大家好,歡迎來到數據新手村的第八天!經過前七天「基礎建設週」的努力,我們的開發工作站、數據金庫與版本控制時光機都已備妥。從今天開始,將正式告別安裝與設定,潛入數據的世界,開始撰寫真正的程式碼。
今天,我們將認識未來 20 多天要朝夕相處的兩位主角:
在數據爆炸的時代,數據本身沒有價值,經過處理與分析後才能轉化為洞見。可以想像,如果只有冰冷的數據,永遠無法回答「哪個城市的訂單最多?」「哪款產品最受歡迎?」這類商業問題。
數據處理就是將原始數據轉變為有意義資訊的關鍵步驟。一個完整的數據分析流程通常包含以下環節:
而 Python 及其強大的函式庫,正是執行這整個流程的最佳工具鏈:
| 功能特色 | Excel | Python (Pandas) |
|---|---|---|
| 數據處理量 | 1 萬行以內 (有限) | 100 萬行以內 (高效) |
| 自動化 | 主要手動操作 | 代碼一鍵運行 (可高度自動化) |
| 學習難度 | 簡單易上手 | 需基礎程式知識 |
在開始動手寫程式之前,必須先了解手上的「彈藥」。Olist 數據集是一份來自真實世界的巴西電商平台公開數據,它並非單一的 CSV 檔案,而是由 9 個獨立的檔案組成,共同描繪出一個電商帝國的運作縮影。
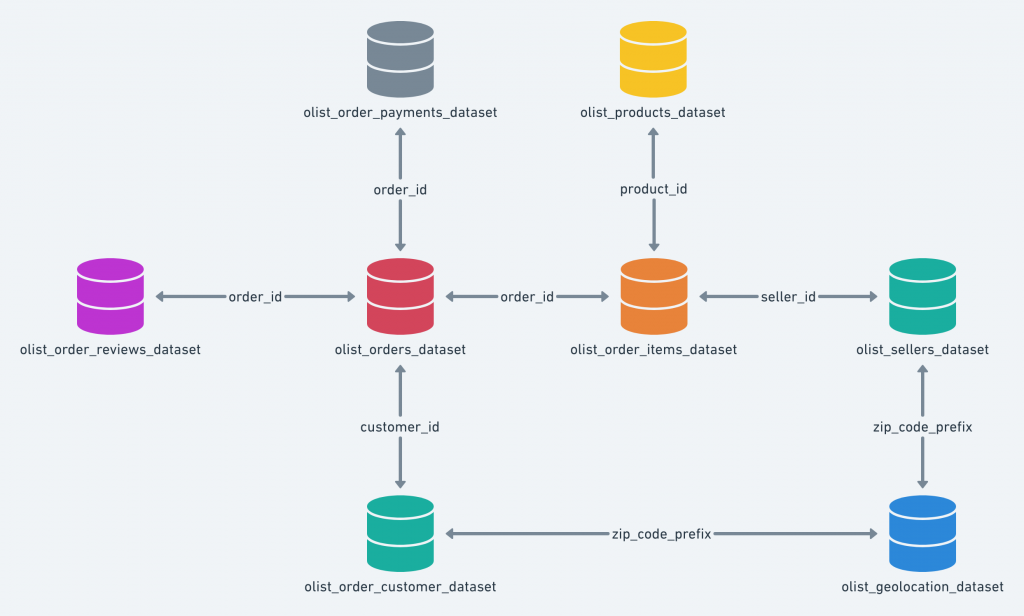
圖 1:Olist 資料庫中各表格之間的關聯模型示意圖
這些檔案分別記錄了電商業務的不同面向:
olist_orders_dataset.csv:訂單主表,核心數據。olist_order_items_dataset.csv:訂單商品表,訂單內容細節。olist_order_payments_dataset.csv:訂單支付表,付款方式與金額。olist_customers_dataset.csv:客戶資料表,買家基本資訊與地理位置。olist_products_dataset.csv:商品資料表,商品分類與物理屬性。olist_sellers_dataset.csv:賣家資料表,賣家地理位置。olist_order_reviews_dataset.csv:訂單評論表,客戶滿意度回饋。olist_geolocation_dataset.csv:地理位置表,郵遞區號經緯度。product_category_name_translation.csv:產品類別翻譯表,葡萄牙文分類轉英文。在接下來的旅程中,將不斷地在這些表格之間穿梭,將它們合併、清理、分析,最終挖掘出有價值的商業洞見。
要處理如此龐大且複雜的數據,我們需要一把鋒利的武器。Python 內建的 list (列表) 雖然靈活,但在進行大規模數值計算時,它的效能並不足以應付數據分析的需求。
這就是 NumPy 登場的原因。NumPy (Numerical Python) 是 Python 中科學計算的基礎套件,它的核心是 ndarray (N-dimensional array) 這個強大的多維陣列物件。
您可以把 NumPy 想像成是 Python 數據科學的**「發動機」**。它是一個 Python 庫,提供多維陣列物件以及用於對陣列進行快速操作的各種方法,包括數學、邏輯、形狀操作、排序、隨機模擬等。
NumPy ndarray 的關鍵優勢:
for 迴圈,程式碼更簡潔、可讀性更高。理論說了這麼多,不如親自動手。打開 PyCharm,在您的 Numpy_Basics/course_notes 資料夾中,開啟或建立一個新的 Jupyter Notebook (.ipynb) 檔案,寫下第一行 NumPy 程式碼。
如果 PyCharm 專案環境中還沒有安裝 NumPy 和 Pandas,請先在 PyCharm 下方的「終端機 (Terminal)」中輸入以下指令:
pip install numpy pandas

