接下來要來介紹的是 NLP 中,不可或缺的「斷詞」,也可以說「分詞」!
但今天我們不做程式的實作,而是先釐清兩個常見,但可能會有點小混淆的概念:Tokenization 和 Segmentation。
這兩個常常一起出現的詞到底是同義詞,還是他們有什麼些微的不一樣呢?其實我原本也搞不太清楚,所以今天就來說明一下~
但首先我們要問:
就像我們要完成一個很大的任務時,會先切成一塊塊的小任務一樣。一段很長很長的文字,處理起來很費力,所以我們會先將文字拆成較小的單位,通常就是 詞(word)。
在中文裡,句子長這樣:我愛自然語言處理。斷詞任務就是要去判斷詞的邊界到底在哪裡。可能是我/愛/自然/語言/處理 或是 我/愛/自然語言/處理。
這時你可能會覺得,英文裡面有空格可以當作天然的斷詞器,真方便!同一句話 I love NLP 就可以簡單的切分成三個單字 I/love/NLP
但其實英文的斷詞也是一門學問~像是 I live in New York,要斷成 I/live/in/New/York 嗎?但是 New York 明明就是一個地名,是不是應該要放在一起呢?
除了合併成更大的單位,還有另一個問題是斷成更小的單位。像是 interesting, interested, exciting, excited,是不是可以拆成interest 跟 excite 加上後綴 -ing 跟-ed,所以其實一個詞(word)不一定是最小單位哦~
