
上一篇提到如何抽取程式碼中的 Calculations 來重構一個複雜的函式,重構的原則是「最小化隱性輸入與輸出」,而今天要介紹的「分層設計(Stratified Design)」原則也有助於重構程式,能讓我們解決混亂的程式碼問題。
在軟體開發的日常中,我們經常會遇到一些令人頭痛的函式。想像有一個 processOrder 的函式,它從解析 HTTP 請求開始,接著查詢資料庫以驗證使用者身份,計算訂單的折扣與運費,然後更新庫存,最後還得發送一封確認電子郵件。所有這些邏輯都擠在一個巨大的函式中。這樣的程式「難以測試且不易修改」,當業務需求稍有變動,我們就必須深入理解這個錯綜複雜的函式,冒著牽一髮而動全身的風險進行修改。(不知道有沒有人覺得,很像我們平常遇到大型專案 legacy code 的頭痛感?😅)
而今天要介紹的分層設計就提供了一種方法,來解決這個普遍存在的混亂問題。其核心思想非常簡單,就是「將事物拆分開來」。這不是只有將檔案整理到不同資料夾,而是根據「意義的層次」來組織我們的程式碼,從而有效管理複雜性。
分層設計(stratified design)是一種將軟體分隔成多個層(layers)的設計方法,每一層的函式都以其層的函式定義。分層設計的概念有著悠久的歷史,由許多人共同發展而成,在 1988 年,Harold Abelson 與 Gerald Sussman 的著作「LISP: a language for stratified design」就提到了這個方法,促使此技術出現。
我們可以藉助《簡約的軟體開發思維:用 Functional Programming 重構程式 - 以 Javascript 為例》作者 Eric Normand 提出的烹飪類比來更理解分層設計:
Array、Object 和 for 迴圈。這些是構成一切的基礎,也是最不容易改變的部分 。 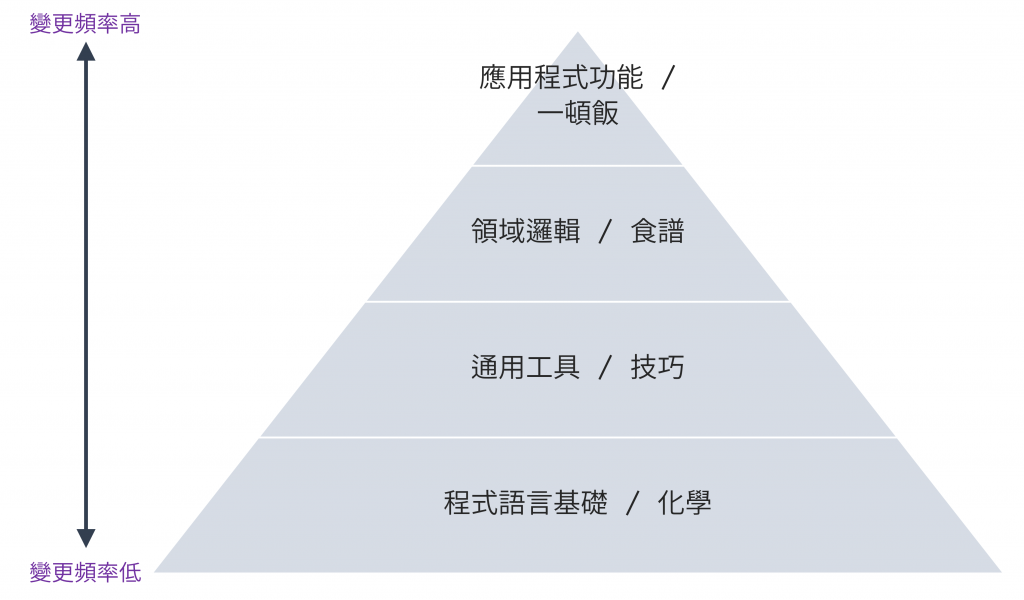
圖 1 烹飪類比程式設計中的分層設計(資料來源:自行繪製)
這個類比顯示了分層設計最核心的原則:根據變更的頻率 (rate of change) 來組織層次。位於最頂層的業務規則(如同「食譜」)會因為市場策略的變化而頻繁修改;而位於最底層的程式語言(如同「化學」)則非常穩定。
為何需要根據變更頻率來組織層次呢?因為如果我們將變更頻率不同的程式混雜在一起,它就耦合了不同的變更週期。假設有一個頻繁變動的業務規則(例如:一個限時促銷活動的折扣計算)與一個極其穩定的底層工具函式(例如:一個格式化貨幣的函式)緊密地寫在一起,那每次修改這個不穩定的業務規則時,都有可能會影響到那段本應穩定的的工具函式,讓發生錯誤的風險更高。
分層設計的根本目標,就是透過分離這些層次來解耦變更週期。我們希望能夠隨心所欲地修改「食譜」(業務邏輯),而無需擔心會破壞「化學」(核心工具)的穩定性。
