接續昨天 N-gram 的介紹,今天來繼續講講 N-gram~~
昨天有提到,如果要用「所有前文」來預測下一個字(或下一個詞),這樣做會遇到一個大問題:
👉 因為機率要一直相乘,隨著句子變長,數值就會越來越小,小到幾乎是 0,會造成計算的困難。
👉 而且要真的估計「所有前文的組合」的機率,資料量需求會極大,因為語言有無限的創造力,幾乎不可能有完整的語料庫。
因此我們有一個折衷的辦法:
就是 The Markov Assumption(馬可夫假設)。簡單來說,就是假設「下一個字只跟前面幾個字有關」。
例如:
Bigram (Bi為2的意思) 模型:預測下一個字只會依賴「前一個字」。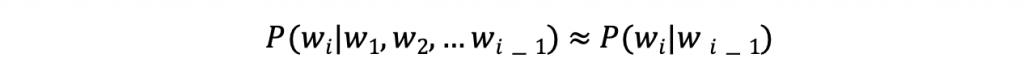
Trigram (Tri為3的意思) 模型:預測下一個字依賴「前兩個字」。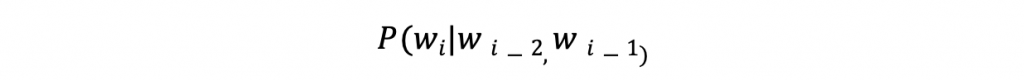
這樣一來,就不用去看前面整句話,而只需要看有限範圍內的上下文,大大減少了運算與資料的需求。
以上就是 N-gram 的一些基本介紹。雖然它簡單,但它作為語言模型發展歷程中重要的一塊基石,開啟了語言可以透過機率來建語言模型的想法!
明天就來介紹介紹 TF-IDF ~~


 iThome鐵人賽
iThome鐵人賽