
在前幾天的實作中,我們已經能夠抓取最新的論文摘要,並且用 Gemini 生成結構化筆記。不過有一個問題:
arXiv 的頁面是 HTML,論文內文通常是 PDF,要進一步給 LLM 分析會比較困難。
這時候就能用 ar5iv —— 一個能把 arXiv 論文轉成 HTML 純文字的服務,方便後續進行自動化處理。
註: 有些論文還沒有ar5iv,可以看看他有沒有提供html,或是直接用n8n 的PDF處理節點(這邊之後有空的話會再研究看看,畢竟PDF文件的整理也是很有必要的)
以論文連結 https://arxiv.org/abs/2509.15217v1 為例:
原始 arXiv 頁面
https://arxiv.org/abs/2509.15217v1
HTML 對應頁面
https://ar5iv.org/abs/2509.15217v1
HTML對應頁面https://arxiv.org/html/2509.15217v1
只要把 **arxiv.org → ar5iv.org 或arxiv.org/html **就能直接取得 HTML 版本的內容。
這裡示範用 Function Node (Python) 進行網址替換,直接將輸入的 arXiv 連結轉為對應的 ar5iv 連結:
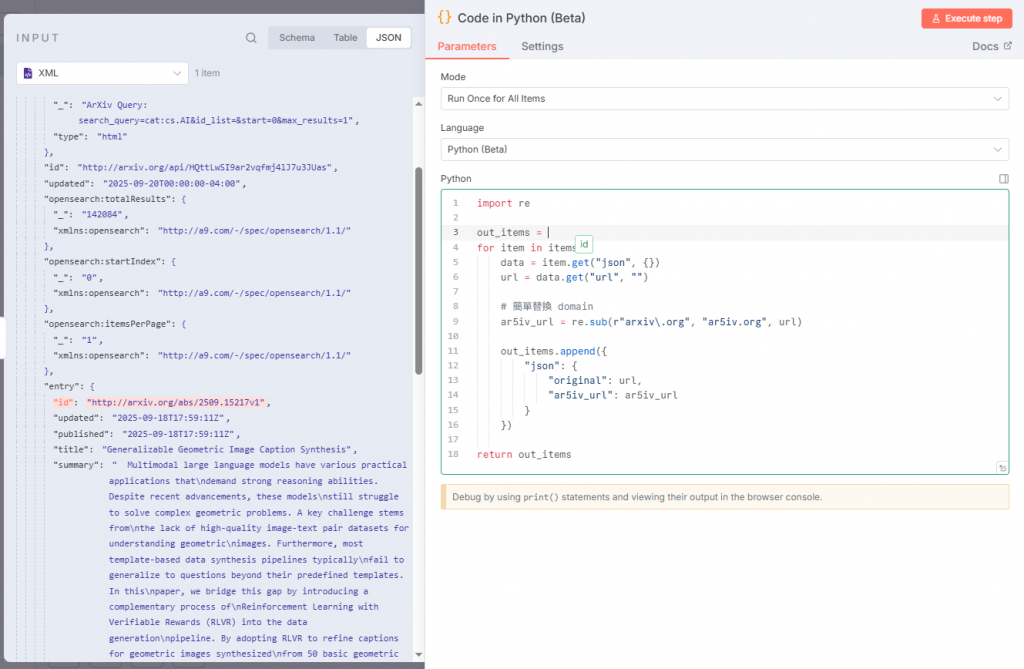
import re
out_items = []
# 取第一筆輸入的 feed.entry.id
first_id = None
if items and "feed" in items[0].get("json", {}):
first_id = items[0]["json"]["feed"]["entry"]["id"]
for item in items:
data = item.get("json", {})
# 先用 url 欄位,如果沒有就 fallback 到第一筆的 feed.entry.id
url = data.get("url", "") or first_id or ""
if url:
# 替換 domain
#ar5iv_url = re.sub(r"arxiv\.org", "ar5iv.org", url)
ar5iv_url = re.sub(r"arxiv\.org\abs", "arxiv.org/html", url)#有些文章還沒有上傳到ar5iv
else:
ar5iv_url = None
out_items.append({
"json": {
"original": url,
"ar5iv_url": ar5iv_url
}
})
return out_items
接下來用http get 取得內文然後再接python處理回傳內容
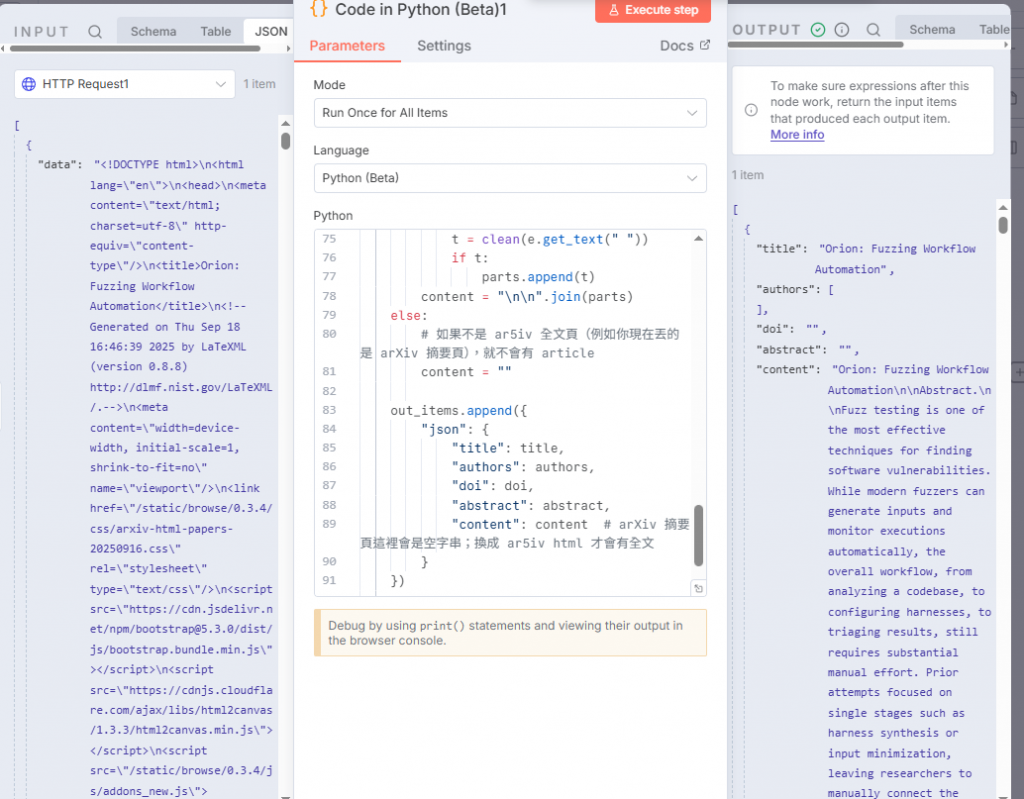
import re
from bs4 import BeautifulSoup
def clean(s: str) -> str:
return re.sub(r"\s+", " ", s or "").strip()
def text_or_empty(tag) -> str:
return clean(tag.get_text(" ")) if tag else ""
out_items = []
for item in items:
data = item.get("json", {})
# 你的 HTML 可能放在不同欄位:body / html / data(你的例子是 data)
html = data.get("body") or data.get("html") or data.get("data") or ""
if not isinstance(html, str):
# 如果上一節點給的是物件而非字串,直接轉字串處理
html = str(html)
soup = BeautifulSoup(html, "html.parser")
# ====== 標題(多種後備)======
title = ""
og_title = soup.find("meta", {"property": "og:title"})
if og_title and og_title.get("content"):
title = clean(og_title["content"])
if not title:
# arXiv 摘要頁常見:<h1 class="title">Title: ...</h1>
h1_title = soup.select_one("h1.title") or soup.find("h1")