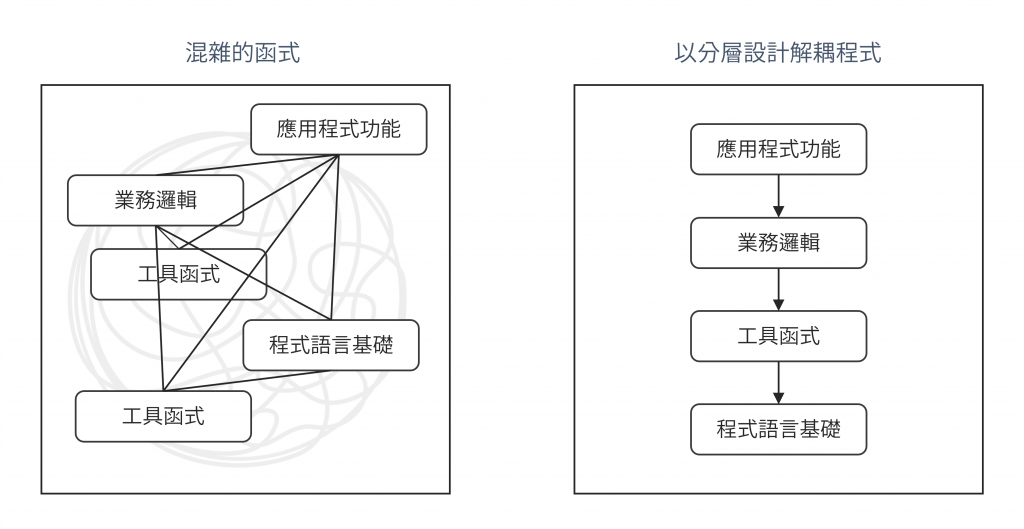
圖 2 以分層設計解耦程式的示意圖(資料來源:自行繪製)
另外小補充一下,剛好前陣子有機會接觸一點點 DevOps,分層設計的原則其實和 DevOps 文化所追求的目標不謀而合,在 DevOps 中,通常會以四大關鍵指標來評估企業的 DevOps 成熟度、導入狀況等,詳細可參考 DORA metrics: How to measure Open DevOps success
,四大關鍵指標中,有一個指標是希望能提升「部署頻率」(Deployment frequency) ,另一個指標則是希望同時降低「變更失敗率」(Change failure rate) 。而一個分層良好的設計,能將易變的、高層次的業務邏輯隔離在頂層。由於頂層程式碼的依賴性較少(只有它依賴下層,沒有下層依賴它),對其進行的修改影響範圍小,從而使得部署的風險更低、規模更小。因此,在微觀的函式層級採用分層設計,是實現宏觀的持續交付與高穩定性目標的具體技術手段。它不僅是一種抽象的「良好實踐」,更是建構一個易於安全、快速迭代系統的堅實基礎。
基本上上面已經差不多把分層設計介紹完啦 XD,接下來細部看一下我們如何達到分層設計吧~
在程式中應用分層設計時,可參考以下原則。
程式碼異味(code smell):暗示程式可能有潛在問題的特徵
接下來介紹兩種實現分層設計的方式~
這方式對應的上面的第一個原則「讓實作更直觀」。
「直白實作」的核心規則是:一個函式內部的所有程式碼,都應該處於相同的抽象層級(或稱細節層級)。這代表一個函式要馬扮演高層次的協調者角色(做什麼),要馬扮演低層次的執行者角色(怎麼做),但不應該兩者兼備。如果函式又要扮演高層次角色又要扮演低層次角色,開發者在閱讀程式碼時就會有較高的認知負擔,因為你一邊要想大流程方向他要做什麼、一邊又要跳著思考他細節上如何實作,這對我們來說,是需要一直轉換思考情境的,需花費較多心力。
一個很好的判斷標準是,當你閱讀一段程式碼時,如果能夠「忽略掉相同的細節」,那麼這些程式碼很可能就處於同一個抽象層級。
讓我們來看一個例子。假設我們要篩選出活躍使用者並發送歡迎郵件:
// 修改前:混合了不同的抽象層級
function generateWelcomeEmails(users) {
const activeUsers = [];
// 低層級細節:如何遍歷和篩選陣列
for (let i = 0; i < users.length; i++) {
// 業務規則:什麼是活躍使用者
if (users[i].active && users[i].email) {
activeUsers.push(users[i]);
}
}
// 高層級意圖:使用篩選出的使用者來產生郵件
//... 更多根據 activeUsers 產生郵件的邏輯...
