小華」這個對象。
縮放點積注意力中的 √dₖ
當 Q 和 K 向量維度很大時,它們的點積值也會變得很大。若直接送進 Softmax,輸出會過度偏向單一位置,導致模型訓練不穩定。
為了避免這個問題,Transformer 在計算時會將點積結果除以√dₖ,把數值縮小到合理範圍,讓 Softmax 的輸出更平滑,提升模型的收斂速度與穩定性。
√dₖ的補充說明
√dₖ代表的是 Key 向量的維度的平方根。
假設每個 Query 和 Key 向量的長度是 64 維,那麼dₖ=64,
√dₖ=√64=8,
這個數值用來「縮小」Q·Kᵀ 的結果,避免數值過大。
舉例來說:
如果不做縮放,Q·Kᵀ 的值可能落在 數十甚至上百的範圍,經過 Softmax 之後,分布會極度偏向某個詞(例如 0.999 與 0.001)。
但縮放後,值會被壓回較小範圍,Softmax 的輸出分布就會更平滑(例如 0.6、0.3、0.1),模型才能在訓練時學到更穩定的注意力分配。
Softmax 與加權 V
接著,這些相關性分數會經過 Softmax 正規化,轉換成「注意力權重」(介於 0~1 之間)。最後,模型用這些權重對應到的 V 向量進行加權平均,算出最終的語意表示。換句話說,新的表示同時融合了與其他詞相關的重要資訊。
輸出 Hidden States
經過這一連串步驟後,每個詞都會產生一個新的隱藏表示(Hidden State),它不再是孤立的詞,而是帶有整句話脈絡的向量。這些向量會再送進 Transformer 的下一層,進一步加工處理。
圖片補充說明
(圖片:Self-Attention 機制圖解,展示了 Embedding → Q/K/V → 相似度計算 → Softmax → 加權 V → Hidden States 的流程)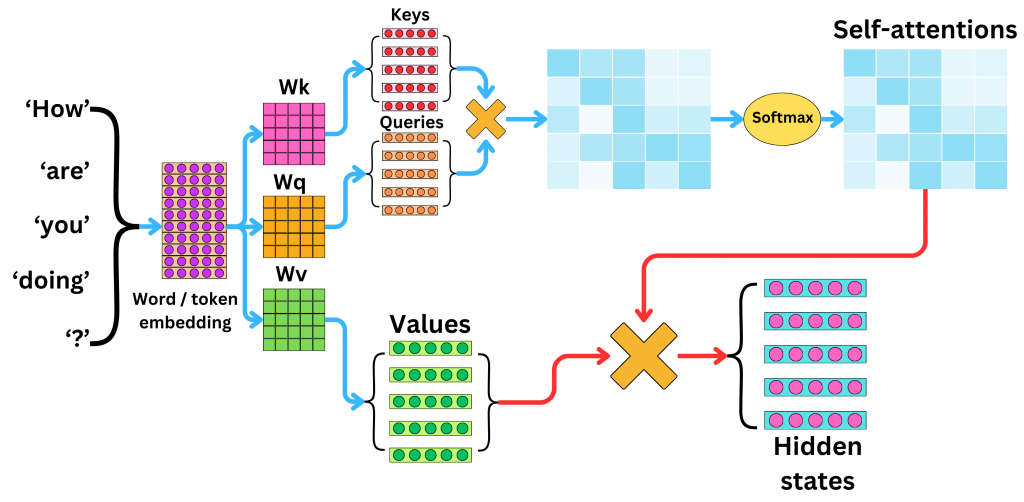
左邊:輸入文字(例如 “How are you doing ?”)先轉成 Embedding。
中間:透過 Wq、Wk、Wv 轉換出 Q、K、V。
右邊:Q × K 得到關聯分數 → Softmax 正規化 → 加權 V → 輸出新的 Hidden States。
因此,模型在處理單一詞語時,能同時融合整句話的上下文資訊。
多頭注意力(Multi-Head Attention)的優勢簡述
前面介紹的是單一頭的注意力運算,但實際上 Transformer 並不是只用一個注意力頭,而是同時運行多個注意力頭,這就是所謂的 Multi-Head Attention。
Q、K、V 向量會被平行分成多組「頭」(heads),每組頭有自己的投影矩陣。
每個頭可以專注在不同層次或關係,例如一個頭捕捉語法結構,另一個頭專注語義,還有頭專注於指代。
各頭的輸出會再合併(concat)起來,透過線性投影形成最終結果。
多頭的好處是能讓模型從不同角度同時理解語言,比單一注意力頭更強大、更穩健。這也是 Transformer 在 NLP 任務上表現突出的原因之一。
結語
自注意力機制透過 Q、K、V 三組向量巧妙地實現了序列中詞與詞之間的動態關聯。縮放點積讓訓練更穩定,而多頭注意力則讓模型能「一心多用」,從不同角度捕捉語言特徵。瞭解這些設計,有助於我們理解 Transformer 為何能勝過傳統模型。
在下一篇文章,我們將探討另一個關鍵元素:位置編碼(Positional Encoding),看看 Transformer 如何在沒有序列結構的情況下表示詞語的順序。

