我們要讓 java core app 能把資料存進資料庫,這樣 line bot 未來再把這些資料回傳給使用者。在實作前,先來釐清幾個觀念:Relational Database、SQL、JPA、Hibernate、Spring Data、ORM。
Persistence Layer 的目標是讓 in-memory 的 Java Objects 可以 outlive 在應用程式之外,也就是說,把 Java Objects 存到資料庫。
不過 Java 跟資料庫天本來就有許多邏輯上的落差,造成存取的一些問題,這就是所謂的 object-relational mismatch。接下來以關聯式資料庫 (Relational DB) 來說明。
在《Java Persistence with Spring Data and Hibernate》裡,作者總結了五個典型問題:
Java 可以有複雜的物件,但 SQL 會把物件 flatten 成多個columns
class Cat {
Long id;
String name;
Address address; // embedded object
}
class Address {
String street;
String city;
String zipcode;
}
In SQL:
CREATE TABLE CATS (
ID BIGINT,
NAME VARCHAR(100),
STREET VARCHAR(100),
CITY VARCHAR(100),
ZIPCODE VARCHAR(20)
);
Java 常見的 OOP inheritance 在 SQL 沒有直接對應的邏輯。要一張表還是多張表?
class Cat {
Long id;
String name;
}
class RussianBlue extends Cat {
String furColor = "Gray";
}
class Persian extends Cat {
Boolean needsDailyGrooming = true;
}
In SQL 你可能就用單表的策略來處理,沒有的欄位就 null
CREATE TABLE CATS (
ID BIGINT,
NAME VARCHAR(50),
FUR_COLOR VARCHAR(50), -- 只有 RussianBlue 用
NEEDS_DAILY_GROOMING BOOLEAN -- 只有 Persian 用
);
Cat c1 = new Cat(1L, "Mimi");
Cat c2 = new Cat(1L, "Mimi");
System.out.println(c1 == c2);
System.out.println(c1.equals(c2));
In SQL:
SELECT * FROM CATS WHERE ID = 1;
cat.getCatDetails().getShelterNumber();
But in SQL:
class Cat {
Long id;
CatDetails catDetails;
}
CREATE TABLE CAT_CATDETAILS (
CAT_ID BIGINT,
CATDETAILS_ID BIGINT,
PRIMARY KEY (CAT_ID, CATDETAILS_ID)
);
for (Cat cat : owner.getCats()) {
for (Snack snack : cat.getSnacks()) {
System.out.println(snack.getName());
}
}
In SQL:
SELECT * FROM OWNERS WHERE ID = 1; -- 找到飼主
SELECT * FROM CATS WHERE OWNER_ID = 1; -- 找到飼主的貓咪
SELECT * FROM SNACKS WHERE CAT_ID = ?; -- 每隻貓咪都要查一次 (N 次)
想像你有一個 Owner 物件,裡面關聯了好多 Cat。
Owner owner = em.find(Owner.class, 1L);
for (Cat cat : owner.getCats()) {
System.out.println(cat.getName());
}
ORM(e.g. Hibernate)預設常用 lazy loading:
🐱 一開始 不會把所有貓的資料一次載入,只載入 Owner。
🐱 當程式第一次呼叫 owner.getCats(),它才真的去 SQL 撈貓咪。
第 1 次查詢 (The 1 in N+1)
SELECT * FROM OWNERS WHERE ID = 1;
接著 N 次查詢 (The N in N+1)
SELECT * FROM CATS WHERE OWNER_ID = 1;
SELECT * FROM CATS WHERE OWNER_ID = 1;
SELECT * FROM CATS WHERE OWNER_ID = 1;
...