console.log(`準備發送郵件給 ${activeUsers.length} 位活躍使用者。`);
return /*... 郵件內容... */;
}
在這個版本中,generateWelcomeEmails 函式既關心「如何」遍歷陣列(for 迴圈),又關心「做什麼」(產生歡迎郵件)。這就違反了直白實作的原則。我們也可以為這段程式畫出一個呼叫圖,來看一下它涉及的層級。
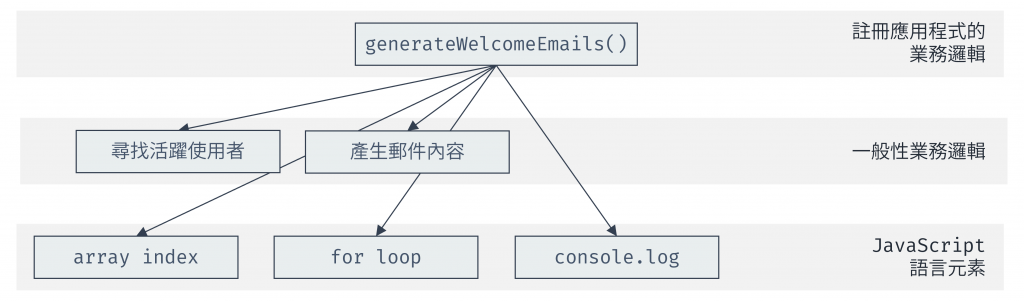
圖 3 generateWelcomeEmails 呼叫圖(資料來源:自行繪製)
在呼叫圖中,有幾個要點:
我們可以看到 generateWelcomeEmails 在呼叫圖中呼叫了不同層級的程式,違反直白實作原則,因此我們要提取低層級的迴圈邏輯,來應用「直白實作」模式:
// 修改後:應用直白實作模式
// 低層級函式:專注於「如何」篩選使用者
function selectActiveUsers(allUsers) {
const result =;
for (let i = 0; i < allUsers.length; i++) {
const user = allUsers[i];
if (user.active && user.email) {
result.push(user);
}
}
return result;
}
// 高層級函式:專注於「做什麼」的協調工作
function generateWelcomeEmails(users) {
// 呼叫較低層級的抽象來完成任務
const activeUsers = selectActiveUsers(users);
// 保持在高層級的意圖上
console.log(`準備發送郵件給 ${activeUsers.length} 位活躍使用者。`);
return /*... 郵件內容... */;
}
這個重構的威力在於,它迫使我們為被提取出來的低層級概念命名。我們從一個匿名的、命令式的 for 迴圈,轉變為一個具名的、宣告式的函式 selectActiveUsers。這個命名的過程,本身就是在創造一個新的、更小的意義層次,是分層設計的基礎操作之一。
在以下新的呼叫圖中,可看出 generateWelcomeEmails 不需要在乎 for 迴圈的實作,只要呼叫 selectActiveUsers 即可。
