
在前篇,我們發現了資料庫的物理極限:磁碟 I/O 的 15-50 微秒延遲,在高併發熱點寫入場景下,成為了不可逾越的牆。
資料庫為了履行其 ACID 中「持久性 (Durability)」的承諾,每一次寫入都必須與相對緩慢的磁碟互動,這道牆,我們在原有的戰場上無法逾越。
因此,今天我們的任務不是小幅修改,而是改變戰場。
我們要引入一個新盟友:Redis。
Redis 是此刻的最佳選擇,除了它之所以快,也要深入理解來構成它高效能的三大原因:記憶體儲存、單執行緒模型、原子指令。
與以磁碟為主要儲存介質的傳統資料庫不同,Redis 選擇將所有資料都存放在記憶體中。
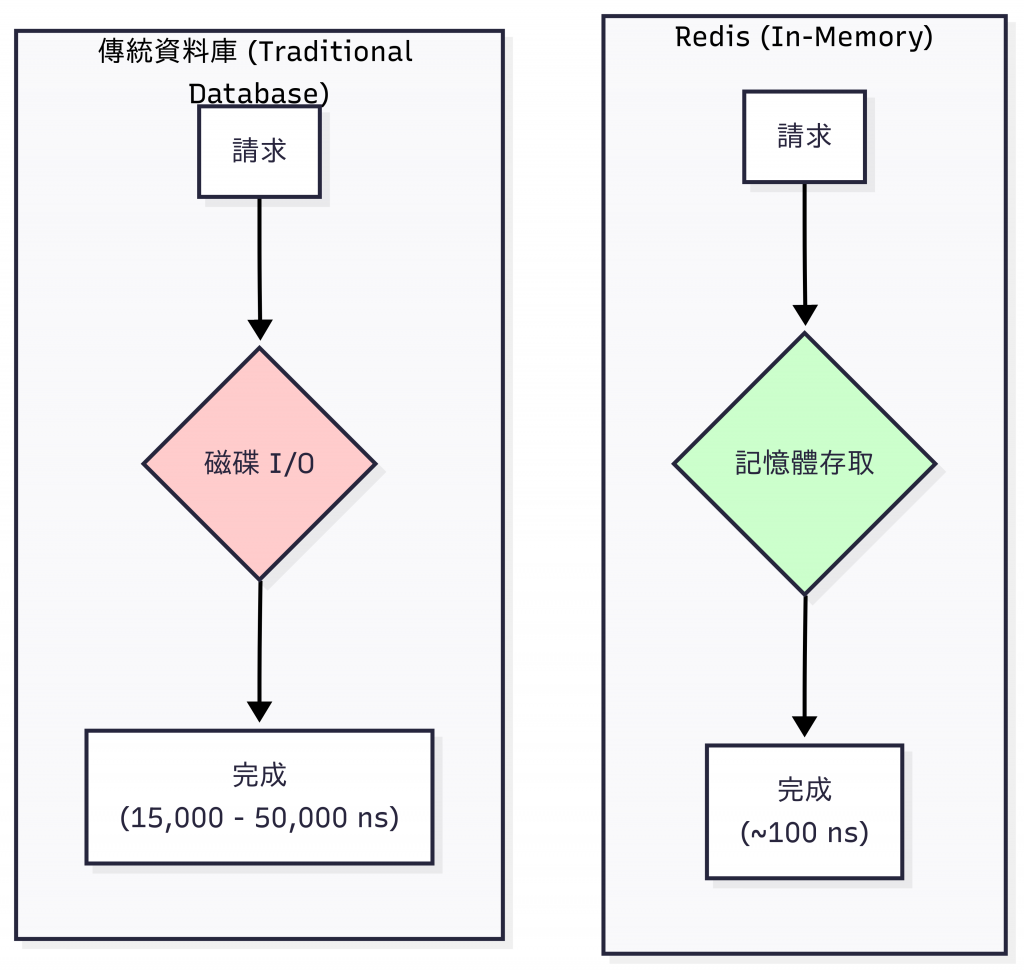
我們再來回顧一下延遲的數量級差異:
記憶體存取:約 100 奈秒
SSD 磁碟存取:約 15,000 - 50,000 奈秒
當你的資料在記憶體中時,每次存取只需要 100 奈秒,而不是 15,000 奈秒。
這是 150 倍的速度提升,而且這個提升是物理定律保證的,不是靠優化演算法能達到的。
當搶票系統每秒需要處理成千上萬次庫存查詢與扣減時,將熱點資料(票券庫存)放在記憶體中,是突破效能瓶頸的必然選擇。
當然,將資料放在記憶體中也意味著斷電後資料會遺失。雖然 Redis 提供了 RDB 和 AOF 兩種持久化機制來盡力保存資料,但它的核心價值始終是高速的讀寫,而非絕對的資料安全。
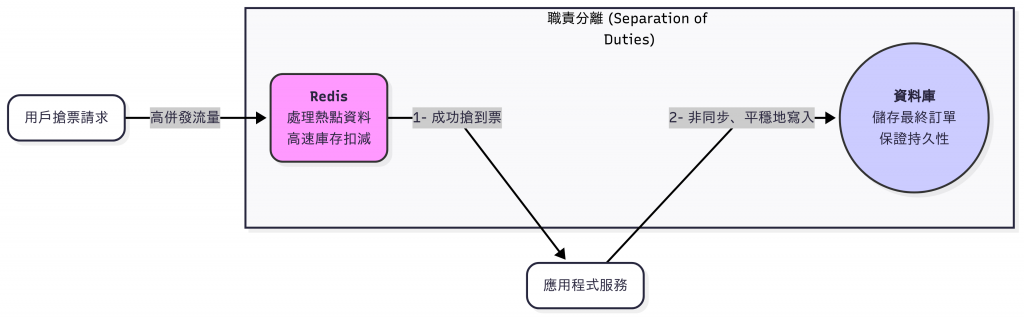
這也促使我們進行架構上的職責分離:
Redis:負責處理高併發的即時庫存扣減,保證速度和原子性。
資料庫:負責訂單資料的最終持久化,保證交易的可靠性和一致性。
我們用 Redis 來擋住高併發的洪峰,再將成功搶到的訂單資訊,非同步地、平穩地寫入後端資料庫。
在傳統的多執行緒資料庫中,為了處理併發請求,你需要:
這些都是為了處理「多個執行緒同時修改同一份資料」這個特殊情況而產生的複雜性。
Redis 的解決方案是什麼?根本不要讓這種情況發生。
它還採用 單執行緒事件迴圈 (Single-threaded Event Loop) 模型:
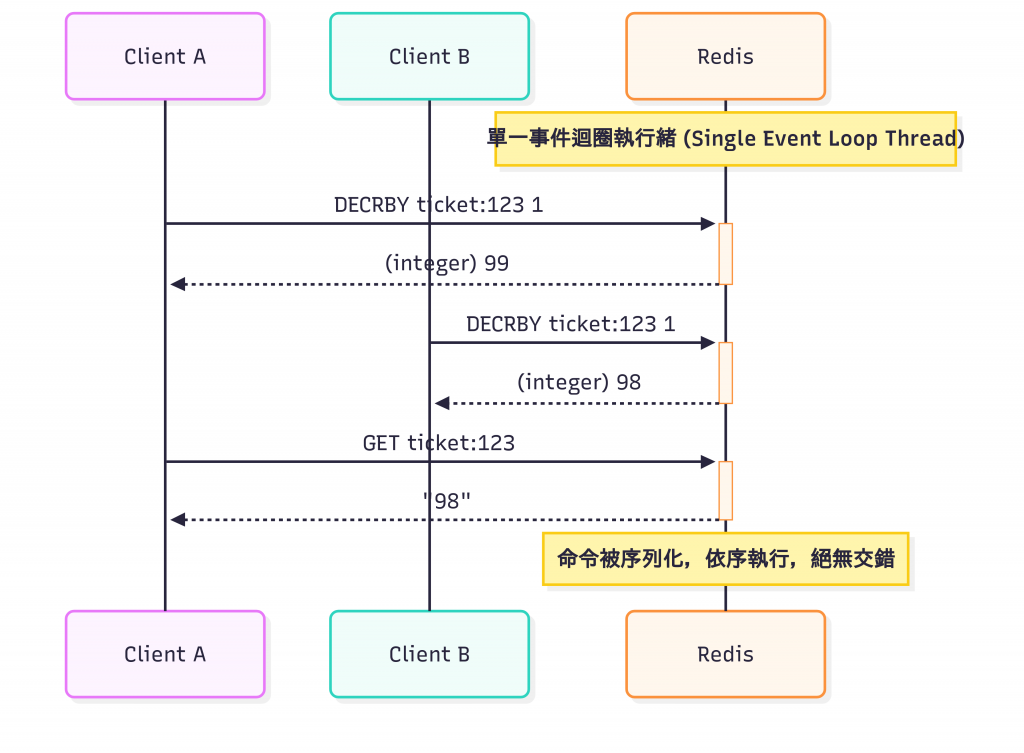
在 Redis 中,所有來自客戶端的命令都會進入一個佇列,由單一執行緒依序取出並執行。在任何一個時間點,都只有一個命令正在被處理。
這帶來的好處是巨大的:
天然的原子性:由於不存在併發,單個命令的執行過程絕不會被其他命令打斷。
無鎖競爭開銷:從根本上消除了多執行緒環境下鎖的建立、等待和釋放所帶來的效能損耗。
它帶來了無鎖的簡潔與高效,但也要求開發者遵守紀律:絕不能執行慢指令。
如果一個指令(KEYS *、SMEMBERS 操作一個巨大的集合)執行時間過長,它會阻塞後續所有的命令,導致整個 Redis 服務停頓。
Redis 相信你會善用它,只執行那些時間複雜度為 O(1) 或 O(logn) 的高效指令。在我們的搶票場景中,所有操作都是這類快指令。
在資料庫的世界裡,這需要:
而在 Redis 中,這只需要一個命令:
DECRBY ticket:123 1
