介紹
簡單的介紹一下已經不紅 RAG,從大家開始發現 AI 幻覺的時候就一直希望可以找到一個方法讓 AI 不再亂說話,過了一些日子 RAG 是否真的如當初試想的一樣(概念很好)?現在偶爾會在網路上看到一些相關的討論,認爲 RAG 完全 useless,因爲在前期準備資料的時候可能已經把整個資料拆碎,導致後期真的在檢索資料的時候找不到完全正確的訊息,讓 AI 反而參考了一堆無意義的資料導致更容易出錯。這邊簡單回顧一下 RAG 的概念以及定義。
基本概念
何謂 RAG?
- 廣義上的 RAG:生成答案之前有從外部知識庫或資料來源抓資訊來輔助
- 狹義上的 RAG:標準的 RAG 流程,包含將問題向量化 -> 使用密集型向量查詢 -> 取出 top-k 的資料片段給 LLM 產生回答
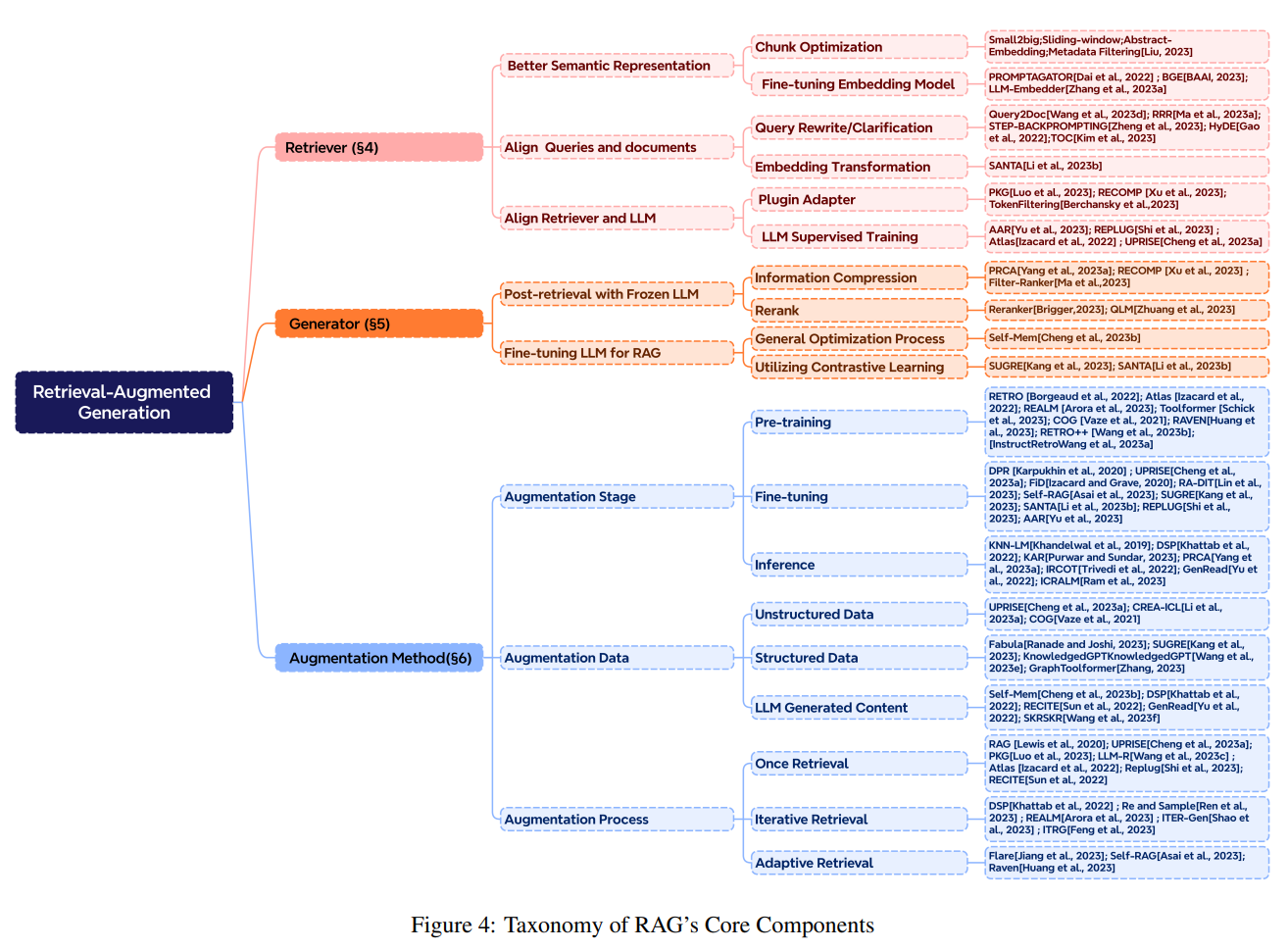
RAG 架構
直接從 RAG(Retrieval-Augmented Generation)的全名開始:
- Retriever(檢索器):負責把使用者問題轉換成向量,並取從資料庫找出最相關的片段
- Augmented(增強):將使用者提出的原始問以及檢索出來的結果合併成 Context
- Generator(生成器):接收到新的 Context 之後,透過 LLM 生成最終回答
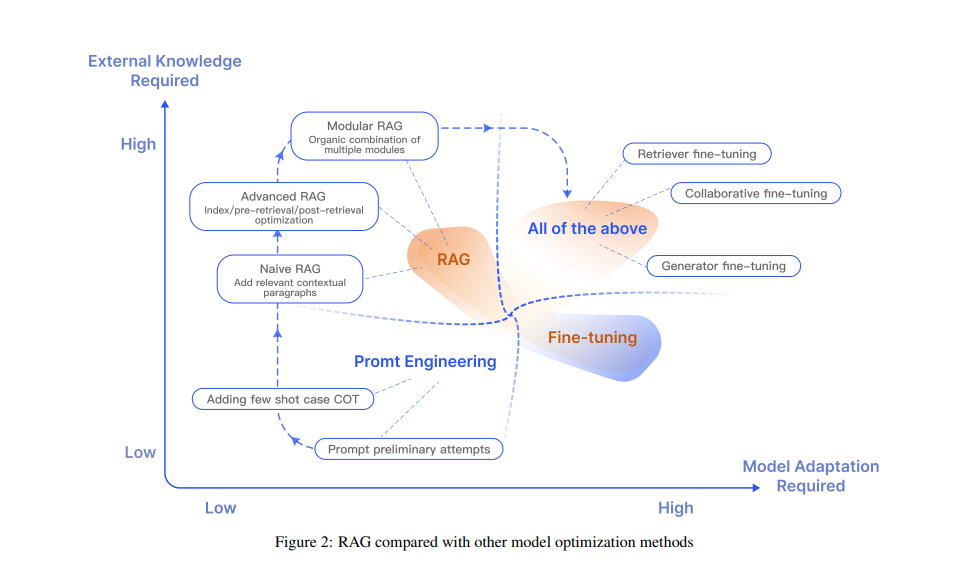
RAG 分類
-
Naive RAG(Indexing, Retrieval, Generation):檢索結果常常不精準或不完整
-
Advanced RAG:在 Naive RAG 基礎上,加入前置(Pre-Retrieval)與後置(Post-Retrieval)方法來改善檢索與生成
-
Pre-Retrieval Process:在建立索引前就優化資料,例如更細粒度分段、改善索引結構、加上中繼資料、設計對齊問題、混合不同檢索方式
-
Embedding:使用更好的向量表示,例如針對領域微調或依上下文動態調整(Dynamic Embedding)
