前幾天的標題我都只放了主題,今天突然靈光乍現,覺得用「我在你心裡究竟是什麼地位」這句話來比喻 TF-IDF 非常的貼切🤣
沒錯,TF-IDF 的核心概念,其實就是在探討不同字詞在不同文本當中,到底「地位如何」。
因為我們在做 文本分析(Text Analysis) 或是 資料檢索(Information Retrieval) 時,會想要知道:
👉🏻 哪些字詞只是一般雜訊?
👉🏻 哪些字詞才是真正能代表這篇文章的「關鍵」?
透過 TF-IDF 這個加權方法,我們就能抓出文本的重點。
要了解 TF-IDF ,必須先把它 TF 跟 IDF 分開來看!
TF 為 Term Frequency ,也就是詞的頻率。
計算方式:某詞在一份文件裡出現的次數,除以文件的總詞數。
👉🏻 它能幫助我們比較不同長度的文章,因為如果只單看詞出現的次數,那麼長度很長的文本有很大可能會佔優勢
例:如果一篇文章 100 個字裡,「迪士尼」出現了 10 次,那麼它的 TF = 0.1。
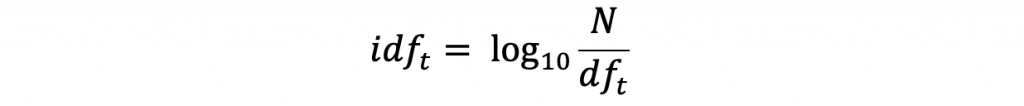
分母的 df 為 document frequency , 一個字 t 的 df 為他出現在所有文件當中,幾個不同的文件篇數,分子的 N 為所有文件的篇數。
IDF 為 Inverse Document Frequency ,目的是用來衡量一個詞在所有文件中「稀有度」。
👉🏻 出現越多次 → 分母越大 → IDF 越小 → 代表性越低
👉🏻 出現越少次 → 分母越小 → IDF 越大 → 代表性越高
例:
每部迪士尼電影都有「美女」,所以「美女」並不是特別有代表性的詞;
但「野獸」只會在《美女與野獸》出現,因此能更好代表這部電影。
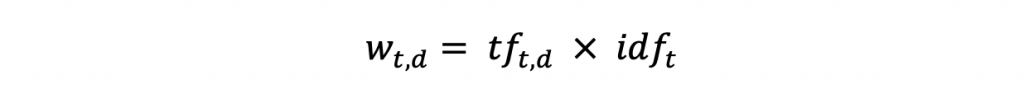
TF-IDF 即為 TF x IDF ,是一種權重的概念,可以知道不同字詞的代表性為何。
⭐️ 當兩個詞的在兩個文本裡面詞頻一樣時,可以透過IDF得知哪個詞的代表性比較高
搜尋引擎可以用 TF-IDF 來評估「某篇文章和搜尋關鍵字的相關性」。
👉🏻 TF-IDF 是用來「排序與查詢最相關的文件」。
在機器學習(Machine Learning)裡,TF-IDF 常常被用來把文字轉換成「數值向量」,讓電腦能夠處理:
👉🏻 TF-IDF 被當作一種「抓取特徵」的工具。


 iThome鐵人賽
iThome鐵人賽