早安各位~ 今天要繼續講我們昨天提到的「斷詞」這個主題!
昨天我們大致介紹了斷詞的概念,也示範了如何使用 NLTK 套件來完成英文斷詞,並提到 NLTK 其實還有許多其他實用的功能,不知道大家自己在使用的時候有沒有發現其他酷東西🪄,有的話非常歡迎分享喔😇
那今天得重點會是跟大家展示怎麼樣用jieba 這個套件來處理中文斷詞,那就廢話不多說,直接開始把!
我們昨天其實有稍微提到,中文在斷詞上面會比英文來的要複雜許多,原因是因為 英文的單字之間有空格,詞跟詞之間有很明確的界線 但中文的詞並沒有一個很明確的邊界,舉例來說:我今天心情很好所以決定去散步。
電腦怎麼知道心情很好應該分成「心情」、「很好」,而不是「心」、「情很」、「好」,是一個非常有挑戰的任務,而jieba 就是其中一個廣被使用來完成這個任務的中文斷詞工具!那就來看看怎麼使用唄!
我們需要先安裝結巴
pip install jieba
安裝完後我們就可以來使用拉!
一樣我們用上面有舉到的句子當我們的範例
sentence = "我今天心情很好所以決定去散步"
對這個句子做一個簡單的斷詞可以用jieba.lcut
import jieba
words = jieba.lcut(sentence)
print (words)
輸出結果
['我', '今天', '心情', '很', '好', '所以', '決定', '去', '散步']
這邊的jieba.lcut() 預設使用「精確模式」,它會嘗試找出最合適的詞彙做切割,也有其他參數可以選擇
例如如果將參數cut_all() 設為True,代表的是全模式,這個模式的斷詞方式會將句子中所有可能的詞都切出來。
以剛剛的句子例子來說:
words = jieba.lcut(sentence, cut_all = True)
print(words)
會輸出
['我', '今天', '天心', '心情', '很', '好', '所以', '決', '定', '去', '散步']
另一個是jieba.lcut_for_search() ,他主要會分先做切詞後,再對長詞再做細分
words = jieba.lcut_for_search(sentence)
print(words)
輸出結果
['我', '今天', '心情', '很', '好', '所以', '決定', '去', '散步']
看起來貌似跟一般切法差不多xd 但大家可以自己試試其他句子看看差別!!
那我們可以來試試看一篇長的文章看看用jieba 看看他的整體短詞效果!
剛好最近颱風要來,截取一下yahoo 對颱風的一則小報導:
text = '氣象署今(22日)持續發布強烈颱風樺加沙海上、陸上颱風警報,8時的中心位置在北緯 19.3 度,東經 123.1 度,即在鵝鑾鼻的東南方約370 公里之處,以每小時20公里速度,向西轉西北西進行,暴風圈正逐漸進入台灣東南部近海,對台東、屏東、恆春半島及高雄已構成威脅,此颱風結構完整,未來強度仍有稍增強且暴風圈有稍擴大的趨勢。目前陸上警戒範圍維持高屏、台東地區。預估中午前暴風圈可能就會接觸恆春半島。氣象署表示,今天下半天到明天上半天是樺加沙颱風最接近我們的時候。'
使用最一般的方式斷詞:
words = jieba.lcut(text)
print(words)
['氣象署', '今', '(', '22', '日', ')', '持續', '發布', '強烈', '颱', '風樺', '加沙', '海上', '、', '陸上', '颱', '風警報', ',', '8', '時', '的', '中心', '位置', '在', '北緯', ' ', '19.3', ' ', '度', ',', '東經', ' ', '123.1', ' ', '度', ',', '即', '在', '鵝', '鑾', '鼻', '的', '東', '南方', '約', '370', ' ', '公里', '之處', ',', '以', '每小時', '20', '公里', '速度', ',', '向', '西轉', '西北', '西進行', ',', '暴風圈', '正', '逐漸', '進入', '台灣東', '南部', '近海', ',', '對', '台東', '、', '屏東', '、', '恆春半島', '及', '高雄', '已構', '成威脅', ',', '此', '颱', '風', '結構', '完整', ',', '未來', '強度', '仍', '有', '稍', '增強', '且', '暴風圈', '有', '稍', '擴大', '的', '趨勢', '。', '目前', '陸上', '警戒', '範圍', '維持', '高屏', '、', '台東', '地區', '。', '預估', '中午', '前暴', '風圈', '可能', '就會', '接觸', '恆春半島', '。', '氣象署', '表示', ',', '今天', '下', '半天', '到', '明天', '上半天', '是', '樺', '加沙', '颱', '風', '最', '接近', '我們', '的', '時候', '。', "'", '\n']
看起來斷的還不錯,但有沒有發現有一些專有名詞像是「颱風」、「樺加沙」、「鵝鑾鼻」、「台灣」他沒辨法斷的很完全,這也是常常在處理資料的時候我們會需要處理得一環!