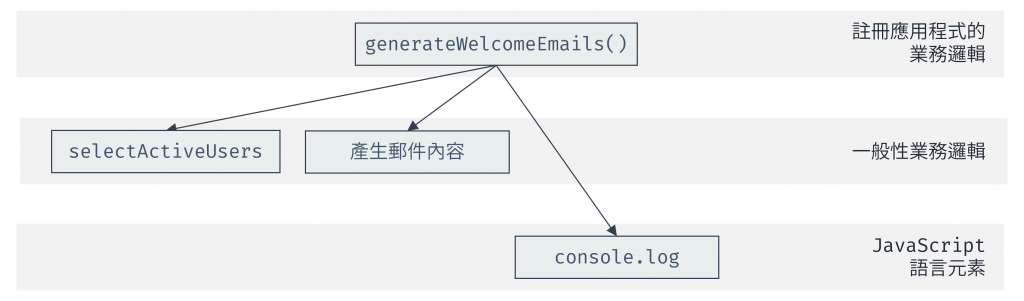
圖 4 generateWelcomeEmails 重構後的呼叫圖(資料來源:自行繪製)
這方式對應的上面的第二個原則「以抽象屏障輔助實作」。
「抽象屏障」是一組函式,它們共同為某個資料結構或子系統提供一個統一的、簡化的互動介面。這個屏障的好處在於,它透過隱藏實作細節,讓我們能夠更容易地思考正在解決的問題。
舉例來說,第三方套件提供的 API 就算是一種抽象屏障,以前端應用為例,當我們呼叫 React 的 useState 回傳的 setState 函式時,我們不用去管 setState 內部如何實作的,只要知道呼叫 setState 可以更新狀態促使畫面更新即可,因為更新狀態的實作細節都由 React 幫我們處理了,我們可以忽略詳細的實作細節。(當然,如果是為了更瞭解 React 運作機制,還是可以去深入看看 setState 如何實作,只是單純以使用方的角度來看,我們可以不用知道實作細節)
現在假設有個購物車系統,他的資料結構可能很複雜:
// 修改前:直接操作複雜的資料結構,導致高度耦合
function getCartTotal(cart) {
let total = 0;
// 程式碼直接依賴於 cart.items[...].product.price_cents 的結構
for (let i = 0; i < cart.items.length; i++) {
const item = cart.items[i];
total += item.product.price_cents * item.quantity;
}
return total / 100; // 還要處理單位換算
}
const myCart = {
id: 'cart-123',
user_id: 'user-abc',
items:
};
console.log(`購物車總價: $${getCartTotal(myCart)}`);
這段程式碼與 cart 物件的內部結構緊密耦合。如果未來 price_cents 欄位改名為 price,或者 items 陣列的結構改變,所有像 getCartTotal 這樣直接存取資料的函式都需要修改。
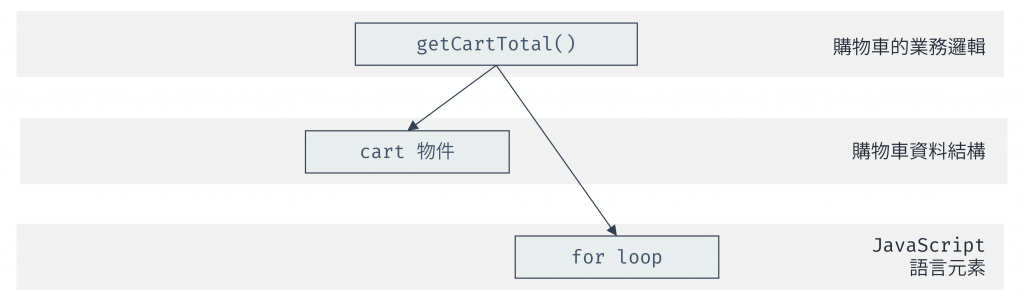