這些就是 tokenization 和 segmentation 要解決的核心問題,最小單位的邊界要如何劃定。而拆分的策略也會影響後續任務的效果,先理解這些差異才能去判斷何時要切成字(character)、詞(word)、或子詞(subword)。
Segmentation 是分割的意思,如果是講斷詞就會說 Word Segmentation。這個詞的重點是把文字拆成「語義上合理的詞」的過程,因此更強調詞的語義邊界,以得到符合語言學分析和應用需求的最小單位。後續就可以用於詞頻統計、詞性標註、NER(命名實體識別)等等下游任務。
像是中文、日文等等沒有空格的語言,在處理上特別需要這樣詞彙為基礎的單位來做 NLP 任務。
Tokenization 翻成「標記化」,它強調的是把文字拆成模型可處理的「標記(token)」的過程。在 NLP 任務很常聽到 token,那 token 到底是什麼?
Token 是一個沒有固定長度的最小單位,它可以是字(character)、詞(word)、或子詞(subword),任何一種長度,看你的任務需要把文字拆分到多細。Tokenize 過後的文字通常是會輸入進模型做處理,因此不一定要符合語義完整性。
像是使用 ChatGPT 時,可能會碰到「超出 token 限制」,這個 token 就是 OpenAI 自己內部定的長度,算法有點謎XD,但是可以透過 這個網站 去幫你計算
當我們輸入「自然語言處理」,可以看到有 6個字 (Characters),但切成5個 tokens 自然/語/言/處/理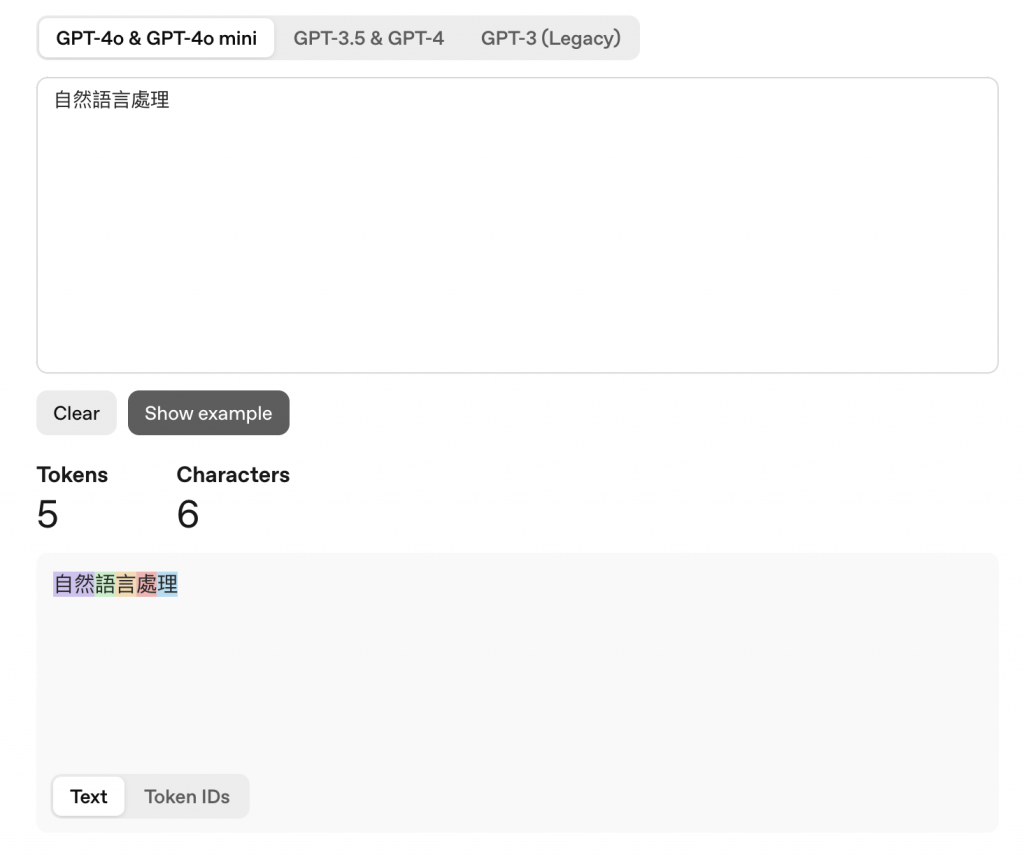
