在回顧了 GPT 模型一路以來的演進與突破後,我們已經了解了這些模型為何能在語言理解與推理能力上不斷提升。然而,再先進的 GPT-5 或 GPT-4o,本質上仍然建立在一個相同的基礎——它們需要先把人類語言「數位化」成機器能理解的形式。
換句話說,要讓 AI 讀懂我們的文字,第一步就是把語言拆解與編碼。這正是 Tokenization(分詞) 與 Embedding(嵌入) 的角色所在。
Tokenization 和 Embedding 是 LLMs 處理和理解語言的基礎步驟,它們將人類的非結構化文本轉換為機器可計算的結構化數字形式。
Tokenization 是指將原始文本轉換為一系列 tokens(標記) 的過程。這些 tokens 可以是單個字符、單詞的一部分,甚至是整個單詞或句子片段。這是任何實際建模或資料處理前的 第一步。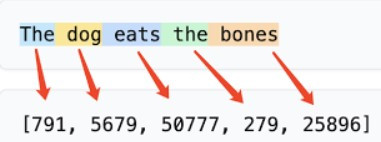
The dog eats the bones 經過分詞器轉換後,每個詞會對應到唯一的 token ID。
為了平衡詞彙表大小、處理未知詞(OOV)並保留語義信息,現代 LLMs 通常採用子詞粒度 Tokenization,包括以下幾種核心算法:
| 算法名稱 | 核心思路與原理 | 應用範例 |
|---|---|---|
| Byte-Pair Encoding (BPE) | 透過迭代合併文本中最常見的連續字符對或字節對,來創建新的子詞單元。這個過程重複進行,直到達到預設的詞彙大小。 | GPT-2、RoBERTa、XLM 等模型是基於 BPE。 |
| WordPiece | 類似 BPE,但它選擇合併的字符對是基於合併後能最大程度地提高訓練數據的 可能性(likelihood),而不僅僅是頻率。 | BERT 和 Google 的神經機器翻譯系統。 |
| SentencePiece | 是一種無監督的文本處理工具,它直接在原始文本上操作,將空格也視為普通符號。這對於中文等沒有明確空格的語言尤其有用,能確保分詞和合詞(detokenization)過程可逆。 | SentencePiece 支持 BPE 和 Unigram Language Model 算法。 |
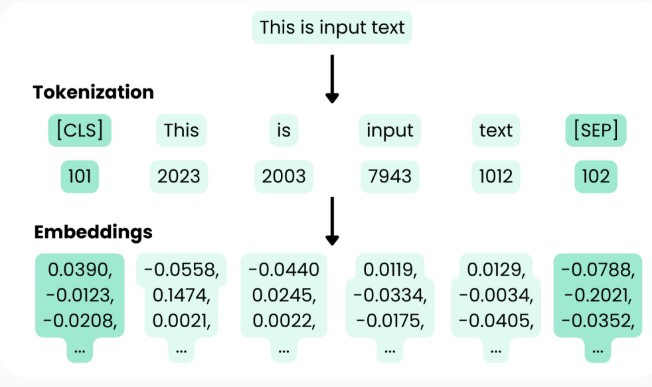
向量嵌入(Vector Embedding),或簡稱嵌入,是主題、單字、圖片或其他任何數據的數字表示(向量)。它是一種將離散符號(如詞、句子)轉換成連續向量的方式,讓這些符號可以進入神經網路進行學習與推理。
語意空間(Semantic Space) 是 Embedding 的核心原理。在這個空間中,我們可以透過向量之間的幾何關係來觀察語言邏輯。
例如,Word2Vec 的經典關係證明了語意可以被計算:
$$ \text{vector("king")} - \text{vector("man")} + \text{vector("woman")} \approx \text{vector("queen")} $$
為了衡量向量之間的相似度,我們依賴數學方法,稱為相似度度量(Similarity Metrics),常見的方法有:
詞向量的類型:
| 類型 | 定義與原理 | 解決的問題 |
|---|---|---|
| 靜態詞向量 | 每個詞對應一個固定向量,無論上下文如何都不變,代表詞的平均語意。 | 存在語義歧義問題(如 "bank" 在不同語境下的意思不同,但向量唯一)。 |
| 動態詞向量 | 詞的向量會依據不同上下文動態變化。模型利用 Transformer 結構全域編碼句子脈絡,辨識詞義。 | 能有效解決多義詞問題,提升語義精準度。已成為現代語言模型(如 BERT、GPT)的主流。 |
簡單來說,Tokenization 是前處理步驟,將非結構化文本轉換為機器可以處理的結構化形式;而 Embedding 是表示步驟,將結構化單元轉換為可計算的語義。
Tokenization: 將原始文本分解成一系列 Tokens (e.g., "學校", "小明", "今天")。
Embedding: 一旦文本被代幣化,每個 Token 都需要被轉換為一個向量(Embedding),這個向量攜帶了該 Token 的語義信息。
這些向量隨後被餵給像 GPT 這樣的神經網路模型進行學習與推理。因此,Tokenization 決定了模型看到的基本單元,而 Embedding 則決定了模型對這些單元含義的理解深度,是大型語言模型進行所有下游應用(如相似度搜尋、分類、翻譯等)的數學基礎。向量嵌入的強大功能也進一步被向量資料庫所利用,用於對圖片、文字等大量的非結構化和半結構化數據進行索引和搜尋。


 iThome鐵人賽
iThome鐵人賽