圖 5 getCartTotal 呼叫圖(資料來源:自行繪製)
現在我們來為 cart 物件建立一個抽象屏障看看:
// 修改後:使用抽象屏障來解耦
// --- 購物車的抽象屏障 ---
const getCartItems = (cart) => cart.items;
const getItemPrice = (item) => item.product.price_cents / 100;
const getItemQuantity = (item) => item.quantity;
// --- 屏障結束 ---
// 高層級邏輯現在變得非常清晰,且與資料結構解耦
function getCartTotal(cart) {
const items = getCartItems(cart);
let total = 0;
for (let i = 0; i < items.length; i++) {
const item = items[i];
total += getItemPrice(item) * getItemQuantity(item);
}
return total;
}
// myCart 物件結構同上
console.log(`購物車總價: $${getCartTotal(myCart)}`);
透過這個屏障,getCartTotal 不再關心價格是以「分」還是「元」儲存,也不再關心商品項目在購物車物件中的具體路徑。未來如果資料結構變更,我們只需要修改屏障內的函式(例如 getItemPrice),而所有使用這個屏障的高層級邏輯都不需改動。
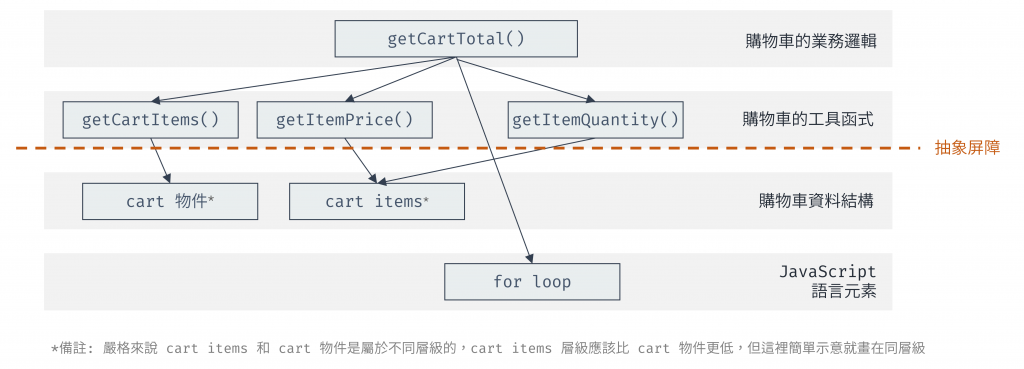
圖 6 建立抽象屏障後,getCartTotal 的呼叫圖(資料來源:自行繪製)
從上面呼叫圖可以看到,getCartTotal 不會直接接觸/呼叫 cart 資料,而是透過一層抽象屏障來呼叫,因此 getCartTotal 不需要知道 cart 內部資料結構實作,不過 getCartTotal 目前還是會直接接觸底層程式的 for 迴圈實作,for 迴圈的抽象會在之後的高階函式介紹,這裡先略過。
直白實作和抽象屏障這兩種方式可以被看作是在兩個基本維度上建立層次。