這個 DECRBY 指令的執行過程:
找到 ticket:123 這個 key。
將其值減 1。
返回減完之後的新值。
這三個步驟在 Redis 內部是一氣呵成的,是不可分割的原子操作。
它解決了我們的主要訴求:高效、原子地扣減庫存,並且絕不超賣。
Redis 提供了一系列專為計數器場景設計的原子指令:
# 基本計數操作
INCR key # 原子性 +1
DECR key # 原子性 -1
INCRBY key 5 # 原子性 +5
DECRBY key 3 # 原子性 -3
# 條件計數操作
INCRBY key 1 # 回傳更新後的值,可用於判斷
Redis 提供兩種持久化選項:
但對於搶票場景,我們需要的是:
Redis 負責前者,資料庫負責後者。
這不是 Redis 的缺陷,這是職責分離。
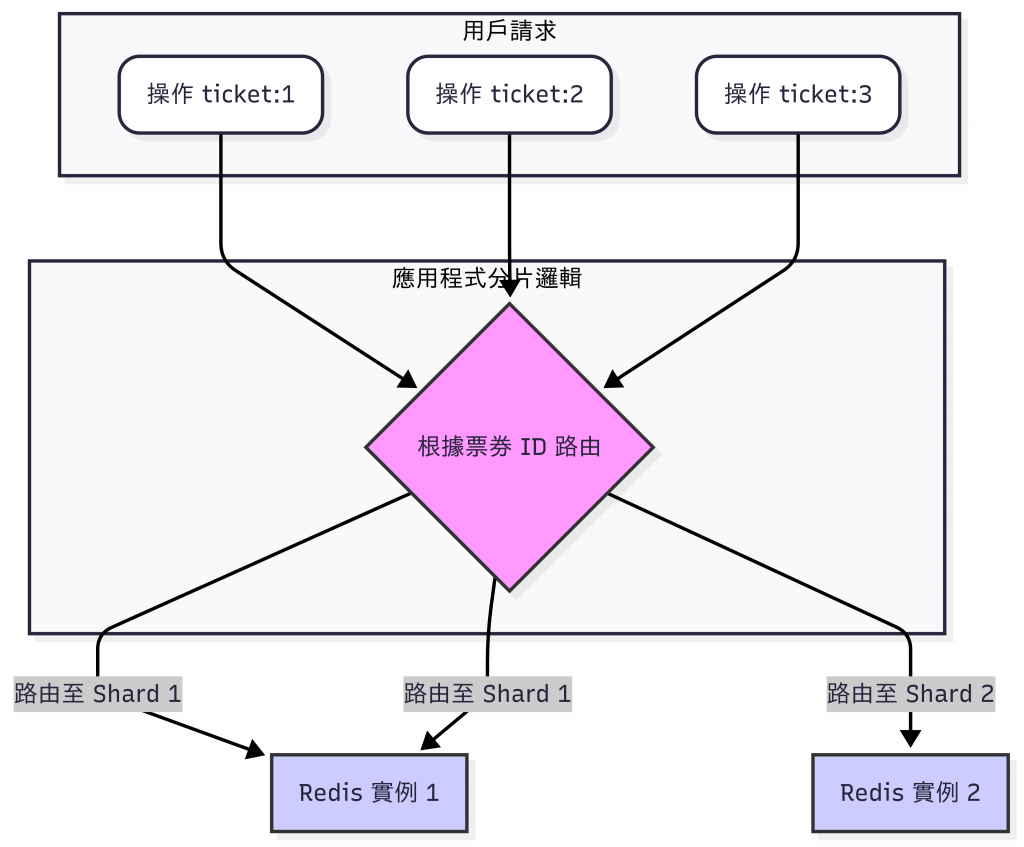
當單一 Redis 實例無法承載流量時,我們可以透過分片來水平擴展:
# 基於票券 ID 的分片策略
ticket:1 -> Redis Instance 1
ticket:2 -> Redis Instance 2
ticket:3 -> Redis Instance 1
ticket:4 -> Redis Instance 2
這種分片策略確保:
記憶體儲存:速度是磁碟的數百倍,從物理層面提升效能。
單執行緒模型:依序處理命令,根本上避免了複雜的鎖競爭問題。
原子指令:使用 DECRBY 等指令,確保庫存扣減這類操作單一、不可分割,保證了資料在高併發下的一致性(不會超賣)。

