大家好,歡迎來到數據新手村的第二十九天!昨天,我們完成了第一個端到端的分析專案,成功計算出了 Olist 平台的「月銷售額」並用圖表呈現。
但這個 monthly_sales DataFrame 目前只是一個暫存於記憶體中的變數,一旦我們關閉 PyCharm,所有辛苦計算的成果都會消失。
我們當然可以將它存成一個新的 CSV 檔案,但更專業、更具擴展性的作法,是將這個聚合後的、高價值的分析結果,存入我們在 Day 05 建立的 MySQL「數據金庫」中。
今天,我們就要來打通 Python 與 MySQL 之間的「任督二脈」,完成從數據分析 (Python) -> 數據儲存 (MySQL) -> 數據驗證 (SQL) 的完整閉環。
就像電腦需要驅動程式才能跟印表機溝通一樣,Python (Pandas) 也需要一個「驅動程式」或「連接器 (Connector)」才能與 MySQL 資料庫對話。
Pandas 在底層是透過一個名為 SQLAlchemy 的函式庫來操作資料庫的,而 SQLAlchemy 又需要一個針對特定資料庫的連接器。對於 MySQL,最常用的就是 mysql-connector-python。
pip install SQLAlchemy
pip install mysql-connector-python
安裝好驅動程式後,我們就可以開始建立連線,並將 DataFrame 寫入資料庫了。
步驟一:建立資料庫引擎 (Engine)
我們需要先建立一個「資料庫引擎」,它包含了連線到 MySQL 所需的所有資訊。
import pandas as pd
from sqlalchemy import create_engine
# --- 準備 Day 28 的分析結果 ---
# (此處省略數據準備過程,直接使用聚合後的數據)
monthly_sales_data = {
'purchase_month': range(1, 13),
'payment_value': [27150, 26917, 34260, 39220, 45148, 41604,
48074, 52438, 30225, 34812, 47714, 23999] # 簡化範例數據
}
monthly_sales_df = pd.DataFrame(monthly_sales_data)
# --- 步驟 1: 建立資料庫連線字串 ---
# 格式: 'mysql+mysqlconnector://使用者名稱:密碼@主機:埠號/資料庫名稱'
# ⚠️ 請務必將 YOUR_PASSWORD 換成您 Day 05 設定的 root 密碼!
db_connection_str = 'mysql+mysqlconnector://root:YOUR_PASSWORD@localhost:3306/olist_db'
# --- 步驟 2: 建立資料庫引擎 ---
db_engine = create_engine(db_connection_str)
print("資料庫引擎建立成功!")
輸出結果:
資料庫引擎建立成功!
有了引擎之後,寫入資料就只需要一行神奇的程式碼:df.to_sql()。
# --- 步驟 3: 使用 .to_sql() 將 DataFrame 寫入資料庫 ---
monthly_sales_df.to_sql(
name='monthly_sales_summary', # 在 MySQL 中要建立的新資料表名稱
con=db_engine, # 使用我們剛建立的連線引擎
if_exists='replace', # 如果資料表已存在,就先刪除再重建
index=False # 不要將 Pandas 的 index (0, 1, 2...) 寫入資料庫
)
print("數據已成功寫入 MySQL 資料庫中的 'monthly_sales_summary' 資料表!")
輸出結果:
數據已成功寫入 MySQL 資料庫中的 'monthly_sales_summary' 資料表!
程式碼執行成功了,但數據真的進到我們的「金庫」了嗎?眼見為憑!
打開我們在 Day 06 安裝的 DBeaver。
在左側的「資料庫導覽器」中,找到 olist_db 資料庫。
對著 olist_db 底下的「資料表 (Tables)」按右鍵,選擇「重新整理 (Refresh)」。
您會驚喜地發現,清單中出現了一張我們剛剛用 Python 建立的新資料表,名為 monthly_sales_summary!