直白實作處理的是單一操作內部的控制流程,透過將函式呼叫堆疊起來,建立了一個垂直的抽象層次(例如 generateWelcomeEmails 呼叫 selectActiveUsers)。
而抽象屏障則圍繞一個資料或子系統,定義了一個水平的邊界。所有與「購物車」概念相關的互動,都應該通過這個水平邊界。
一個設計良好的分層系統,可同時應用這兩種方式來建構:使用抽象屏障來定義層次的邊界(「是什麼」),並使用直白實作來確保層次內部的程式碼是清晰且一致的(「怎麼做」)。
我去年鐵人賽有介紹過設計模式,而其實分層設計的概念和某些經典模式的概念十分相似,直白實作與 Kent Beck 在《Implementation Patterns》中提到的「組合方法 (Composed Method)」模式有異曲同工之妙,抽象屏障則與「外觀模式 (Facade Pattern)」和「轉接器模式 (Adapter Pattern)」等共享著簡化介面、隱藏實作的目標。
透過呼叫圖,我們除了看出函式呼叫的層級外,還可以看出三項非功能性需求(nonfunctional requirements, NFRs):
我們可以從函式在呼叫圖中的「位置」決定 NFRs 的真正條件。
補充
- 軟體的功能性需求(functional requirements): 程式在功能上須達到的標準
> e.g. 稅金函式必須正確計算課稅金額- 軟體的非功能性需求(nonfunctional requirements, NFRs)
- 可測試性(testability)
- 可重複使用性(reusability)
- 可維護性(maintainability)
(三者經常合稱「ilities」)
可重用性在底層最高,最底層的程式碼,包含了通用的、與領域無關的邏輯,因此可以在專案的各個角落被反覆使用。Array.map 函式可以在訂單記錄、部落格貼文列表和使用者好友清單中都被用到。
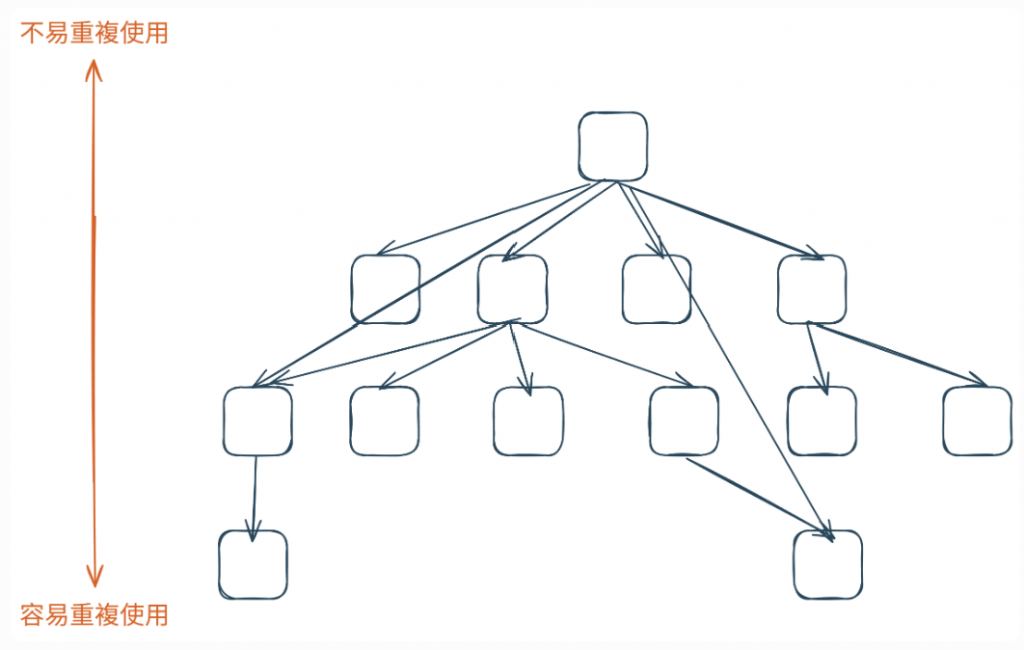
圖 7 越底層的程式,可重用性越高(資料來源:自行繪製)
可維護性(易於變更)在頂層最高,最頂層的程式碼是高度客製化的,很少有其他程式碼會依賴它們。這讓它們非常容易修改,甚至可以整個丟棄,而不會對系統的其他部分產生連鎖反應。當一個行銷活動結束時,對應的頂層邏輯可以被安全地移除。
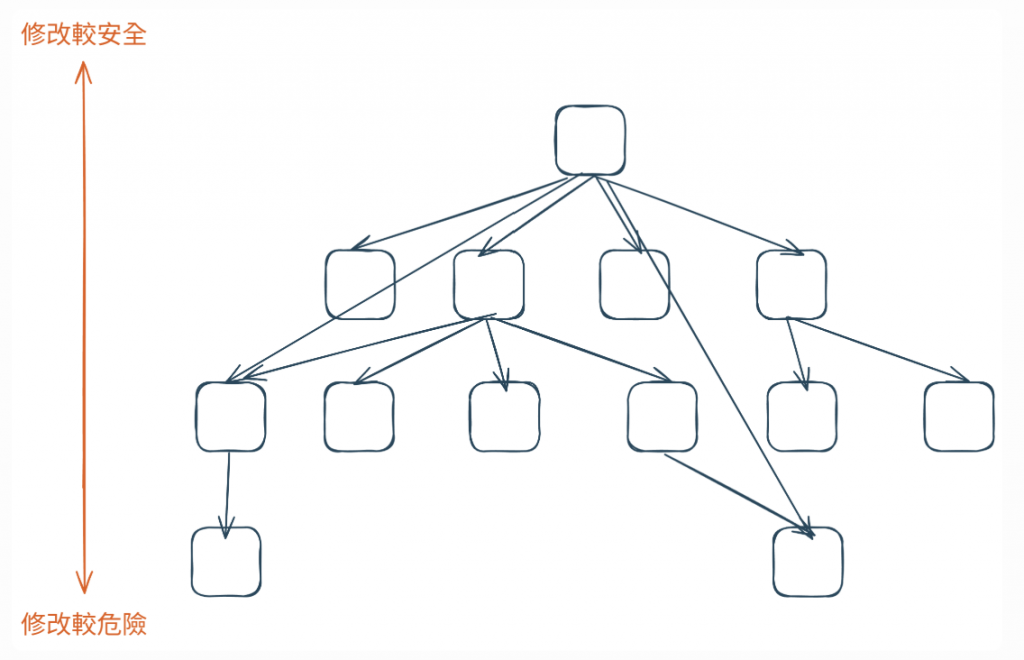
