大家好,歡迎來到數據新手村的第二十六天!昨天我們畫出了第一張折線圖和長條圖,成功將數據的趨勢與類別比較,直觀地呈現了出來。
但數據分析不僅僅是看平均值或總和。如果我告訴您,Olist 訂單的平均運送時間是 12 天,這能代表所有情況嗎?會不會有大量的訂單其實 5 天就送達,但有少數訂單花了 100 天,從而拉高了平均值?
要回答這類問題,我們必須探索數據的**「分佈 (Distribution)」**。今天,我們將學習兩種最重要的分佈視覺化工具:直方圖 (Histogram)與箱線圖 (Box Plot)。
我們將沿用 Day 24 建立的、包含「運送天數 (delivery_days)」的 DataFrame。為了讓本篇筆記可以獨立執行,我們重新準備一次數據。
import pandas as pd
import matplotlib.pyplot as plt
# 解決 Matplotlib 中文顯示問題
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei']
plt.rcParams['axes.unicode_minus'] = False
# 讀取與合併資料表
orders_df = pd.read_csv('../../data/olist_datasets/olist_orders_dataset.csv')
payments_df = pd.read_csv('../../data/olist_datasets/olist_order_payments_dataset.csv')
df = pd.merge(orders_df, payments_df, on='order_id', how='left')
# 轉換時間欄位
time_columns = ['order_purchase_timestamp', 'order_delivered_customer_date']
for col in time_columns:
df[col] = pd.to_datetime(df[col])
# 計算運送天數
df['delivery_days'] = (df['order_delivered_customer_date'] - df['order_purchase_timestamp']).dt.days
直方圖是觀察單一數值變數分佈的最常用工具。它會將數值的範圍切分成好幾個「區間 (bins)」,然後統計每個區間內有多少個數據點,並以長條圖的形式繪製出來。
比喻: 就像統計全班同學的身高分佈。我們會設定身高區間(150-155公分、155-160公分...),然後計算每個區間內有多少人。
商業問題: Olist 訂單的運送天數分佈是怎麼樣的?大部分訂單都集中在幾天內送達?
# 繪製直方圖前,先移除 delivery_days 中的缺失值 (NaN)
delivery_days_data = df['delivery_days'].dropna()
# 建立畫布
plt.figure(figsize=(12, 7))