title_text = text_or_empty(h1_title)
# 去掉前綴 "Title:"(若存在)
title = clean(re.sub(r"^\s*Title:\s*", "", title_text, flags=re.I))
# ====== 作者(優先 meta,其次頁面可見區塊)======
authors = [clean(m["content"]) for m in soup.find_all("meta", {"name": "citation_author"}) if m.get("content")]
if not authors:
# arXiv 摘要頁:<div class="authors">Authors: A, B, C</div>
authors_block = soup.select_one("div.authors")
if authors_block:
# 抓裡面的連結文字
a_tags = authors_block.find_all("a")
if a_tags:
authors = [clean(a.get_text(" ")) for a in a_tags if clean(a.get_text(" "))]
else:
# 或者整塊剝掉 "Authors:" 前綴再用逗號拆
raw = clean(re.sub(r"^\s*Authors:\s*", "", authors_block.get_text(" "), flags=re.I))
if raw:
authors = [clean(x) for x in re.split(r",\s*", raw) if clean(x)]
# ====== DOI(arXiv 摘要頁會有)======
doi = ""
doi_a = soup.select_one("a#arxiv-doi-link")
if doi_a and doi_a.get("href"):
doi = doi_a["href"]
if not doi:
# 後備:meta citation_doi
m_doi = soup.find("meta", {"name": "citation_doi"})
if m_doi and m_doi.get("content"):
doi = clean(m_doi["content"])
# ====== 摘要(若是 abs 頁會有)======
abstract = ""
abs_block = soup.select_one("blockquote.abstract")
if abs_block:
# 去掉 "Abstract:" 前綴
abstract = clean(re.sub(r"^\s*Abstract:\s*", "", abs_block.get_text(" "), flags=re.I))
# ====== 正文(若是 ar5iv full html 頁會有 <article>)======
content = ""
article = soup.find("article")
if article:
parts = []
for e in article.find_all(["h1", "h2", "h3", "h4", "h5", "h6", "p"], recursive=True):
t = clean(e.get_text(" "))
if t:
parts.append(t)
content = "\n\n".join(parts)
else:
# 如果不是 ar5iv 全文頁(例如你現在丟的是 arXiv 摘要頁),就不會有 article
content = ""
out_items.append({
"json": {
"title": title,
"authors": authors,
"doi": doi,
"abstract": abstract,
"content": content # arXiv 摘要頁這裡會是空字串;換成 ar5iv html 才會有全文
}
})
return out_items
接下來把論文內容傳送到上一篇完成的Gemini節點就完成啦

到這裡,我們已經完成了:取得論文HTML內容,透過 HTTP + Python 解析,取得論文標題、作者、DOI、摘要與全文,接下來把這些內容丟進 Gemini,生成結構化的 Markdown 筆記,並寄送,不過用gmail沒辦法直接閱讀markdown ,因此接下來會介紹如何把筆記整理到notion或是discord 中方便我們閱讀。