你先問Owner是誰然後接下來每叫一隻貓,都要跑去資料庫問一次:「OWNER 1 的第 n 隻貓是誰?」大量的資料庫查詢操作非常慢。
你可能要想一些 sql 的解法來處理: 直接用 JOIN 或 fetch join 把 Owner 和 Cats 一次查回來:
SELECT *
FROM OWNERS o
INNER JOIN CATS c ON o.ID = c.OWNER_ID
WHERE o.ID = 1;
這樣一查就拿到所有貓咪,省去重複查詢。
方便操作讓 developer 可以著重在 bussiness logic,而且 Hibernate跟 Spring Data JPA 已經幫我們做了一些好用的 features 跟優化。
JPA是一個 specification,當有人說他用了 JPA 是指他用了一個基於 JPA 這個specification的 technology (an implemantion)。JPA定義了 java application 跟 db 互動的 interface。Hibernate 則是一個基於 JPA specification ORM 框架的技術。
直接用 JDBC (a vanilla way to connect db in java)當然能操作 DB,但這樣的操作最底層的方式有一些 disadvantages
所以在大部分應用中,我們會用更 high level 操作 db:

使用基於 JPA 的科技會為引入一層 middle layer (context) 來幫助管理物件的操作。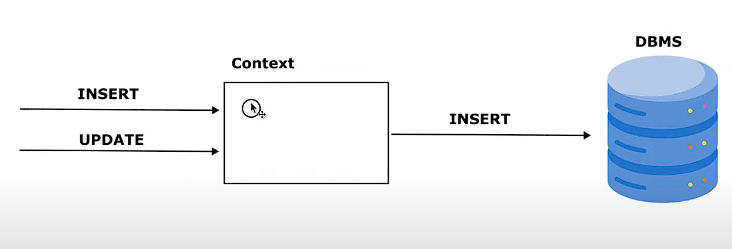
(From LAURENŢIU SPILCĂ's yt: Laur Spilca)
想像如果你的每一個操作都要直接跟 DB 互動,效率會很差。試想有一個 middle layer 它可以幫忙先 "統整" 所有物件的操作,這些變更不會立刻送到資料庫,而是先被放到這個 context 裡統一追蹤,最後在 flush 或 commit 的時候,EntityManager 會整理出一份『變更名單』(新增、修改、刪除)並一次性執行對應的 SQL。
這樣可以避免每次 setter 都馬上發 SQL 減少時即對 db 的操作,不過有時候反而會因為 Lazy Loading 或 N+1 (Navigation Problem) 造成更多查詢。
那這個中間層我們稱他為 peristence context 在 perisistnece context 管理物件的 API 類別稱 EntityManager 。 manager 負責追蹤所有被管理的 entity(也就是帶有 @Entity 的物件)。
EntityManager。(EntityManager 是 factory pattern 你你要得到這個物件必須先有 factory ,再用 factory 去製造。)
// if we use xml to define our db
EntityManagerFactory emf = Persistence.createEntityManagerFactory("my-persistence-unit");
EntityManager em = emf.createEntityMannager();
try {
em.getTransaction().begin()
Cat c = new Cat();
c.setId(1L);
c.setName("vanillasky");
em.persist(c); //add this to the context -> NOT AN INSERT QUERY, we have to think in ORM theroem
em.getTransaction().commit();// the context is mirrored to the db
} finally {
em.close();
}
