大家好,歡迎來到數據新手村的第二十七天!昨天,我們學會了使用直方圖和箱線圖,來分析單一變數(例如運送天數、訂單金額)的內部樣貌。
但數據分析的真正樂趣,在於挖掘不同變數之間的隱藏關聯。例如:
price) 和運費 (freight_value) 之間有關聯嗎?是不是越貴的商品,運費也越高?review_score) 和實際運送天數 (delivery_days) 有關嗎?是不是運送越久,評分越低?要回答這類問題,需要一個能同時呈現兩個數值變數的圖表。這就是散點圖 (Scatter Plot) !
為了能同時分析商品、訂單、支付、評論等資訊,我們需要先將多張 Olist 資料表合併成一張大寬表。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns # 首次引入 Seaborn
# 解決 Matplotlib 中文顯示問題
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei']
plt.rcParams['axes.unicode_minus'] = False
# --- 準備數據 ---
# 讀取多張資料表
orders_df = pd.read_csv('../../data/olist_datasets/olist_orders_dataset.csv')
items_df = pd.read_csv('../../data/olist_datasets/olist_order_items_dataset.csv')
payments_df = pd.read_csv('../../data/olist_datasets/olist_order_payments_dataset.csv')
reviews_df = pd.read_csv('../../data/olist_datasets/olist_order_reviews_dataset.csv')
# 進行多次合併
df = pd.merge(orders_df, items_df, on='order_id', how='left')
df = pd.merge(df, payments_df, on='order_id', how='left')
df = pd.merge(df, reviews_df, on='order_id', how='left')
# 轉換時間欄位並計算運送天數
time_cols = ['order_purchase_timestamp', 'order_delivered_customer_date']
for col in time_cols:
df[col] = pd.to_datetime(df[col], errors='coerce') # errors='coerce' 會將無法轉換的變成 NaT
df['delivery_days'] = (df['order_delivered_customer_date'] - df['order_purchase_timestamp']).dt.days
# 清理掉分析需要的欄位中的缺失值
df_cleaned = df.dropna(subset=['price', 'freight_value', 'delivery_days', 'review_score'])
散點圖的原理很簡單:它將兩個變數分別作為 X 軸和 Y 軸,數據中的每一筆紀錄,就在這個二維空間中標示為一個點。透過觀察點的分佈模式,我們就能看出兩個變數的關聯性。
商業問題: 商品的價格和運費之間,是否存在關聯?
# 為了讓圖表更清晰,我們先從中隨機抽樣 2000 筆資料來繪圖
df_sample = df_cleaned.sample(2000, random_state=42)
plt.figure(figsize=(12, 7))
# 繪製散點圖,x 軸是價格,y 軸是運費
# alpha=0.5 設定了點的透明度,方便觀察點的密集程度
plt.scatter(df_sample['price'], df_sample['freight_value'], alpha=0.5)
plt.title('Olist 商品價格 vs 運費散點圖', fontsize=16)
plt.xlabel('商品價格 (Price)', fontsize=12)
plt.ylabel('運費 (Freight Value)', fontsize=12)
plt.grid(True)
plt.show()
輸出結果: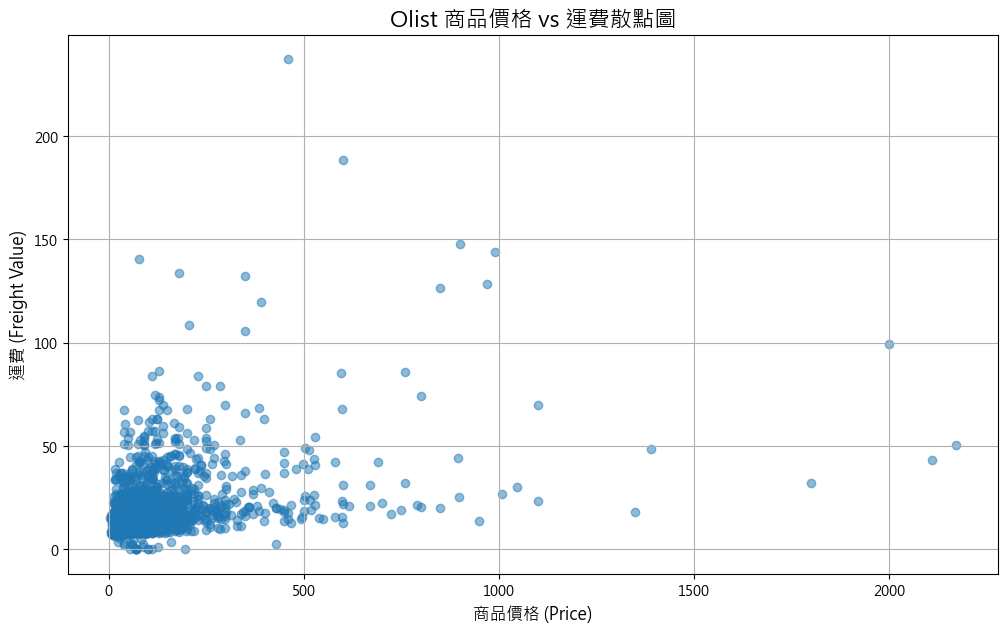
從圖中解讀:
每個點代表一個訂單商品。我們可以看出,大部分的點都集中在左下角(低價格、低運費),並且隱約可以看到一個從左下到右上的正向趨勢,這符合我們的直覺:價格越高的商品,通常體積或重量也越大,運費自然也越高。
Seaborn 是一個基於 Matplotlib 的、更高級的視覺化函式庫。它專注於統計圖表的繪製,能用更簡潔的程式碼,畫出更美觀、資訊量更豐富的圖表。
商業問題: 客戶評分和運送天數之間,到底有沒有負相關?運送越久,評分真的越低嗎?