對著這張新資料表按右鍵,選擇「檢視資料 (View Data)」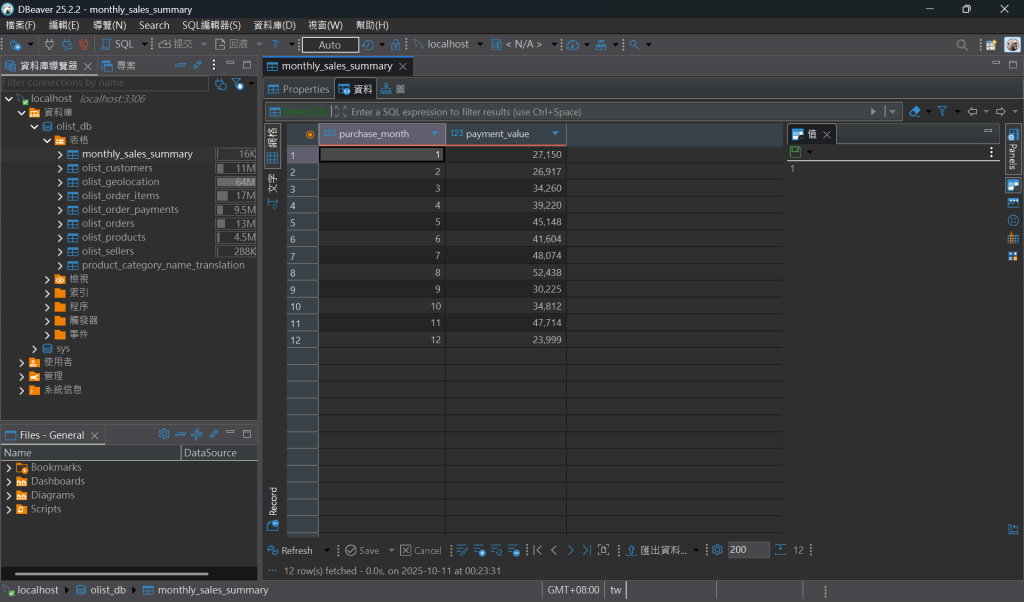
USE olist_db; -- 先告訴伺服器我們要進入 olist_db 這個部門
SELECT * FROM monthly_sales_summary ORDER BY purchase_month;
輸出結果: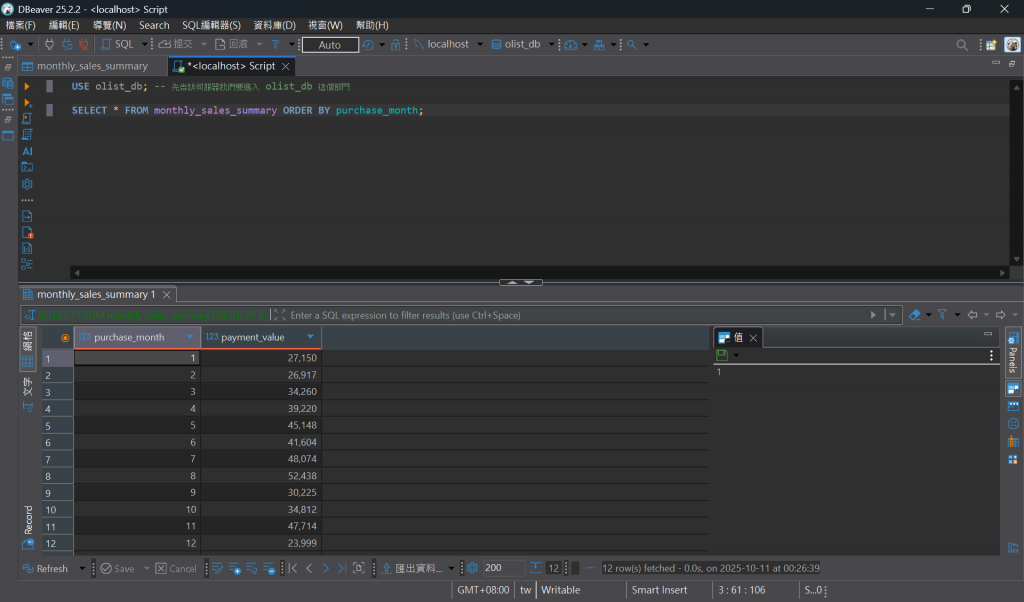
看到查詢結果了嗎?這證明我們已經成功打通了從 Python 分析到 SQL 儲存的「任督二脈」!
今天,我們完成了數據工作流的最後一塊拼圖。我們學會了如何:
我們的 30 天數據新手村之旅即將抵達終點。我們從零開始,安裝了所有工具,學會了 NumPy, Pandas, Matplotlib,甚至打通了 Python 與 SQL 的橋樑。
明天,也是本系列的最後一天,Day 30,我們將一起回顧這趟精彩的旅程,做一次完整的「挑戰總結與未來展望」,為我們的冒險畫上一個完美的句點。