-
Post-Retrieval Process:對檢索結果再做調整,例如重新排序(ReRank)、過濾雜訊、摘要壓縮
-
Modular RAG:把檢索流程拆解成更多模組,能依需求自由組合或替換,提供更靈活的架構。
-
Search Module:除了語義檢索,也能用 SQL、知識圖譜或搜尋引擎
-
Memory Module:利用 LLM 自身的記憶功能引導檢索
-
Extra Generation Module:不只檢索,也用 LLM 生成輔助內容來補足上下文
-
Alignment Module:透過適配器或強化學習,改善查詢與文件的語義對齊
-
Validation Module:檢查檢索結果是否可靠,避免把錯誤資訊送進 LLM
未來展望
作者最後針對 RAG 未來的發展提出了兩個方向,分別為 Vertical Optimization of RAG 以及 Horizontal expansion of RAG
- Vertical Optimization of RAG:著重在增加檢索出來的品質
- Horizontal expansion of RAG:著重在提供更多元的資料(圖片、程式、聲音、影片等...)
參考資料
@article{gao2023retrieval,
title={Retrieval-augmented generation for large language models: A survey},
author={Gao, Yunfan and Xiong, Yun and Gao, Xinyu and Jia, Kangxiang and Pan, Jinliu and Bi, Yuxi and Dai, Yixin and Sun, Jiawei and Wang, Haofen and Wang, Haofen},
journal={arXiv preprint arXiv:2312.10997},
volume={2},
number={1},
year={2023}
}


 iThome鐵人賽
iThome鐵人賽