# 繪製直方圖
# bins 參數決定了我們要將數據切分成多少個區間
plt.hist(delivery_days_data, bins=50, color='lightblue', edgecolor='black')
plt.title('Olist 訂單運送天數分佈直方圖', fontsize=16)
plt.xlabel('運送天數 (天)', fontsize=12)
plt.ylabel('訂單數量 (筆)', fontsize=12)
plt.show()
輸出結果: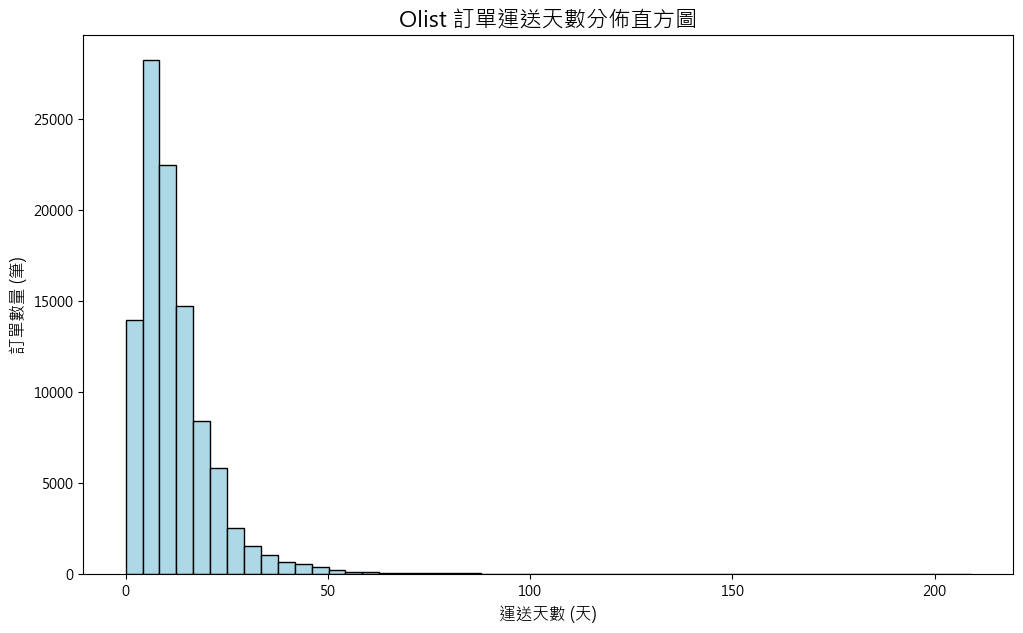
從圖中解讀:
我們可以非常清楚地看到,絕大多數訂單都集中在 0 到 25 天內送達,呈現一個「右偏」的分佈。同時,也存在一個「長長的尾巴」,代表有少數訂單花了非常長的時間(甚至超過 100 天)才送達——這些就是我們需要關注的「異常值 (Outliers)」。
如果說直方圖讓我們看到分佈的「形狀」,那箱線圖就是讓我們快速掌握分佈的**「統計摘要」**並揪出異常值的神器。
它主要由五個統計量組成:最小值、第一四分位數 (Q1)、中位數 (Median)、第三四分位數 (Q3)、最大值。
(圖說:箱線圖各部分的統計意義)
商業問題: Olist 訂單的支付金額 (payment_value) 分佈如何?是否存在一些金額極高的異常訂單?
# 準備支付金額數據
payment_data = df['payment_value'].dropna()
# 由於支付金額的分佈非常非常偏斜(少數極高價訂單),
# 為了讓圖表更易讀,我們先篩選掉大於 1000 的極端值來觀察主體分佈
payment_data_filtered = payment_data[payment_data < 1000]
# 建立畫布
plt.figure(figsize=(12, 4))
# 繪製箱線圖
# vert=False 讓箱子水平放置,更易於閱讀
plt.boxplot(payment_data_filtered, vert=False)
plt.title('Olist 訂單支付金額箱線圖 (金額 < 1000)', fontsize=16)
plt.xlabel('支付金額', fontsize=12)
plt.show()
輸出結果: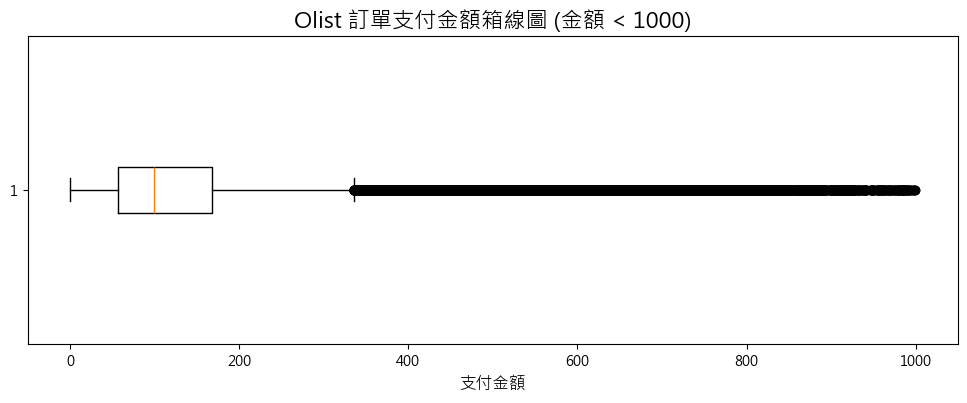
從圖中解讀:
箱子: 代表了 50% 的訂單金額所在的核心區間。
箱子中間的線: 代表了訂單金額的「中位數」。
箱子外的點: 這些就是被統計模型判定為「異常值」的訂單,它們的金額遠高於大部分的訂單。
今天我們學會了兩種探索數據分佈的強大視覺化工具。直方圖幫助我們看見數據的整體「形狀」與集中趨勢,而箱線圖則讓我們能快速地掌握數據的統計摘要並揪出潛在的異常值。這兩者都是進行探索性資料分析 (EDA) 時不可或缺的利器。
我們已經學會了如何分析單一變數。但數據分析更有趣的地方,在於探索不同變數之間的關聯。訂單金額和顧客評分有關嗎?商品重量和運費有關嗎?明天,Day 27,我們將學習如何用「散點圖 (Scatter Plot)」來回答這些問題,並初步認識一個更美觀的視覺化函式庫——Seaborn!

