大家好,歡迎來到數據新手村的第二十八天!在鐵人賽的最後幾天,將進入「專案實戰」階段。
今天,不再學習單一的函式或語法,而是要將過去幾週學到的所有技能——Pandas 的資料處理、時間序列分析、Group By 聚合以及 Matplotlib/Seaborn 的視覺化——全部整合起來,完成我們的第一個端到端 (End-to-End) 的迷你專案。
身為 Olist 平台的數據分析師,老闆給我們第一個任務:
「請分析我們平台從 2017 年到 2018 年的『整體月銷售額』趨勢,畫出圖表,並告訴我你的觀察與發現。」
為了回答這個問題,作戰計畫分為以下四步:
orders 和 payments 兩張表,並處理好時間欄位。第一步是準備好我們需要的乾淨資料。我們需要 orders 表中的下單時間 (order_purchase_timestamp) 和 payments 表中的支付金額 (payment_value)。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# --- 設定中文字體 ---
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei']
plt.rcParams['axes.unicode_minus'] = False
# --- 讀取與合併 ---
orders_df = pd.read_csv('../../data/olist_datasets/olist_orders_dataset.csv')
payments_df = pd.read_csv('../../data/olist_datasets/olist_order_payments_dataset.csv')
df = pd.merge(orders_df, payments_df, on='order_id', how='left')
# --- 清理與轉換 ---
# 1. 處理缺失值
df = df.dropna(subset=['order_purchase_timestamp', 'payment_value'])
# 2. 轉換時間欄位 (Day 20 的核心技巧)
df['order_purchase_timestamp'] = pd.to_datetime(df['order_purchase_timestamp'])
# 3. (新技巧!) 將時間設定為索引 (Index)
# 這麼做可以解鎖 Pandas 強大的時間序列分析能力
df.set_index('order_purchase_timestamp', inplace=True)
print("資料準備完成,並將時間設定為索引:")
df[['payment_value']].info()
輸出結果:
資料準備完成,並將時間設定為索引:
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 103886 entries, 2017-10-02 10:56:33 to 2018-03-08 20:57:30
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 payment_value 103886 non-null float64
dtypes: float64(1)
memory usage: 1.6 MB
我們現在擁有的是每一筆訂單的詳細時間。為了分析「月銷售額」,我們需要將這些數據按「月」來分組聚合。這時,Pandas 針對時間序列提供的專用 groupby——.resample() 方法就登場了!
.resample() 可以讓我們非常輕易地改變時間序列的「頻率」(例如,從每日數據變為每月數據)。
# 使用 .resample() 將數據按「月 (ME)」進行重採樣
# 'M' 代表 Month End frequency (月底頻率)
# 接著用 .sum() 告訴 resample 我們要計算每個月的「總和」
monthly_sales = df['payment_value'].resample('ME').sum()
print("按月聚合後的銷售數據 (前五筆):")
print(monthly_sales.head())
輸出結果:
按月聚合後的銷售數據 (前五筆):
order_purchase_timestamp
2016-09-30 252.24
2016-10-31 59090.48
2016-11-30 0.00
2016-12-31 19.62
2017-01-31 138488.04
Freq: ME, Name: payment_value, dtype: float64
數據聚合完成後,我們就可以用 Day 25 學到的技巧,將這個 monthly_sales Series 畫成折線圖。
plt.figure(figsize=(15, 7))
# Pandas DataFrame/Series 可以直接呼叫 .plot() 方法來繪圖
monthly_sales.plot(kind='line', marker='o', linestyle='-')
plt.title('Olist 平台月銷售額趨勢 (2016-2018)', fontsize=16)
plt.xlabel('日期', fontsize=12)
plt.ylabel('總銷售額', fontsize=12)
plt.grid(True) # 加上格線
plt.show()
輸出結果: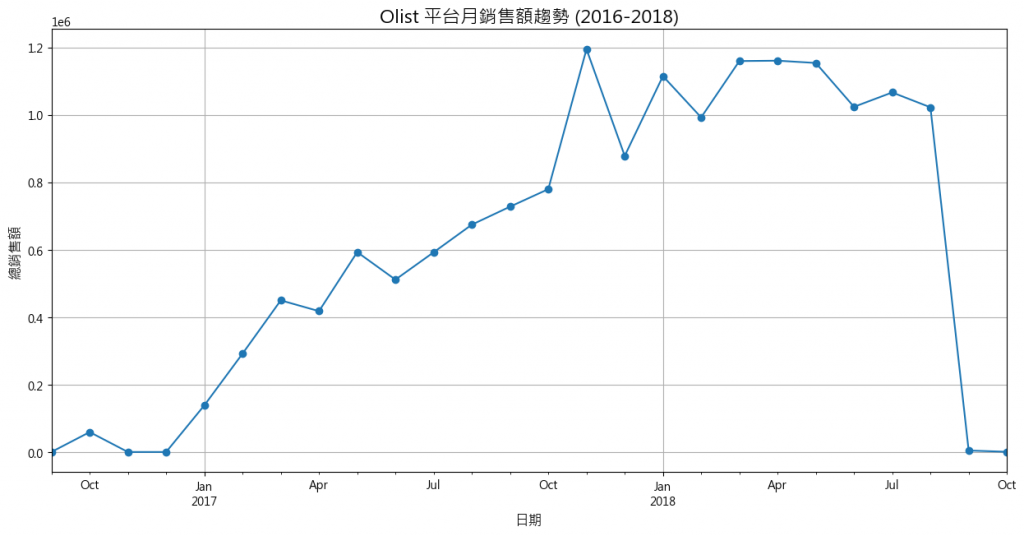
有了這張圖表,我們就可以自信地向老闆報告了:
從上圖中,我們可以清楚地觀察到幾個關鍵趨勢:
快速成長期 (2017): 整體來看,平台銷售額從 2017 年初到 2017 年底,呈現顯著的階梯式爆發成長,證明平台在該年度的商業策略非常成功。
季節性模式 (Seasonal Pattern): 我們可以看到一個清晰的季節性規律,每年年底(約 11 月)都是一個銷售高峰,這很可能與黑色星期五或聖誕節的購物季有關。
趨勢穩定與異常點 (2018): 進入 2018 年後,銷售額趨於穩定,但在年中之後似乎出現了數據下滑。(註:經過查證,Olist 公開數據集主要涵蓋到 2018 年 9 月,因此 9 月之後的數據不完整是正常現象,並非真實的業績衰退。)
今天,我們完成了第一個端到端的分析專案!從提出問題、準備數據、使用 .resample() 進行時間序列聚合,到最終的視覺化與洞察解讀,您已經完整地體驗了一次數據分析師的日常工作流程。
我們今天將分析結果呈現在圖表上,但這些寶貴的、經過清理與聚合的數據,應該如何被儲存起來以便未來重複使用呢?明天,Day 29,我們將回到數據的歸宿——將 Pandas 的分析成果存入 MySQL 資料庫,並學習用 SQL 進行驗證查詢,完成我們數據工作流的最後一塊拼圖!