Jakarta Persistence API (JPA), formerly known as Java Persistence API, is a specification that defines a standard API for ORM frameworks. It dictates how an ORM should be implemented in the Java ecosystem. --Baeldung: Learn Hibernate and JPA
剛有提到 middle layer 的出現讓我們可以 在 context 預先統計,那麼最後的「變更名單」要怎麼 map 過去? 那麼 ORM (an interface) 定義了如何幫我們把 Java 物件 ↔ SQL做轉換,而 Hibernate 則是常見的實作,遵循 JPA 並提供更多 features。藉由 jpa specification 中所定義的 ORM 幫助我們 "mapping 自動化",降低了前面介紹的 5 paradigm mismatches。
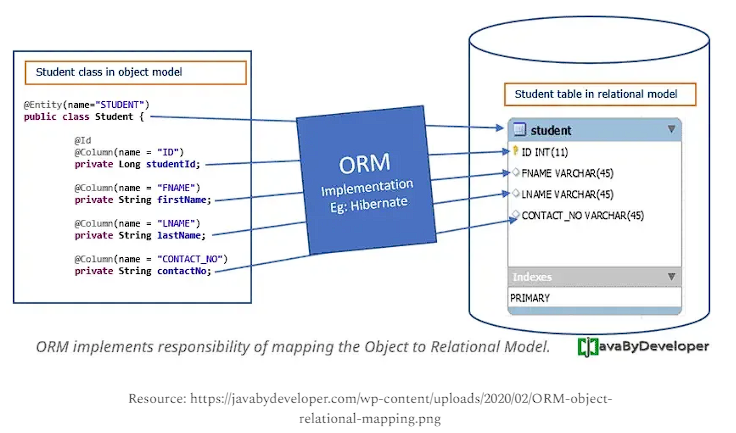
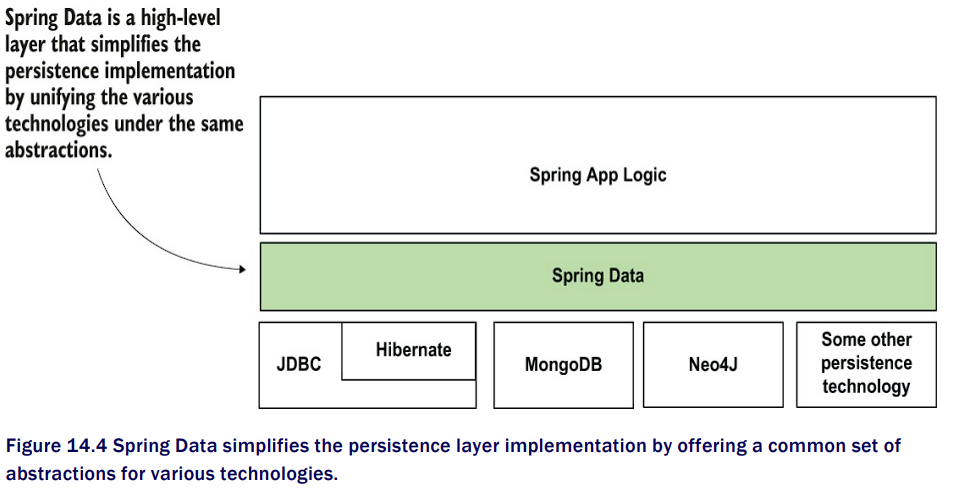
比 Hibernate 更上層,Spring Data 又再進一步:
public interface CatRepository extends JpaRepository<Cat, Long> {
List<Cat> findByName(String name);
List<Cat> findByFurColorContainingIgnoreCase(String colorKeyword);
List<Cat> findTop5ByOrderByIdDesc(); // top 5 records
List<Cat> findByOwner_Name(String ownerName);
// direct use JPQL for customizatio of join/fetch in avoidance of N+1 problem
@Query("""
select c from Cat c
join fetch c.owner o
where lower(o.name) = lower(:ownerName)
order by c.id desc
""")
List<Cat> findLatestByOwnerWithOwnerFetched(@Param("ownerName") String ownerName);
Optional<Cat> findByOwner_IdAndName(Long ownerId, String name);
}
@Query(value = "SELECT * FROM cats WHERE name = ?1", nativeQuery = true)
List<Cat> findByNameNative(String name);
但 JPQL 的好處 是它跟 Java Entity 綁定,不依賴資料庫 vendor(跨 MySQL、Postgres 都能用)。
select c from Cat c → Hibernate 幫你翻成對應 SQLselect * from cats,效能直接一樣,但你要根據你用的 db vendor 來寫可以看情境使用:
LIMIT、ILIKE)本系列文章會用到 Spring Data 下一章我們會繼續詳細學習實作以及配置 db 的部分~~
Spring Data 會在 Spring 起動時把 method name 翻成 JPQL ,你不一定要寫 @Query 但這樣很侷限。
List<Cat> findByName(String name);
會被翻成類似 JPQL:
select c from Cat c where c.name = :name
因為 method 名稱一改,query 就壞掉,多人協作時要多注意,所以我都是
@Query(JPQL 或 Native)。LAURENŢIU SPILCĂ, Spring Start Here: Learn what You Need and Learn it Well
Catalin Tudose, Java Persistence with Spring Data and Hibernate

