今天我們來探討 LLM Agent 上的 Memory 記憶機制
畢竟是 2024 年的論文了,論文在 memory 這個 component 上只分析了兩大方向
RAG-based Memory
用 similary search 找出與目前 scenario 最相近的過往的記憶。
Embodied Memory
直接透過更改 model 的 params 來達到記憶的效果。
但其實在現在由於 model 越來越強,能吃的 input token 也越來越多,直接把 context 當作是 memroy 同時送給 gpt 也不失是一種最暴力且有效的方法。
What is RAG?
RAG stand for Retrieval-Augmented Generation(檢索增強生成),核心做法是把 記憶與embedding 用某個外部儲存系統 (vector db) 存起來,使用時先用 similary search 將與目前任務最相關的“記憶”取回,再交給生成模型整合回答。經典做法把向量索引(常見如 FAISS)當「非參數化記憶」。
RAG [1] 流程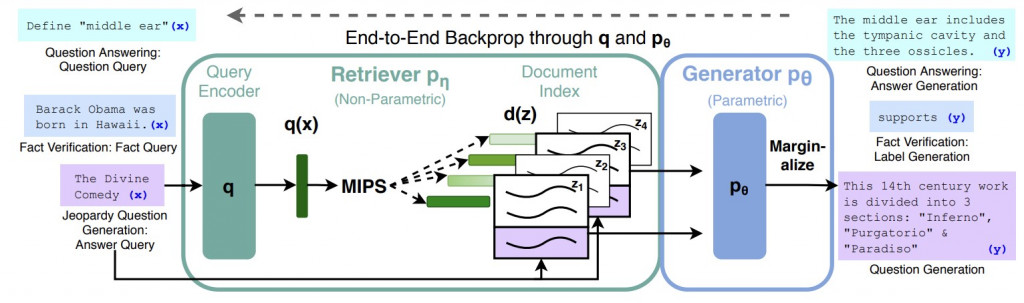
圖中可以看到主要有兩個 components:
retriever & generator
首先問題進到 retriever 後,
然後根據 document index 產生答案,這邊的 document index 應該也不是可讀文本,而是我們無法解釋的參數
那這樣有什麼好處?
把 retrieve 用在 tools 上應該很好理解。用在 LLM Agent 的 Memory,最主要的目的應該是,如果我們儲存了所有 multi-loop 的過成,那即使 llm context windows 變大了,一次餵給他可能也有太多雜訊,導致生成品質不好。
所以我們只需要 “參考” 與目前問題有關的歷史紀錄就好
Embodied是什麼意思?
在這裡的 embodied 指的是把「經驗」嵌進模型參數本身:用(全量或參數高效的)微調,讓代理在與環境互動所累積的軌跡、偏好與技巧,成為模型的內隱記憶,而不是放在外部向量庫。這通常靠 PEFT(如 LoRA、QLoRA、P-tuning、IA³)把需訓練的參數降到很小,降低成本與顯存需求。
為什麼要用 Embodied Memory?
當能力需要隱性技巧/模式(例如長期規劃、分解與行動選擇),把經驗「寫進參數」能讓模型少依賴提示工程、推理更穩定(?)。相對地,RAG 擅長事實/知識補全;embodied 則更像習得策略。上述工作均顯示在規劃/代理任務上,微調能帶來實質效益。
Catastrophic Forgetting 問題
微調有個好處是,訓練完後真的能在這部分的能力顯著提升,所以如果使用時的情境與微調時類似 (絕大部分沒問題),但微調完後其他能力可能會明顯下降。
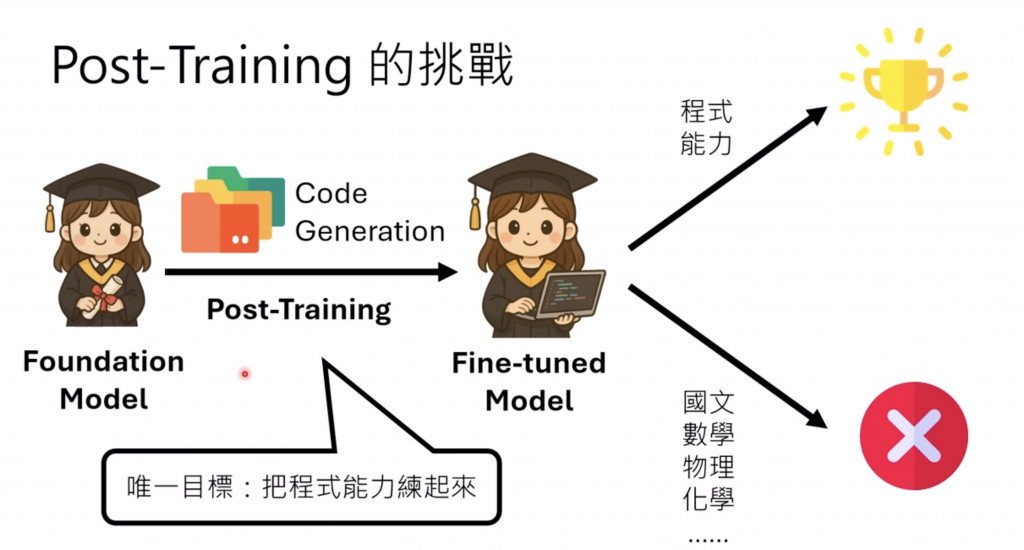
這邊李弘毅老師有在 【生成式AI時代下的機器學習(2025)】第六講:生成式人工智慧的後訓練(Post-Training)與遺忘問題[2] 更深入地提到,我真的覺得很讚。有興趣可參考
我一直在想,"Memory" 之於 "LLM Agent" 到底是否等同於 "心臟" 之於 "人類" 一樣重要? 他是否是整個 LLM Agent 重要且不可或缺的一部分?
因為在 RL 領域中,有個概念是 Markov Property。
什麼是 Markov property 呢? 就是在某些遊戲(環境)中,你完全不必知道過去發生了什麼,也能毫無影響的繼續做出決策。簡單來說就是:當下環境 (current state) 已經包含過去所有發生的事。
這邊舉個例子 像是 Sokoban [3] 這個遊戲:
Sokoban 的遊戲目標是,移動角色 將對應的箱子推到目的地 (也就是下圖紅色的點)
那以上面這張圖來看,我應該可以不用知道過去做了什麼,就能正確的繼續將箱子推到目的地吧(?)
就是這種現象,memory mechanism 在某些任務上,會不會其實對於 LLM Agent 沒有那麼重要?
當然,我這邊想推翻我自己的想法。因為其實換句話來說 env (上面那個環境),其實也算是表達 memory 的一種方法?
那那那 再換句話來說,我們的 memory 的重點會不會其實也就只需要 maintain 一個類似 env 的環境就好?
恩。太有趣了
週末居然要寫文章 我太難了
ref:
[1] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
[2] 【生成式AI時代下的機器學習(2025)】第六講:生成式人工智慧的後訓練(Post-Training)與遺忘問題
[3] Sokoban wiki