通常遇到這種狀況我們會自己建立一個「字典」,告訴結巴說,這個詞應該要怎麼斷
那實際操作的步驟也很簡單!
首先你要先建立一個txt 檔,這個檔案裡面放的是你要斷詞的詞的樣子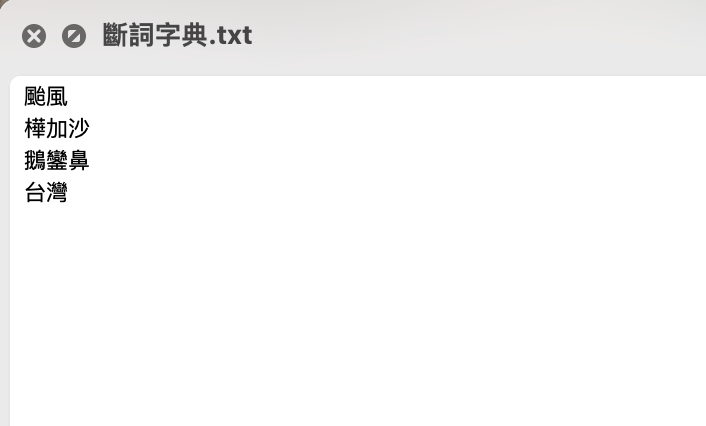
然後用load_userdict()把他引入進來
jieba.load_userdict("/Users/xxuan/Desktop/斷詞字典.txt")
這邊
jieba.load_userdict()裡面放的東西是你的檔案位置喔!如果不知道怎麼看檔案位置可以去看我這一篇:Day 3 疑?我的檔案在哪?搞資料前搞清楚讀檔&檔案位置!
用這樣的方式,這些你自己定義的斷詞樣子就會被寫進結巴裡面嚕!
可以再試試看印出來的結果:
words = jieba.lcut(text)
print(words)
輸出結果
['氣象署', '今', '(', '22', '日', ')', '持續', '發布', '強烈', '颱風', '樺加沙', '海上', '、', '陸上', '颱風', '警報', ',', '8', '時', '的', '中心', '位置', '在', '北緯', ' ', '19.3', ' ', '度', ',', '東經', ' ', '123.1', ' ', '度', ',', '即', '在', '鵝鑾鼻', '的', '東', '南方', '約', '370', ' ', '公里', '之處', ',', '以', '每小時', '20', '公里', '速度', ',', '向', '西轉', '西北', '西進行', ',', '暴風圈', '正', '逐漸', '進入', '台灣', '東', '南部', '近海', ',', '對', '台東', '、', '屏東', '、', '恆春半島', '及', '高雄', '已構', '成威脅', ',', '此', '颱風', '結構', '完整', ',', '未來', '強度', '仍', '有', '稍', '增強', '且', '暴風圈', '有', '稍', '擴大', '的', '趨勢', '。', '目前', '陸上', '警戒', '範圍', '維持', '高屏', '、', '台東', '地區', '。', '預估', '中午', '前暴', '風圈', '可能', '就會', '接觸', '恆春半島', '。', '氣象署', '表示', ',', '今天', '下', '半天', '到', '明天', '上半天', '是', '樺加沙', '颱風', '最', '接近', '我們', '的', '時候', '。', "'", '\n']
嘿嘿~ 有沒有看到,一些專有名詞就被斷的乾乾淨淨拉~!
這時候你可能會覺得我的資料好像還是髒髒的,很多不必要的標點符號,或是有一些沒有意義的詞,這些我們在處理的時候會稱作他們是停止詞(stop words),一般我們也會優先排除這些詞才繼續做後續的任務,明天我們會來跟大家詳細介紹一番停止詞!今天就先到這裡就好~ 怕大家承受不住xd
好拉 明天見!


 iThome鐵人賽
iThome鐵人賽