圖 8 越高層的程式,越容易修改(資料來源:自行繪製)
實務上應該把不隨時間改變的程式放在下層,把需變更頻繁的函式放在上層,避免用可能改變的函式定義其他函式,就可提升可維護性。
可測試性在底層最關鍵,位於底層、被高度重用的工具函式一旦出現錯誤,其影響將是災難性的,會波及所有依賴它的上層功能。因此,確保底層程式碼的極度健壯至關重要。
因為底層程式碼非常穩定,為它們撰寫的測試案例也同樣穩定,寫一次底層程式的測試得到的效益會比高層函式測試的效益更高。因此,測試底層程式碼的價值最高,因為系統中的其他一切都建立在它們的正確性之上。
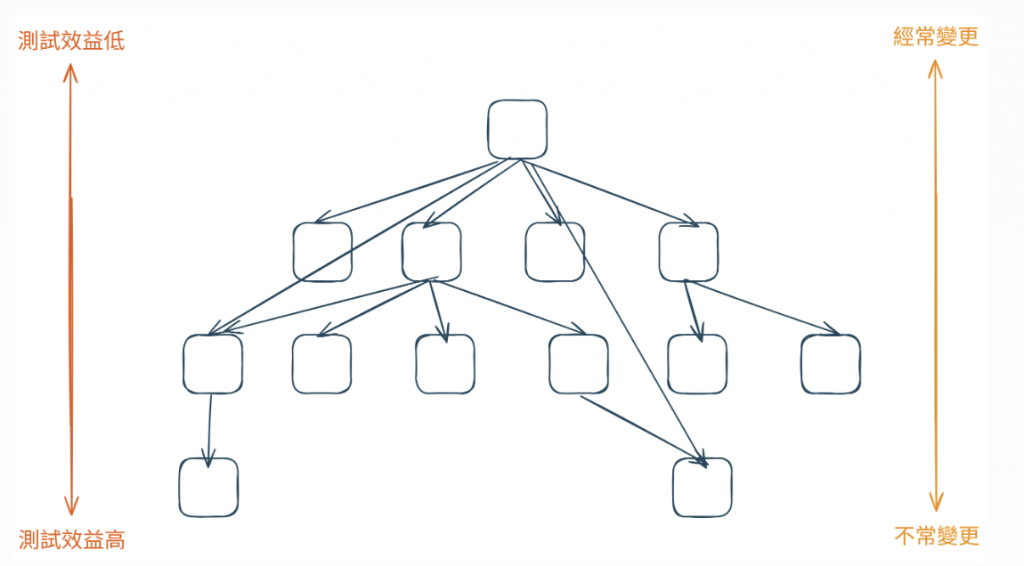
圖 9 越底層的程式,測試的效益越高(資料來源:自行繪製)
實務上來說,撰寫底層函式的測試效益最高,因此推薦從底層的 util 工具函式開始撰寫測試。
因此對於不同層級的程式碼,我們要用不同的角度看待:
今天了解了什麼是分層設計,雖然分層設計更像是一種軟體設計的技巧,不一定和 FP 有直接相關,但如果我們能以分層設計的觀點去拆分程式,那之後在學習 FP 工具如何組裝不同函式時,也會比較知道如何拆分邏輯、如何將相同層級的函式放在一起吧~
自從學了分層設計的概念後,現在覺得自己寫的程式碼很雜亂時,都會跟 AI 說:「請依照分層設計的原則幫我重構這段程式」,覺得效果都蠻不錯的 😂
以下也簡單總結今天探討的分層設計概念:
分層設計並非一個需要嚴格遵守的死板框架,而更像是一個看待和組織程式碼的視角,它的目標是管理開發者的認知負擔,促進人類的理解。
軟體被閱讀的次數遠遠超過被撰寫的次數。一個易於理解和推理的設計,其內在就更易於維護且更不容易產生錯誤。在上面的分析過程中,「更容易地思考」、「降低認知負擔」和「意義的層次」等詞彙反覆出現,都指向了這個核心。分層設計承認我們人類工作記憶的極限,並提供了一套系統性的方法,讓我們可以一次只專注於一個層次,從而有能力去構建和理解那些遠超我們心智容量的複雜系統。
最後的最後,想補充的是,分層設計並不是說分的層級越多越好,不是說程式碼層級拆得越細、越乾淨就是好維護的程式碼,須強調前面提的分層設計原則 4:「分層只要舒適即可」,當你覺得程式碼髒髒亂亂的,再來看看是不是要加入更多分層,而不是一直瘋狂加層級,那反而會造成開發的負擔! 一切適度即可,分層設計沒有標準答案。