而這些 token 會轉成編碼(ID),讓電腦可以處理,自然->116258/語->40909/言->17765/處->129805/理->5584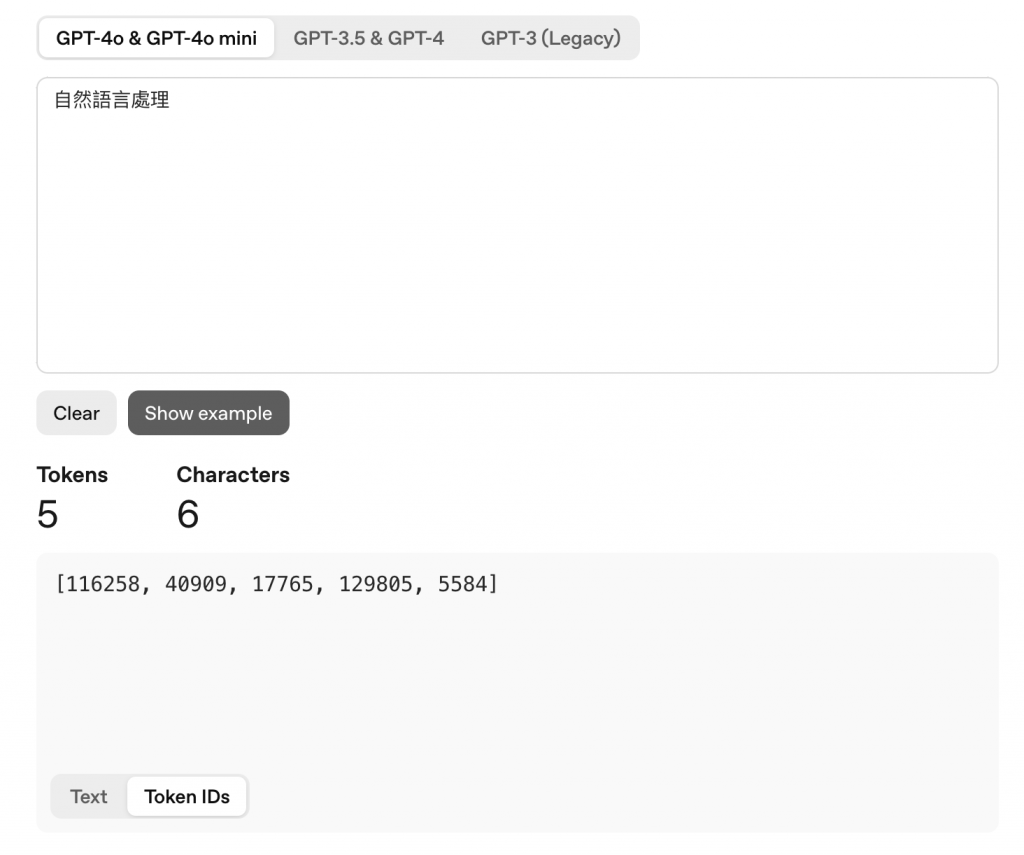
而為什麼說算法有點迷呢?這邊分享一個有趣的例子
當我們輸入 Natural Language Processing NLP,會算成 4個tokens Natural/Langauge/Processing/NLP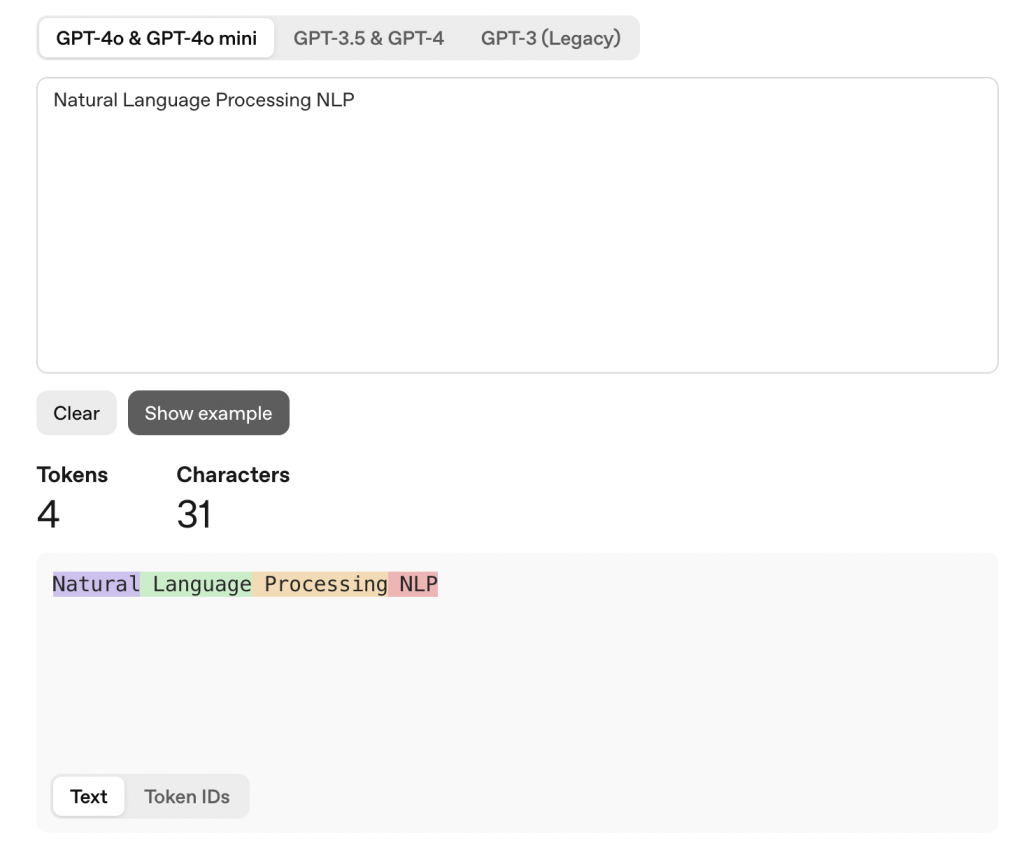
但 NLP 加上括號變成 Natural Language Processing (NLP)時,token 的切法就變成 7個tokens Natural/Langauge/Processing/(/N/LP/),NLP 被分開了
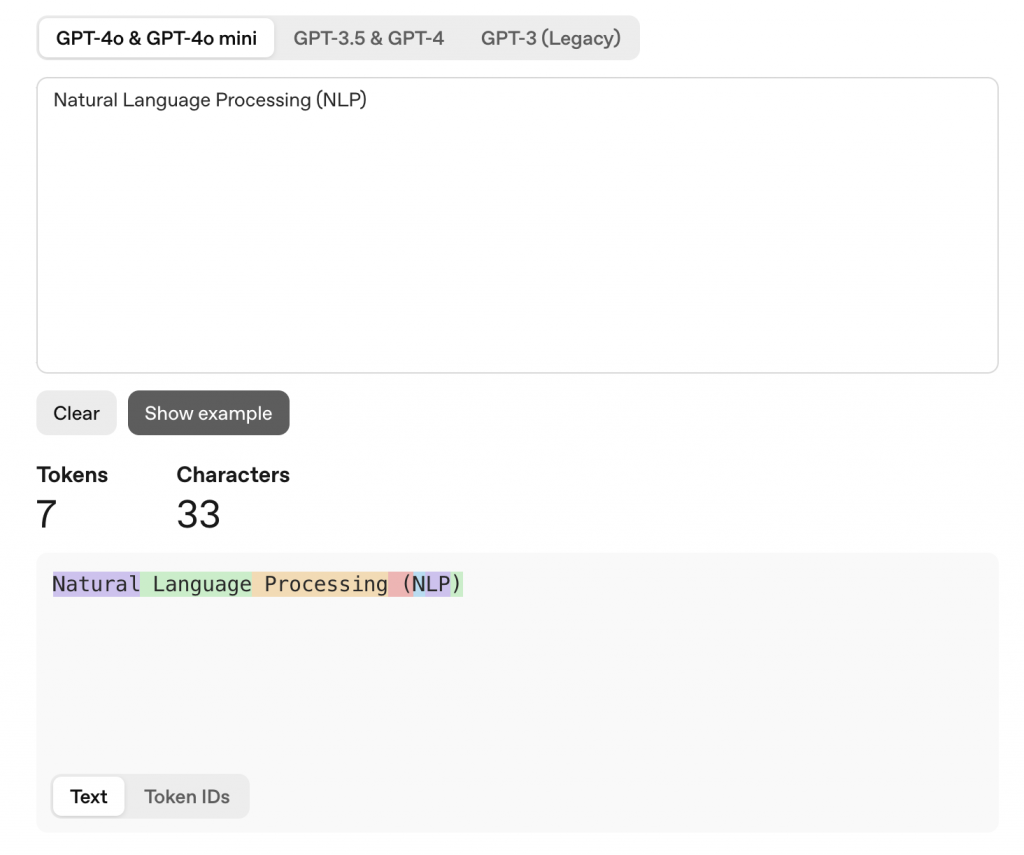
所以雖然有人會說 tokenization 是斷詞,但 tokenize 後的結果其實不一定是詞哦~
今天的內容主要釐清了一些 Tokenization 和 Segmentation 的些微差異。Tokenization 著重在模型的可處理性,Word Segmentation 則注重語義完整性。
在斷詞前,先釐清下游任務的需求,再決定拆分的單位,這樣才能確保後續的任務有好的表現!
明天的內容要帶大家做一些基礎的中文斷詞實作啦~~
text = "小明的手機號碼是: 0912-345-678,市話號碼是:02-777-0909,email是: xiaoming123@gmail.com。"
re.findall() 找出所有的號碼(提示:用\d{})pattern_numbers = r"\d{2,4}-\d{3,4}-\d{3,4}"
numbers = re.findall(pattern_numbers, text)
print(numbers)
# === Output ===
['0912-345-678', '02-777-0909']
re.search() 找出第一個 emailpattern_email = r"\w+@[a-z]+\.com\.?[a-z]*"
email = re.search(pattern_email, text)
print(email.group())
# === Output ===
xiaoming123@gmail.com
re.sub() 把手機號碼改成 +886-9XX-XXX-XXX(提示:用括號分組再替換)pattern_phone = r"09(\d{2})-(\d{3})-(\d{3})"
result = re.sub(pattern_phone, r"+886-9\1-\2-\3", text)
print(result)
# === Output ===
小明的手機號碼是: +886-912-345-678,市話號碼是:02-777-0909,email是: xiaoming123@gmail.com。

