
『人沒有反省能力最可怕,LLM 也一樣。』 -- 沒有人說過
前幾天介紹了 LLM 完全可以做到 task decomposition 甚至還能自己使用 tools,但在 LLM Agent multi loop 的過程,如果我們不明確指出這是一個錯誤的方向,LLM 很長會鑽牛角尖,卡在 thought loop 中。那怎麼辦呢?
我們以強化學習 (RL) 的角度來說,LLM 在提出下一步要做什麼的時候,其實有點像是根據 policy 去做選擇。
那當我們今天提供了這是一個錯誤方向的舉證,並且把其放入 context 中,其實就是間接的改變了 LLM 的 policy 。
這篇論文提到蠻多次也提了很多篇論文都 claim: Agent 在 reflection 後就 significant performance improvement。
拿 CRITIC [1] 這篇論文來舉例好了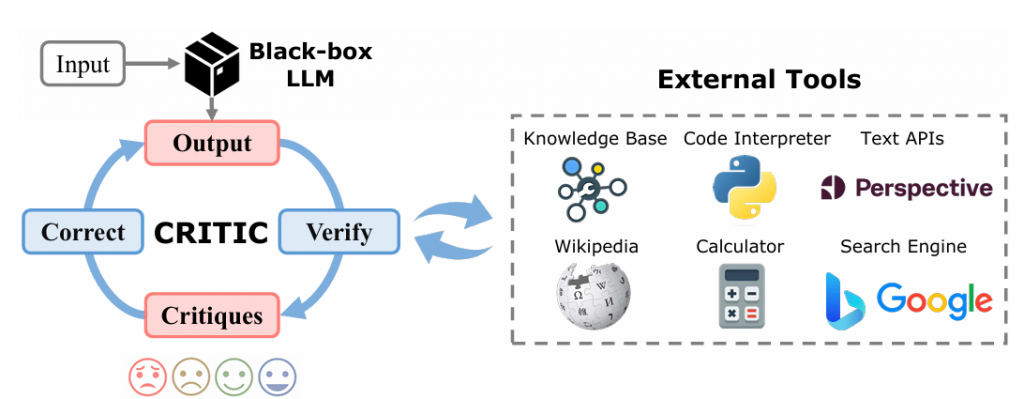
可以看到外部工具還能當作是驗證 sub goal 的方向是否正確。
像這種跳脫原本 LLM 能力的工具,最能讓LLM重新回到正軌,不在死胡同裏面打轉。
好 那應該已經有一些初步的概念了。
那我們來細分 Reflection 與 Refinement 在幹嘛吧 (這邊論文其實沒有細講,所以以下片段除了讀論文的心得外也 包含我個人的拙見,將就看就好,有什麼想法也歡迎底下討論喔)
在 Reflection 階段,我認為最關鍵的問題是:如何驗證 LLM 的行動(action)是錯的?
更進一步來說,我們又該如何提示 LLM 它的決策有誤,並引導它進行反思?
因為如果我們無法明確指出錯誤,Agent 很可能會持續在錯誤的路徑上反覆嘗試。
我的想法是:
關鍵點在於:失敗的定義要足夠清晰,這對 Reflection 的成功至關重要。
在完成 Reflection 之後,下一步就是:如何讓 Agent 精煉(Refine)自己?
有兩種直觀的想法:
第一點很暴力,可能也有用?但是在實際應用場景中可能沒那麼適合,因為訓練時間太久了,而且也浪費資源。這邊暫時不討論
for 第二點這樣做的好處是:只要修改上下文,就能改變 LLM 的輸出/行為,而不需要重新進行模型微調。 這正是 LLM 的強大之處。
這邊有個 NVIDIA 在強化學習(Reinforcement Learning, RL)領域中,一個有趣的發表叫做:
Eureka: Human-Level Reward Design via Coding Large Language Models。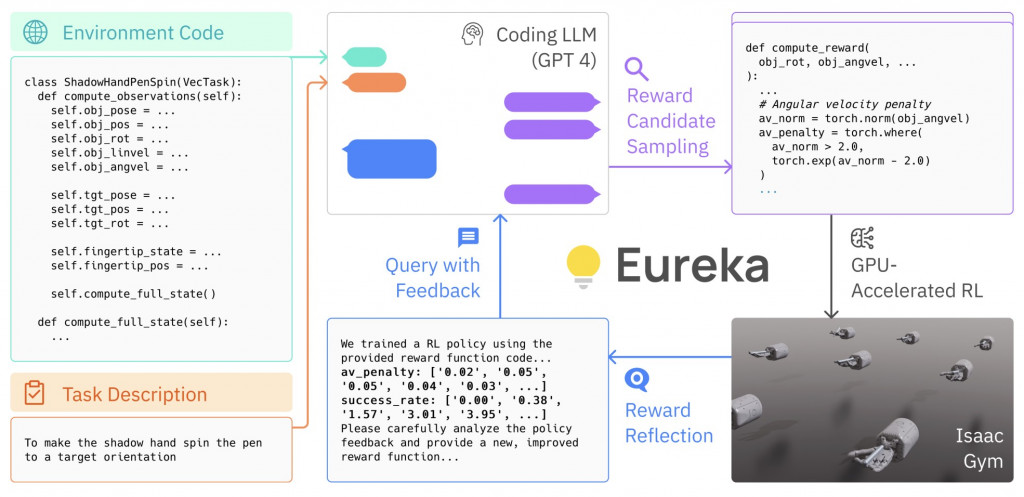
這篇研究的核心思想就是:讓「會寫程式的 LLM」自動寫獎勵函數(reward code),用於機器人/模擬環境的 RL 訓練。如上圖
整個流程如下,LLM 依目標與介面生成 reward 程式 → 在模擬器內訓練/評估 → 以表現回饋自動改寫 reward 程式。
結果在多個控制/操作任務上,超越人工設計的獎勵或匹敵 SOTA。
這邊和 Reflection 提到的把反省訊號做成可執行測試/分數,讓 LLM 在「可驗」的循環裡優化策略,而非只在語言層面自說自話,讓 LLM 更有依據去做改進。
不過,這裡仍然存在兩個瓶頸:
總結來說,Agent 的最終表現,會同時受到 LLM 的能力 以及 可用工具的完整度 所限制。
今天主要分享了 Agent 如何在整個任務流程中做反省與提煉...
明天再來繼續探討該如何更新 memory
ref:
[1] CRITIC: LARGE LANGUAGE MODELS CAN SELF CORRECT WITH TOOL-INTERACTIVE CRITIQUING
[2] Eureka: Human-Level Reward Design via Coding Large Language Models
