Groupby是資料分析中最基本的工作,先將資料分組再做統計運算。這種機制存在已久,稱為split-apply-combine,也就是把資料按鍵分組 (Split) → 對每組套函數 (Apply) → 合併結果 (Combine)。譬如統計薪水時,一般以年齡段分區的薪水中位數,再上其他特徵資料,畢竟光是一個全台灣的薪水的中位數可能以資料來說沒太多價值。
這是一個常用到到必須上手的功能,好家在熊貓師父依然強大,把這些以前用程式兜到大腦膨脹的邏輯做的極好上手,有多好上手呢,我們開始吧。
語法可以是下面兩種形式
DataFrame.groupby("分組欄位").agg({"被運算欄位": "聚合函數"})
DataFrame.groupby("分組欄位")["被運算欄位"].agg("聚合函數")
以上usage是單一分組、單一欄位、單一聚合運算,但是要多重在pandas也是易如反掌
直接來看程式。
#這兩個一樣
flys.groupby("LINE").agg({"DELAY":"sum"})
flys.groupby("LINE")["DELAY"].agg("sum")
#獲得多個聚合函數結果
flys.groupby("LINE").agg({"DELAY":["sum","min", "max"]})
flys.groupby("LINE")["DELAY"].agg(["sum", "min", "max"])
#多個分組欄位
flys.groupby(["LINE","WEEKDAY"]).agg({"DELAY":"sum"})
flys.groupby(["LINE","WEEKDAY"])["DELAY"].agg("sum")
#多個運算欄位
flys.groupby("LINE").agg({"CANCELLED":"sum", "DIVERTED":"sum"})
flys.groupby("LINE")[["CANCELLED","DIVERTED"]].agg("sum")
#全部加滿,有換行的記得用大括號包起來
(flys.groupby(["LINE","WEEKDAY"]).agg({"CANCELLED":["sum", "mean", "max", "min"],
"DIVERTED":["sum", "mean", "max", "min"]}))
(flys.groupby(["LINE","WEEKDAY"])[["CANCELLED","DIVERTED"]]
.agg(["sum", "mean", "max", "min"]))
執行最後的groupby會是這樣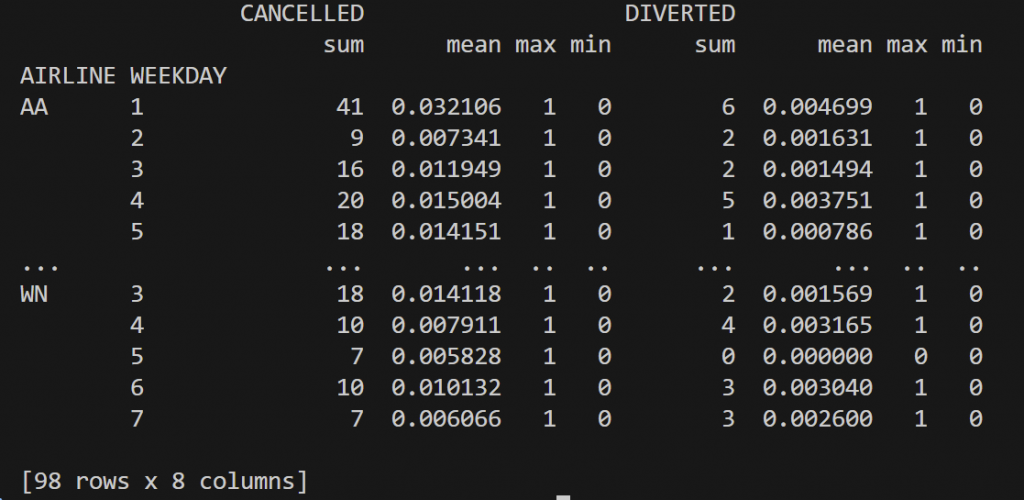
是不是
GroupBy物件提供了很多實用的方法,即使不做聚合函數,要取得分組資訊也很方便。grouped = flys.groupby(["LINE","WEEKDAY"])
dataframe點完groupby欄位後,什麼都不要加就能得到一個GroupBy object。
grouped.ngroups
list(grouped.groups)
grouped.get_group(('GroupColumn1','GroupColumn2'))
#要先import: from IPython.display import display
for name, group in grouped:
print(name)
display(group.head(3))
grouped.nth(n, dropna=None)
明天繼續groupby的旅程。