要回答這個問題,我們不僅需要散點圖,更需要一條「趨勢線」來輔助判斷。如果用 Matplotlib 手動計算並繪製趨勢線會很複雜,但用 Seaborn 只需要一行指令!
# 同樣使用抽樣數據
df_sample_for_score = df_cleaned.sample(2000, random_state=42)
# 篩選掉不合理的運送天數,讓圖表聚焦
df_sample_for_score = df_sample_for_score[df_sample_for_score['delivery_days'] < 60]
plt.figure(figsize=(12, 7))
# 使用 Seaborn 繪製帶有迴歸線的散點圖 (Regression Plot)
sns.regplot(x='delivery_days', y='review_score', data=df_sample_for_score,
scatter_kws={'alpha': 0.3}, line_kws={'color': 'red'})
plt.title('Olist 訂單運送天數 vs 客戶評分', fontsize=16)
plt.xlabel('運送天數 (天)', fontsize=12)
plt.ylabel('客戶評分 (1-5分)', fontsize=12)
plt.yticks([1, 2, 3, 4, 5]) # 讓 y 軸刻度更清晰
plt.show()
輸出結果: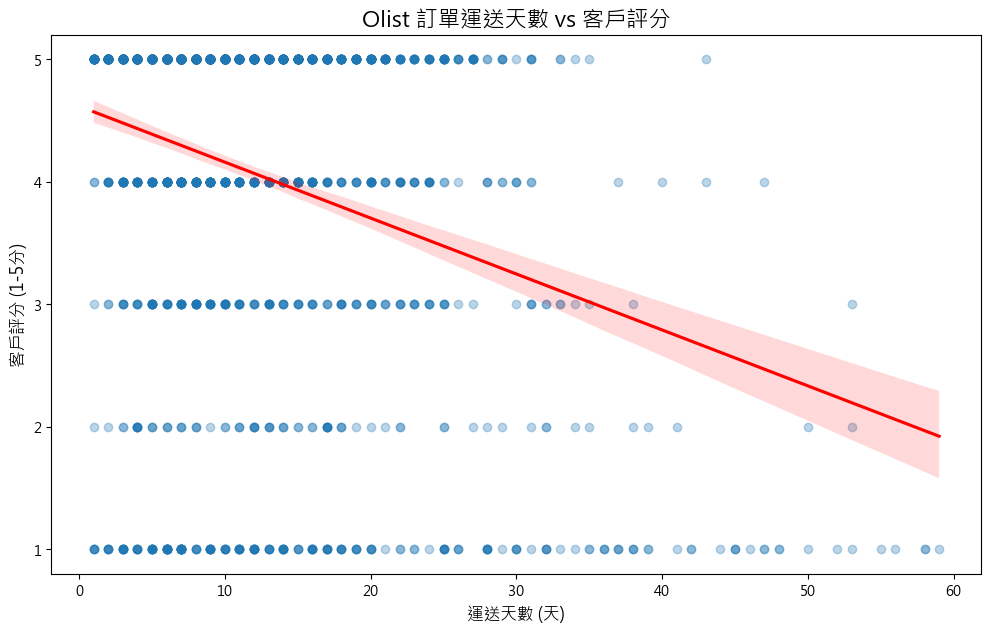
從圖中解讀:
看到那條紅色的趨勢線了嗎?sns.regplot() 自動幫我們計算並畫出了最能擬合這些數據點的線性趨勢。它清楚地顯示了一個向下傾斜的趨勢。這在統計上證實了我們的假設:運送天數越長,客戶給出的評分整體上確實有越低的傾向。這就是 Seaborn 帶給我們的強大洞見!
今天我們學會了使用散點圖來探索兩個數值變數之間的關係。我們從 Matplotlib 的基礎出發,並初次體驗了 Seaborn 的強大與優雅,它能用一行程式碼就為我們加上趨勢線,提供更深度的洞察。
我們已經掌握了數據分析與視覺化的核心武器。從明天開始,我們將進入專案實戰階段!Day 28,我們將整合過去幾週所學的所有技能,完整地分析一個商業主題:Olist 的整體銷售趨勢,並將我們的發現製作成一份小型的分析報告。

